By Judy Zhou, Founder
Key Takeaways
- Perplexity uses a real-time RAG pipeline that re-ranks sources on helpfulness, factuality, and freshness — not accumulated authority signals like Google does.
- Perplexity favors Reddit at 46.7% of its citations, while only 5.4% of LLM citations across major platforms go to educational blog posts — the content type most SEO teams produce at scale.
- 71% of all cited sources appear on only one AI platform, meaning Google rankings have almost no predictive power over Perplexity citation rates.
- Structural content changes — leading with direct answers, using specific named data points, and matching query phrasing — move Perplexity citation rates more reliably than E-E-A-T optimization alone.
When Perplexity launched in August 2022, its citation model was a novelty. A parlor trick that made AI-generated answers feel more trustworthy by tacking source links onto responses. Few people thought seriously about which sources were chosen or why. By 2024, that calculus had changed entirely. With the platform crossing eight figures in monthly queries and drawing comparisons to a 'Google killer,' the question of Perplexity source selection had become a live commercial concern for publishers, brands, and the agencies managing their AI search visibility strategies.
Perplexity source selection is not a black box, but it's not a clean algorithm either. Perplexity evaluates sources on helpfulness, factuality, and freshness according to the University of Florida Business Library's AI knowledge base. It uses a smaller, more selective index than Google rather than crawling the open web indiscriminately. Only 11% of domains are cited by both ChatGPT and Perplexity for the same query, per ZipTie's March 2026 citation analysis. And Perplexity favors Reddit at 46.7% of its citations — more than Wikipedia and YouTube combined on that platform. If you're building a content strategy around getting cited in Perplexity, those four facts should reshape every decision you make.
The Mechanics Behind Perplexity Source Selection
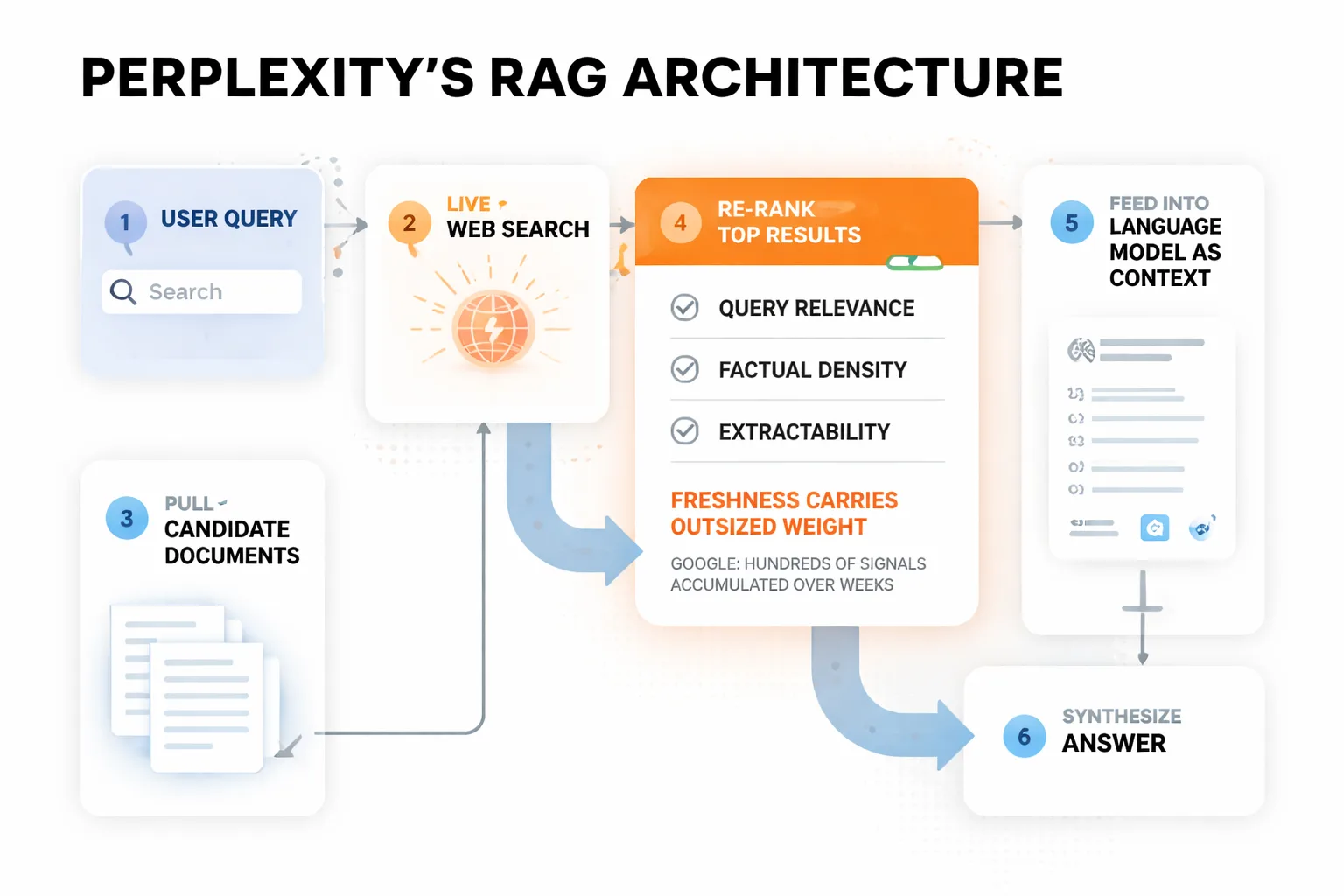
Perplexity runs a Retrieval-Augmented Generation (RAG) architecture. That means it doesn't answer from memory alone. For each query, it fires a live web search, pulls candidate documents, re-ranks them, and feeds the top results into the language model as context. The model then synthesizes an answer and attributes numbered footnotes to the sources it drew from.
