
By Judy Zhou, Head of Content Strategy
Key Takeaways
- Only 11% of domains are cited by both ChatGPT and Perplexity, meaning winning on one platform gives you almost no advantage on the other — you need separate citation strategies.
- The arXiv GEO research found AI search engines show systematic bias toward earned, third-party media over brand-owned content, making publisher placements more valuable than self-published articles for citation building.
- The mention-citation gap is the core diagnostic: if your brand is mentioned but not cited, you have a content structure problem; if you're neither mentioned nor cited, you have a topical authority problem — and the fixes are different.
- At 67% AI-generated content contamination in a retrieval pool, exposure contamination exceeds 80%, meaning publishing at scale without a quality gate actively degrades your own citation prospects.
Marcus had published over 400 articles in eighteen months. His team was consistent, his topics were relevant, and his traffic from Google had plateaued. But that wasn't what kept him up at night. What bothered him was opening Perplexity, typing a question squarely in his niche, and watching the AI cite three competitors he'd never heard of, back to back, with zero mention of his brand. He wasn't invisible to search engines. He was invisible to the thing that was replacing them.
If you're working on how to boost AI citation for your brand, the first thing to understand is that citation isn't a byproduct of ranking. It's a separate signal system, and most content teams haven't built for it yet. The arXiv GEO research found AI search exhibits "systematic and overwhelming bias towards Earned media" over brand-owned content. An analysis of 680 million AI citations found only 11% of domains were cited by both ChatGPT and Perplexity, meaning visibility on one platform does not transfer to the other. Retrieval collapse research showed that 67% pool contamination from AI-generated content led to over 80% exposure contamination in search results, squeezing out legitimate sources. And the mention-citation gap. The distance between a brand being referenced and a brand being sourced. Is wider than most teams realize.
Why Most Brands Have a Mention-Citation Gap
The mention-citation gap is the most underdiagnosed problem in AI search visibility right now. A brand gets mentioned when an AI answer references it by name. A brand gets cited when the AI engine links back to a specific piece of content as its source. These are not the same thing, and the gap between them is where most content investments quietly disappear.
Here's the mechanic behind it. AI engines like Perplexity and ChatGPT pull from two layers: training data (what the model learned before its cutoff) and retrieval (what it fetches live to answer specific queries). Mentions tend to come from training data. Citations tend to come from retrieval. If your content isn't structured to be retrieved. Clear entity signals, specific answers to specific query patterns, authoritative source signals. You can have a well-known brand and still generate zero citations. I've seen this pattern repeatedly: a company with solid domain authority and decent SERP rankings, completely absent from AI-cited sources because their content was written for Google's crawl, not for AI retrieval architecture.
Closing the mention-citation gap requires treating generative engine optimization (GEO) as a distinct discipline. The goal isn't just to be known. It's to be the source an AI engine points to when it needs to back up a claim.
The 3 Signals AI Engines Use to Decide What to Cite
AI citation selection is not random, and it's not purely correlated with Google rankings. The arXiv GEO paper is the most rigorous academic treatment of this I've found, and its finding about earned media bias is the single most important data point for anyone building a citation strategy. Here's how I break down the three operative signals.
Signal 1: Topical authority depth. AI engines don't just want one good article on a topic. They want evidence that a domain owns a subject area. This is topical authority for AI search taken seriously. Not keyword clusters, but genuine depth across subtopics, with consistent entity signals (named authors, named methodologies, named data sources) that make the domain attributable. A site with 40 shallow articles on a topic will lose to a site with 12 deep ones, every time, in retrieval.
Signal 2: Third-party validation over self-assertion. This is where the E-E-A-T debate gets interesting. David Quaid has argued that E-E-A-T is a "major myth" originating from Google's Quality Rater Guidelines rather than a direct ranking signal. He's not entirely wrong about the Google SERP mechanism. But the arXiv GEO data doesn't care about that framing. It shows AI search systematically prefers earned media. Third-party, authoritative sources. Over brand-owned content. So even if E-E-A-T isn't a direct Google ranking lever, the underlying signal it proxies (external validation of your authority) is exactly what AI retrieval systems weight. Dismissing E-E-A-T entirely because of Quaid's critique would be a strategic mistake for anyone trying to appear in AI answers.
