By Judy Zhou, Head of Content Strategy
Key Takeaways
- Perplexity cites Reddit for 46.7% of its top answers while ChatGPT favors Wikipedia at 47.9%, meaning the two engines require entirely different optimization strategies.
- Only 12% of AI citations overlap with Google's top 10 results — your traditional SEO rankings are largely irrelevant to whether either engine cites your content.
- Domain authority does not predict citation rates: Ahrefs (DR 88) achieved just 5% citation despite 100% visibility, while a sub-DR-10 site hit 15% through direct-answer structuring.
- The fastest citation fix is structural — moving your direct answer to the first 50-80 words of a page consistently outperforms any authority-building or outreach campaign.
When Perplexity launched in August 2022, it made a deliberate architectural decision that most observers barely noticed: every answer would display clickable source citations, treating the web as a live, attributable knowledge layer rather than a training artifact to be absorbed and forgotten. ChatGPT had launched just months earlier with the opposite philosophy — a closed model that synthesized knowledge without pointing anywhere. That fork in the road, made quietly by two product teams in late 2022, is now the central fault line in the emerging discipline of generative engine optimization, and it determines whose content gets seen versus whose content gets used.
For publishers, the perplexity vs chatgpt question isn't really about which tool is smarter. It's about which one will send traffic to your site, surface your brand in a buyer's research session, or cite your data in an answer that reaches thousands of people. Those are completely different questions, and the answers surprise most content teams.
Perplexity cites Reddit for 46.7% of its top answers; ChatGPT leans on Wikipedia for 47.9%. Only 12% of AI citations overlap with Google's top 10 results, meaning the SEO playbook you've spent years building is largely irrelevant to whether either engine cites you. A site with a Domain Rating under 10 can achieve 15% citation rates through direct-answer structuring, while Ahrefs (DR 88) sits at 5% citation despite 100% visibility. And according to BrightEdge's cross-platform research, source overlap between any two AI engines ranges from just 16% to 59%, which means a single content strategy won't cover all your bases.
The mention-citation gap is real, it's measurable, and it's costing publishers attribution they've earned.
How Each Engine Decides What to Cite
Perplexity is a retrieval-augmented generation (RAG) system at its core. When you submit a query, it doesn't reach into a static training snapshot. It fires live web searches, pulls candidate documents in real time, scores them for relevance, and synthesizes an answer from the retrieved content. The citations you see aren't decorative — they're the actual source documents the model pulled. This architecture means perplexity source selection is fundamentally a retrieval problem, not a reputation problem. The signals that matter are: does the page answer the specific query? Is it crawlable by Perplexity's bot? Does the content structure allow the model to extract a coherent passage?
ChatGPT's behavior is more complicated, and the complication matters enormously for publishers. The base model was trained on a static corpus with a knowledge cutoff, so for most queries, it synthesizes from memory without citing anything. When citations do appear, it's because the user is running a version with web browsing enabled (the default in ChatGPT Plus), or because the query explicitly triggers a search. Even then, ChatGPT's browsing behavior is more selective than Perplexity's. It doesn't retrieve broadly and synthesize — it tends to fetch a small number of high-authority pages and pull directly from them. That's why Wikipedia shows up in 47.9% of ChatGPT's cited answers. The model's training bias toward established, frequently-cited sources bleeds into its browsing behavior. It already "knows" which sources are authoritative, and it reaches for them first.

The practical implication: getting cited by Perplexity is an optimization problem. Getting cited by ChatGPT is partly a reputation problem — and reputation takes years to build.
Why Citation Rates Defy Domain Authority
This is the contrarian take I keep coming back to, because it contradicts almost everything the traditional SEO world assumes about content visibility.
Discovered Labs analyzed citation patterns across ChatGPT, Claude, and Perplexity and found citation gaps ranging from 25 to 95 percentage points across a seven-site sample. Ahrefs, one of the most authoritative SEO domains on the web, achieved 100% visibility in ChatGPT answers — meaning the model knew about Ahrefs content — but only 5% actual citation rate. Meanwhile, a low-DR site that structured its content as direct, self-contained answers achieved 15% citation. That gap is not a fluke. It's a signal about what these models actually optimize for during retrieval.
The visibility-versus-citation distinction is the one most teams miss. Being visible to an AI engine means the model encountered your content during training or retrieval. Being cited means the model chose your content as the source it would surface to the user. Those are different events, driven by different signals. Visibility correlates with domain authority. Citation correlates with answer proximity, structural clarity, and — for Perplexity specifically — community validation.
I keep returning to the Reddit data when I explain this to content teams. Reddit did zero deliberate GEO outreach, and their share of AI Overview citations jumped from 1.3% to 7.2% in a single quarter. The format did the work. Thread depth, upvotes, and direct-answer replies created retrievability signals that no carefully crafted authority-building campaign could replicate. When a platform accidentally outperforms everyone doing intentional outreach, that tells you something important about where the actual citation signal is coming from.
5 Content Formats That Win Citations in Both
After watching practitioners spend months on domain authority campaigns that moved nothing, the pattern that actually shows up in citation data comes down to structure. Here are the five formats I've seen consistently appear in both engines' outputs, ranked by how reliably they generate citations.