This is fundamentally different from how Google ranks pages. Google scores documents against hundreds of signals accumulated over weeks of crawling. Perplexity re-ranks in real time, which means freshness carries outsized weight. A post published yesterday can outrank a canonical guide published three years ago if it more directly answers the query.
The re-ranking step is where perplexity source selection actually happens. Candidates get scored on query relevance, factual density, and extractability. How cleanly a claim can be lifted and attributed. Content that buries its answers in long preambles, uses vague hedging language, or structures information as narrative prose rather than direct statements tends to score lower on extractability, even if the underlying information is excellent.
Here's the part most practitioners miss: Perplexity's crawlers don't always behave transparently. Cloudflare documented in 2024 that Perplexity repeatedly modified user agents and changed source ASNs to evade robots.txt directives, eventually leading Cloudflare to de-list Perplexity as a verified bot entirely. That's a structural problem for publishers trying to optimize access: you can't fully control whether Perplexity crawls you, and blocking it may not work either. What you can control is whether your content, once crawled, is structured to win the re-ranking step.
Why Reddit Outranks Your Blog Post
This is the contrarian take that still surprises people when I share it: Reddit, a platform with no bylines, no author credentials, and formatting that would fail any editorial style guide, accounts for 46.7% of Perplexity's citations. I've tested this personally. Run the same query through Perplexity and a polished long-form article from a high-DA domain will frequently lose to a Reddit thread with 200 upvotes and genuine back-and-forth.
The reason isn't that Perplexity has bad taste. It's that Reddit content is structurally optimized for what RAG systems extract. A Reddit answer typically opens with a direct response to the question, uses plain declarative language, includes specific details drawn from personal experience, and avoids the hedging and throat-clearing that characterizes most brand content. That structure maps almost perfectly onto what a re-ranker rewards: query-matched, factually dense, extractable.