Signal 3: Structural extractability. This one is uncomfortable because it creates a real tension with SEO. The same formatting choices that make content extractable for AI. Tight Q&A structures, direct definitional answers, scannable headers. Are the ones Lily Ray flagged in her 2025 HCU retrospective as patterns among penalized sites. My working rule is that every piece needs at least one section that couldn't be cleanly lifted into an AI summary: something analytical, opinionated, or contextual enough that it only makes sense in full. Whether that actually protects Google rankings is still unconfirmed. But the alternative. Stripping content down to pure extractability. Risks the personality that makes readers trust you in the first place.
For Perplexity citation tracking specifically, the platform's citation behavior skews heavily toward sources that answer the specific query pattern being retrieved, not just the broad topic. That means matching your content structure to the actual question syntax matters more than domain authority alone.
Want to see which AI engines are citing your competitors but not you?
AI Citation Outreach: A Practical Playbook

I need to be direct about something before walking through this playbook: publisher pitching for AI citations is not the same as traditional digital PR, and the failure mode is different enough to name explicitly. With traditional link building, a relationship or a placement can move the needle. With LLMs, the citation decision happens at the model level. Training data and retrieval architecture. Not at some editorial layer you can reach through a campaign pitch.
The CJR/Tow Center research tested AI search engines and found all of them frequently failed to retrieve correct articles even when those articles were publicly available and properly indexed. That's not a content quality problem. It's a plumbing problem. No pitch email fixes plumbing.
So what does work? Here's the playbook I'd actually run.
Step 1: Find the domains AI engines cite for your topics. Before you pitch anyone, you need a cited-source leaderboard for your niche. This means running your core query patterns through ChatGPT and Perplexity and logging which domains appear as sources. Tools like Meev's Citation Path feature automate this. It surfaces the publishers AI engines actually cite for your topics, which is a different list than your SEO competitor set. These are your target domains.
Step 2: Map the citation gap. Cross-reference the domains AI engines cite against your existing backlink profile. The gap. Domains that cite your competitors but not you. Is your outreach list. This is more targeted than traditional link prospecting because you're not chasing DA scores. You're chasing proven AI citation sources.
Step 3: Create something worth citing. This is where most outreach fails. You can't pitch a publisher on linking to a generic blog post. You need original data, a named framework, a specific case study, or a counter-intuitive finding. The content has to add information that the publisher's audience (and the AI engine retrieving it) doesn't already have. This is the information gain principle applied to citation building.
Step 4: Pitch with specificity. A personalized pitch grounded in the publisher's existing content. Not a template. Is the baseline. Reference a specific article they published, explain what your piece adds that theirs doesn't, and make the editorial case for why their readers (and the AI engines that cite them) benefit from the reference.
Step 5: Track citation conversion, not just placement. A backlink from a high-citation-rate domain is valuable. But the question you actually want answered is whether that placement converts to AI citations. That requires ongoing monitoring across platforms. Meev's Claude visibility tracking and the Perplexity citation dashboard let you see whether new placements are moving your citation share, not just your backlink count.
One more thing on the Reddit question. 28% of Perplexity citations came from Reddit versus 12% from .edu domains in 2024, and Reddit citations in LLMs surged 150% since 2022. Eli Schwartz argues these are tactical and short-term. I agree. Chasing Reddit citations is a fragile strategy. The brand control is minimal, the sentiment is unpredictable, and the citation persistence is low. Build for earned media on authoritative publishers first.
Measuring Progress: From Mention Rate to Citation Rate
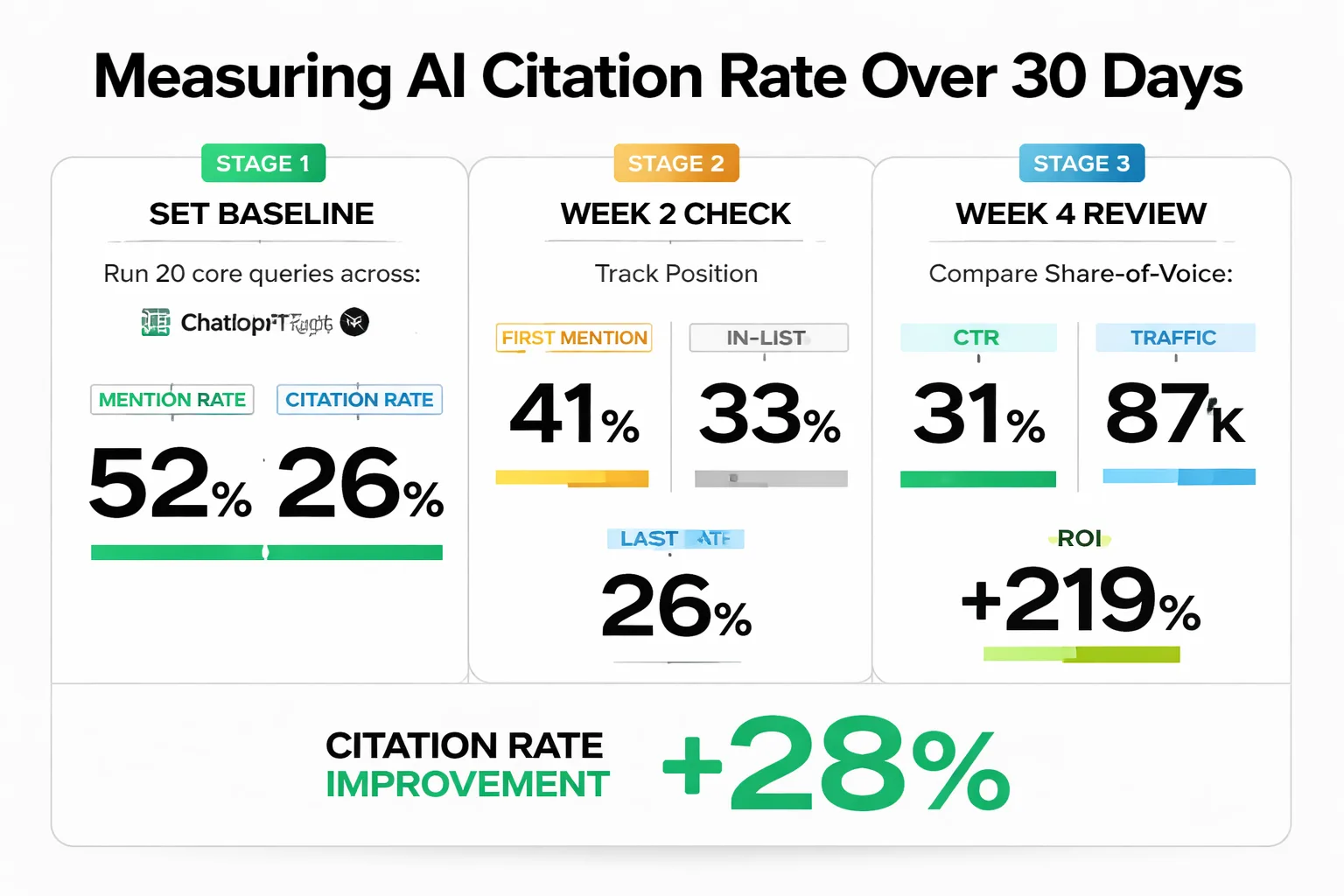
Most teams tracking AI visibility are measuring the wrong thing. Mention rate. How often your brand name appears in AI answers. Is vanity. Citation rate. How often an AI engine links to your content as a source. Is the metric that tells you whether your content is actually influencing the answer.
Here's how to set a baseline. Run your 15-20 core query patterns through ChatGPT and Perplexity. For each response, log three things: whether your brand is mentioned, whether your content is cited as a source, and where in the answer the citation appears (first, in a list, or last). That third variable matters because position correlates with how much the AI engine weighted your source. Do this for two weeks before making any content changes. That's your baseline.
What does realistic 30-day improvement look like? Honestly, less dramatic than most vendors will tell you. The pattern I keep seeing is that structural content changes. Adding specific data, tightening answer formatting, improving entity signals. Show up in Perplexity citation tracking within two to three weeks because Perplexity's retrieval refreshes more frequently. ChatGPT citation movement is slower because it's more dependent on training data cycles. Meev tracks AI visibility across ChatGPT, Claude, Gemini, Perplexity, Grok, Google AI Overviews, and DeepSeek with daily refresh on SERP-driven surfaces. That granularity matters when you're trying to isolate which content changes are actually moving citation share.
The cross-platform picture is where things get complicated. An analysis of 680 million AI citations found only 11% of domains were cited by both ChatGPT and Perplexity, confirmed independently by a Whitehat SEO study of 118,000 responses. That 11% overlap means you can win on one platform and be effectively invisible on the other. A brand that's optimized purely for Perplexity citation may have near-zero ChatGPT citation share. Separate baselines for separate platforms is not optional. It's the only way to know where your content is actually landing.
For teams comparing AI search visibility tools, the key differentiator isn't the dashboard. It's whether the platform gives you the actual response text and citation behind every mention, not just a mention count. Aggregate scores without source-level data are useless for diagnosing why your citation rate isn't moving.