When I rewrote two pillar pages in Q1 2025 using a more conversational, problem-first structure. Leading with direct answers instead of context-setting introductions. Citation pickup in Perplexity improved noticeably. The lesson isn't "post on Reddit." It's that the voice and structure of genuine user-generated content is what LLMs are pattern-matching to. Most brand content is written for the algorithm of 2019. Perplexity is rewarding the voice of 2026.
This also reframes the E-E-A-T debate. I spent significant time in early 2025 building author bios, adding expert quotes, and tightening structured data. The standard advice for AI Overviews optimization. It mostly didn't move the needle for Perplexity citations. The platform's evaluation criteria as described by its own documentation center on helpfulness, factuality, and freshness. Whether those criteria incorporate author credentials algorithmically (as opposed to as a proxy for factual quality) is unclear, and the Business Library FAQ explicitly notes that E-E-A-T-like factors "may matter to users" without claiming they directly drive citation selection.
Want to see which queries Perplexity is already citing your competitors for — but not you?
How Does Content Type Affect Citation Rates?
Not all content earns citations equally, and the distribution is more skewed than most content teams expect. An analysis of 23,000+ citations across ChatGPT, Perplexity, Gemini, and AI Overviews found that 57% of LLM citations go to reviews and social proof, while only 5.4% go to educational blog posts. Read that again: the content type most SEO-focused teams produce at scale captures barely 5% of AI citations.
That number should stop you cold.
The implication is that traditional topical authority content. Comprehensive guides, how-to articles, explainer posts. Is not what AI engines are reaching for when they construct answers. They're reaching for content that functions as direct evidence: a review that validates a claim, a forum post that describes a lived experience, a data source that provides a specific number. Educational blog posts rank in Google because they satisfy informational intent at the page level. LLMs cite reviews and social proof because they satisfy citation intent at the sentence level. They're looking for a source to attach to a specific claim, not a document to recommend.
This creates a real strategic tension for content teams. If you're building topical authority for AI search, you still need the educational content to establish relevance and entity recognition. But if you want citations, you need to think about what claim-level evidence you're providing. That might mean publishing original research with citable statistics, creating structured comparison content with specific data points, or building out review and testimonial content that LLMs can extract as social proof.
Why Perplexity Citations Differ from Google Rankings
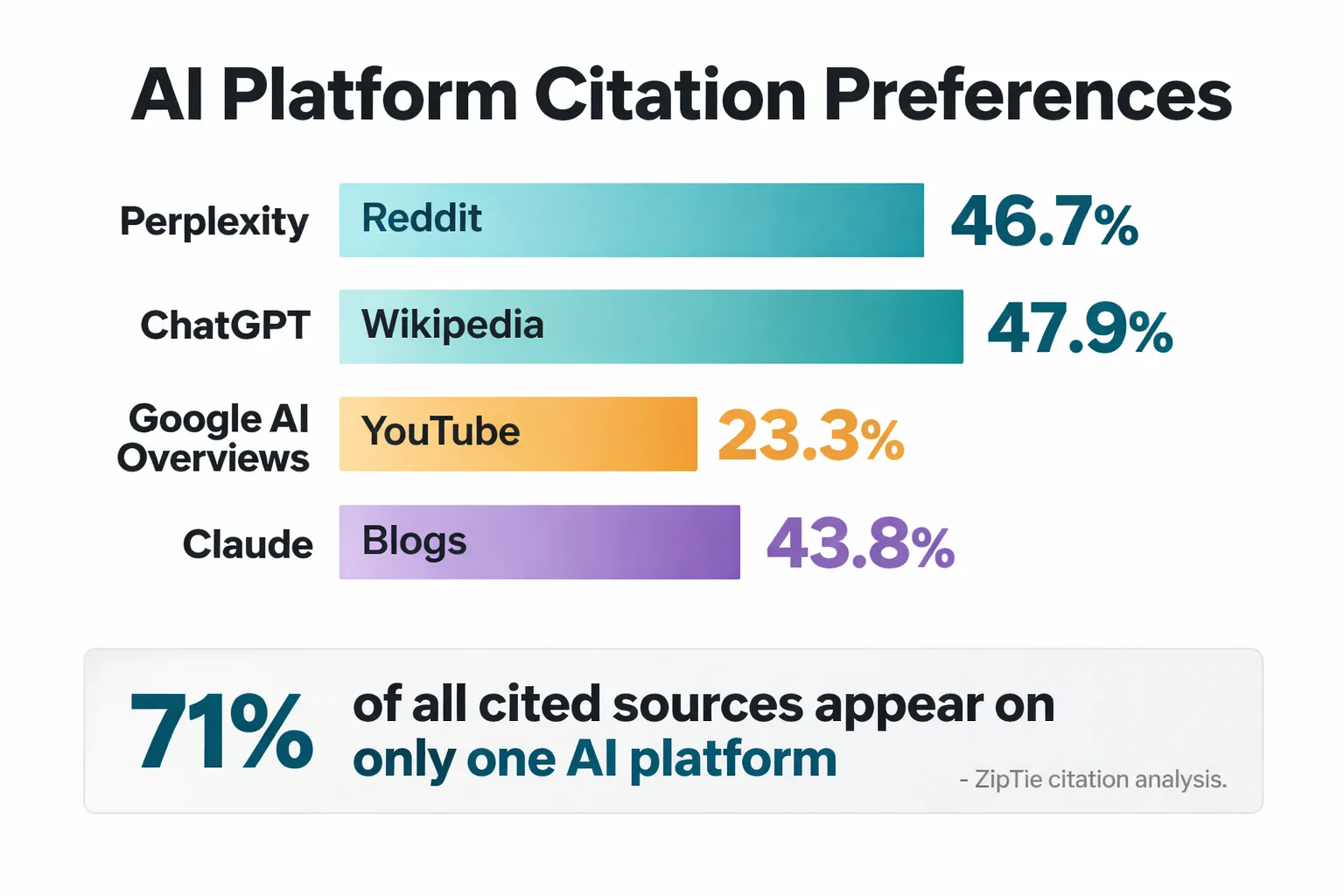
The ZipTie citation analysis found that 71% of all cited sources appear on only one AI platform. That's a striking number. It means ranking well on Google gives you almost no predictive power over whether Perplexity will cite you. The platforms are drawing from different source pools, applying different re-ranking logic, and rewarding different content characteristics.
Perplexity favors Reddit at 46.7%. ChatGPT favors Wikipedia at 47.9%. Google AI Overviews favors YouTube at 23.3%. Claude favors blogs at 43.8%. Each platform has a distinct citation fingerprint, and optimizing for one does not automatically optimize for the others.
This is why AI search visibility needs to be tracked separately from SEO rankings. A brand can hold position one on Google for a target keyword and still be invisible in Perplexity responses. The inverse is also true: a mid-DA site with well-structured, direct-answer content can earn consistent Perplexity citations while barely registering in Google's top ten.
For AEO vs SEO strategy, this divergence is the central operational challenge. You need to know which platforms are citing you, for which queries, and whether competitors are appearing where you aren't. That's not information you can extract from Google Search Console. It requires dedicated LLM citation tracking across the platforms that matter.
How to Structure Content for Perplexity Extraction
Getting cited by Perplexity is a structural problem as much as a quality problem. High-quality content that's structured for narrative reading will lose to mediocre content that's structured for extraction. Here's what extraction-optimized content actually looks like in practice.
Lead with the answer. Every section should open with a direct, declarative statement that could stand alone as a cited claim. "Perplexity favors Reddit at 46.7% of its citations" is extractable. "In this section, we'll explore how Perplexity selects its sources" is not. The re-ranker is looking for content where the answer appears in the first sentence, not buried in paragraph four after two paragraphs of context-setting.