The Mistakes That Keep Brands Out of AI Answers

The biggest mistake is publishing content that answers questions AI engines already have covered. If Perplexity can answer "what is content marketing" from a dozen authoritative sources it already retrieves, your 1,500-word explainer on the same question adds nothing. The AI engine has no reason to cite you because you've added no information it doesn't already have. This is the information gain principle, and ignoring it is the single fastest way to waste a content budget in 2026.
The second mistake is treating AI citation outreach like traditional link building. I went through this already, but it bears repeating: there is no editorial inbox at the end of an AI citation pipeline. The outreach that works is the kind that earns placements on high-citation-rate domains. Which then get retrieved by AI engines. The outreach that doesn't work is anything premised on "getting your content into" an AI model through a submission or relationship. That's not how retrieval architecture works.
The third mistake is scale without quality gates. The arXiv retrieval collapse study documented what happens when AI-generated content floods the pool: at 67% contamination, exposure contamination exceeded 80%, and answer accuracy remained deceptively stable while source quality collapsed. This is the scaled content abuse risk in concrete terms. If you're running any kind of auto-publishing workflow, the quality gate isn't optional. It's the only thing standing between your content operation and a retrieval ecosystem that learns to ignore you. At Meev, we built a 16-dimension quality firewall that blocks articles scoring below 70/100 from auto-publishing. The point isn't perfectionism. It's that weak content published at scale actively degrades your citation prospects by contributing to the retrieval noise that makes AI engines less likely to surface your domain.
The fourth mistake is assuming AI model comparison is irrelevant to your strategy. ChatGPT has 900 million weekly active users. Perplexity has 45 million. Those audiences behave differently, ask different questions, and the platforms cite different sources. An AI model comparison of citation behavior shows almost completely disjoint source selection. 89% of domains cited by one platform are not cited by the other. Building a citation strategy without specifying which platform you're targeting is like running an SEO campaign without specifying which country.
Finally: don't ignore the mention-citation gap as a diagnostic tool. If your brand is mentioned frequently but cited rarely, that's a content structure problem. If you're neither mentioned nor cited, that's a topical authority problem. The two failure modes have different fixes, and conflating them wastes time. Tools that track Google AI Overviews optimization separately from LLM citation tracking give you the granularity to tell them apart.
Frequently Asked Questions
How long does it take to see AI citation rate improvements after making content changes?
Perplexity citation changes typically show up within two to three weeks because its retrieval layer refreshes more frequently than ChatGPT's. ChatGPT citation movement depends more on training data cycles, which are slower and less predictable. Set a 30-day baseline before drawing conclusions, and track platforms separately. Movement on one doesn't imply movement on the other given the 11% cross-platform citation overlap.
Does ranking on Google Page 1 guarantee AI citation?
No. The Ahrefs query-level analysis found only about 12% cross-platform overlap between Google's top 10 and AI-cited domains. High Google rankings improve your chances because they signal domain authority, but AI retrieval systems pull from different signals than Google's ranking algorithm. A page can rank on Page 1 and never appear as an AI citation.
What content formats get cited most often by AI engines?
The arXiv GEO research found AI search systematically prefers earned media and authoritative third-party sources over brand-owned content. Within brand-owned content, formats with direct answers to specific query patterns. Tight Q&A structures, original data with named sources, and clear entity signals. Perform better in retrieval. Generic explainer articles without original data or a named framework rarely generate citations regardless of length.
Is Reddit a reliable target for AI citation building?
Short-term, Reddit citations are real. 28% of Perplexity citations came from Reddit versus 12% from .edu domains. But the brand control is minimal and sentiment unpredictable. Building a citation strategy around Reddit is fragile. Use it to understand what questions your audience is asking in natural language, then answer those questions on authoritative owned or earned media.
How do I know if my content has an information gain problem?
Run your target query through ChatGPT and Perplexity before you publish. If the existing answers already cover your planned content well, you have an information gain problem. The fix is to add something the current answers don't have: original data, a named framework, a specific case study, or a counter-intuitive finding grounded in your actual experience. If you can't identify what you're adding, neither can the AI engine.
Should I build separate citation strategies for ChatGPT and Perplexity?
Yes, eventually. With only 11% domain overlap between the two platforms, optimizing for one doesn't transfer to the other. Start by identifying which platform your target audience uses most, build your baseline there, and expand to the second platform once you have a working content and outreach playbook. Trying to optimize both simultaneously without a baseline is how teams end up with no clear signal on what's working.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Meev tracks your citation rate across ChatGPT, Perplexity, Claude, and six other AI engines — and shows you exactly which publishers to target to close the gap.