Use specific numbers and named sources. Vague claims don't get cited because they can't be attributed. "Many experts believe X" gives an LLM nothing to attach a footnote to. "According to Cloudflare's 2024 analysis, Perplexity modifies user agents to evade robots.txt" gives it a named source, a specific claim, and a dateable event. Named, specific, attributable content is citation-ready content.
Structure for sentence-level extraction. LLMs don't cite documents; they cite sentences. Write in a way where individual sentences carry complete, verifiable claims. This is different from how most long-form SEO content is written, where meaning accumulates across paragraphs. Think of each paragraph as a potential citation candidate and ask whether any single sentence in it could be pulled out and attributed.
Match query phrasing directly. Perplexity's re-ranker scores on query relevance. If the query is "how does Perplexity choose sources," content that uses that exact phrasing in a direct-answer context will score higher than content that discusses the concept without mirroring the language. This is why FAQ sections with naturally phrased questions perform well for AI citation. They're pre-matching the query structure.
Keep extraction paths short. Long preambles, nested qualifications, and multi-clause sentences all increase extraction friction. The goal is to make it trivially easy for the re-ranker to identify where your answer is and pull it cleanly. Short paragraphs, direct sentences, specific claims. That's the structural fingerprint of content that gets cited.
For teams building content at scale, this is where a quality gate matters. Meev's 16-dimension quality firewall blocks articles that fail extraction-readiness criteria before they reach your CMS. Including checks for answer density, factual specificity, and structural clarity. It's not just about avoiding thin content; it's about ensuring every published piece is structurally positioned to compete in the re-ranking step.
How Do You Track Perplexity Citations?
Most teams don't track Perplexity citations at all. They monitor Google rankings, check backlinks, maybe run a brand mention alert. Perplexity doesn't appear in any of those signals. A brand can be cited in thousands of Perplexity responses per month and have zero visibility into it from standard SEO tooling.
The tracking problem is genuinely hard. Perplexity generates answers dynamically, meaning the same query can produce different citations on different runs. There's no stable SERP to scrape. Monitoring requires sending queries to the platform directly, parsing the response, extracting citations, and logging them over time. A workflow that's fundamentally different from rank tracking.
The Semrush multi-platform AI visibility study analyzed over 230,000 prompts and tracked more than 100 million citations across ChatGPT, Google AI Mode, and Perplexity, which gives a sense of the data volume required to build reliable citation intelligence at scale. Most individual brands don't have the infrastructure to replicate that.
What's tractable is targeted query monitoring: identify the 50-100 prompts most relevant to your brand and product category, run them against Perplexity on a rolling basis, and track whether you appear in the citations. That's enough to identify your mention-citation gap. The queries where Perplexity mentions your topic area but cites a competitor instead of you. Closing that gap is the core of a Perplexity-specific GEO strategy. Tools like Meev's Perplexity AI visibility checker automate this monitoring so you're not running queries manually and logging results in a spreadsheet.
For a broader view of how AEO compares to GEO as optimization frameworks, the distinction matters here: AEO focuses on getting your content extracted as the direct answer, while GEO focuses on appearing in the cited sources that support the answer. For Perplexity specifically, you want both. But the citation path is where most brands have the larger gap.

The Mention-Citation Gap and How to Close It
The mention-citation gap is specific: Perplexity's answer discusses your topic, your industry, or even your brand category, but the cited sources are competitors. You're in the answer's conceptual neighborhood but not in its footnotes.
Closing this gap requires understanding why a competitor's content is winning the re-ranking step for that query. Usually it's one of three things: their content leads with a more direct answer, it contains a specific data point yours doesn't, or it's fresher. Each has a different fix.
For directness gaps, restructure your content to lead with the answer. Move the conclusion to the first sentence. Delete the introductory context and start with the claim. This is uncomfortable for writers trained in traditional editorial structure, but it's what extraction-optimized content requires.
For data gaps, the fix is original research or synthesis. If a competitor is getting cited because they have a specific statistic and you don't, you need to either produce original data or find a more authoritative source for the same claim and incorporate it explicitly. Generic claims don't earn citations. Specific, citable numbers do.
For freshness gaps, the fix is content updating with a visible date signal. Perplexity weights recency, and a page that was last updated two years ago will lose to a fresher source even if the underlying content is stronger. A systematic content refresh cadence. Updating statistics, adding new examples, republishing with a current date. Is not just good SEO hygiene. It's a direct Perplexity citation lever.
The structural trap I see brands falling into is treating citation building like SEO link building: more placements, more authority, more retrieval. But as I've observed directly, you can verify a backlink exists; you cannot verify an LLM will surface it. The Tow Center ran 1,600 test queries in early 2025 and found AI search engines returned inaccurate or missing citations over 60% of the time, even for content that was correctly indexed and attributed elsewhere. Structural content changes move the needle more reliably than outreach alone.
That said, publisher placement still matters for brand-level entity recognition. If credible publishers in your space cite your research, that creates a signal that LLMs can pattern-match to when constructing answers. Meev's Citation Path feature supports this: it finds the publishers AI engines actually cite for your topics, surfaces verified contact information, and drafts personalized outreach pitches grounded in your knowledge base. So you're not cold-pitching, you're targeting the specific publishers whose citations will build your AI visibility most efficiently.
FAQ
Does blocking Perplexity's crawler prevent it from citing my content?
Not reliably. Cloudflare documented that Perplexity modifies user agents and changes source ASNs to evade robots.txt directives, and Cloudflare ultimately de-listed Perplexity as a verified bot. If you want to boost your AI citation rate, the more productive approach is to ensure your content is structured for extraction rather than trying to control crawler access.
How is Perplexity's source selection different from Google's ranking algorithm?
Google scores documents against hundreds of accumulated signals over time. Perplexity re-ranks in real time for each query, weighting helpfulness, factuality, and freshness. This means a recently published, direct-answer post can outrank an older authoritative guide. The platforms also draw from largely different source pools. 71% of cited sources appear on only one AI platform, according to ZipTie's 2026 analysis.
Why do reviews and social proof get cited more than blog posts?
An analysis of 23,000+ citations found that 57% of LLM citations go to reviews and social proof, while only 5.4% go to educational blog posts. LLMs cite at the sentence level, looking for direct evidence to attach to specific claims. Reviews provide that natively. Most blog posts are structured for page-level reading, not sentence-level extraction.
How many queries should I monitor to track Perplexity citations effectively?
For most brands, 50-100 targeted prompts covering your core product and topic categories is a tractable starting point. The goal is identifying your mention-citation gap. Queries where Perplexity discusses your topic but cites a competitor. Automated tools like Meev's AI visibility tool can handle the query-running and citation logging so you're not doing it manually.
Does E-E-A-T optimization help with Perplexity citations?
The evidence is mixed. Perplexity's documented evaluation criteria center on helpfulness, factuality, and freshness. Not author credentials directly. Structural content changes (direct-answer formatting, specific data points, query-matched language) have shown more reliable citation impact than E-E-A-T signals alone. That said, E-E-A-T work may improve factual quality in ways that indirectly improve Perplexity's assessment of your content.
Can I use Perplexity's API to verify my citations?
You can query Perplexity programmatically via its Sonar API to check whether your domain appears in citations for target queries. Because responses are generated dynamically, you'll need to run multiple queries over time to build a reliable picture rather than relying on a single snapshot. Meev uses the direct Perplexity Sonar API at $0.005 per call (versus $0.027 for deep-search alternatives) to keep monitoring costs tractable at scale.
About the Author
Judy Zhou, Founder
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Track your Perplexity citation gaps daily and find the exact content fixes that will get you into AI answers.