1. Direct-answer definitions. A short paragraph (40-80 words) that answers a specific question completely, in the opening sentences, without preamble. Both Perplexity and ChatGPT extract from these because they're self-contained. The model doesn't need surrounding context to make the passage coherent. If your definition requires reading the previous three paragraphs to make sense, it won't get extracted.
2. Statistic-with-source blocks. A specific number, attributed to a named study, presented in a standalone sentence. "According to BrightEdge, source overlap between AI engines ranges from 16% to 59%." That sentence is extractable, attributable, and quotable. Vague claims — "traffic increased significantly" — get synthesized away rather than cited.
3. Numbered step lists for sequential processes. When order genuinely matters, numbered lists signal to retrieval systems that this is procedural content. Both engines pull from numbered lists more reliably than from prose explanations of the same process. The key word is "genuinely" — forcing a list onto non-sequential content actually hurts extractability because the structure contradicts the content.
4. Expert quotes with full attribution. A named person, their title, and a direct quote. Perplexity in particular surfaces these because they carry both specificity and social proof. The quote needs to be verifiable — a fabricated attribution will eventually get flagged, and the domain loses trust with the retrieval system.
5. Comparison tables with specific dimensions. When you're comparing two things across named metrics, a table gives retrieval systems a structured data object they can pull intact. This is why comparison content tends to get cited more than narrative content on the same topic — the structure is machine-readable in a way that flowing prose isn't.
None of these formats require high domain authority. They require editorial discipline. That's the shift I've been pushing teams toward: treat every paragraph as a potential extraction unit, not just a piece of a longer argument.
Where Perplexity Beats ChatGPT for Publishers
Perplexity's real-time retrieval architecture gives newer content a genuine shot. A post published this week can appear in Perplexity citations this week, provided Perplexity's crawler has indexed it. That's not true of ChatGPT's base model, which is frozen at its training cutoff and only reaches the live web when browsing is triggered.
For breaking queries — anything tied to a recent event, a new product launch, a regulatory change, or a trending topic — Perplexity is where the citation opportunity lives. The BrightEdge research showing 16-59% source overlap between AI engines means Perplexity and ChatGPT are pulling from largely different source pools. If you're a publisher in a fast-moving vertical, optimizing exclusively for ChatGPT citation is a mistake.
Perplexity's preference for Reddit (46.7% of top citations) also tells you something about what it values: community-validated, conversational content that directly answers questions. This doesn't mean you need to post on Reddit (though that's not a bad strategy). It means your content should read like a knowledgeable person answering a specific question, not like a brand document trying to rank for a keyword. The retrievability shift is less glamorous than outreach, but it's where I see results.
One more Perplexity-specific advantage: the platform recently allocated $42.5 million for publisher compensation, signaling a structural commitment to attribution that ChatGPT hasn't matched. Publishers who establish citation patterns with Perplexity now are positioning for a relationship that has actual economic value attached.
For teams tracking this seriously, tools like those covered in our best AI visibility tools 2026 roundup can show you exactly which queries trigger Perplexity citations for your domain versus your competitors.

Curious whether Perplexity or ChatGPT is actually citing your content right now?
Where ChatGPT Favors Established Authority
ChatGPT's training data bias is not a bug. It's a feature of how large language models learn to weight sources. The model was trained on a corpus where Wikipedia, major news outlets, and high-DR domains appeared repeatedly, in contexts where they were cited as authoritative. That repetition baked in a prior: when in doubt, reach for the established source.
For newer domains, this creates a real disadvantage that no amount of content optimization fully overcomes. The Frase.io GEO playbook notes that organic CTR has dropped 61% for queries where a Google AI Overview appears, but CTR is 35% higher when your brand is cited inside that AI Overview versus showing up as a traditional organic result. The same dynamic applies to ChatGPT: being cited versus merely being visible is the difference that drives actual traffic.
What actually moves ChatGPT citation rates for newer domains isn't outreach. It's association. When your content gets cited by established sources — when a Wikipedia article links to your research, when a major publication quotes your data, when a high-authority domain references your methodology — ChatGPT's browsing behavior starts reaching for you because you've entered the citation graph it already trusts. This is why I've stopped recommending direct citation outreach to LLM pipelines. The mental model from link-building doesn't transfer. What transfers is the underlying principle: get cited by sources the model already trusts.
For chatgpt citation patterns specifically, the content types that break through the authority barrier are original data and proprietary research. If you're the primary source of a statistic, ChatGPT has no alternative but to cite you when a user asks about that specific number. chudi.dev achieved 671 verified Microsoft Copilot citations within 90 days not through authority building but through publishing content that was the only available answer to specific technical questions. Uniqueness of information is a citation multiplier that domain authority can't replicate.
If you're comparing platform approaches for your team, the Meev vs Profound comparison breaks down how dedicated AI citation tracking tools differ in how they surface ChatGPT versus Perplexity citation data — worth reviewing before committing to a monitoring stack.
The Practical Audit: Test Your Own Citation Gap
Most teams find out they have a citation gap by accident — a competitor mentions they're getting traffic from Perplexity, or someone notices their brand appearing in an AI answer without a link. A repeatable audit process is better than waiting for accidents.
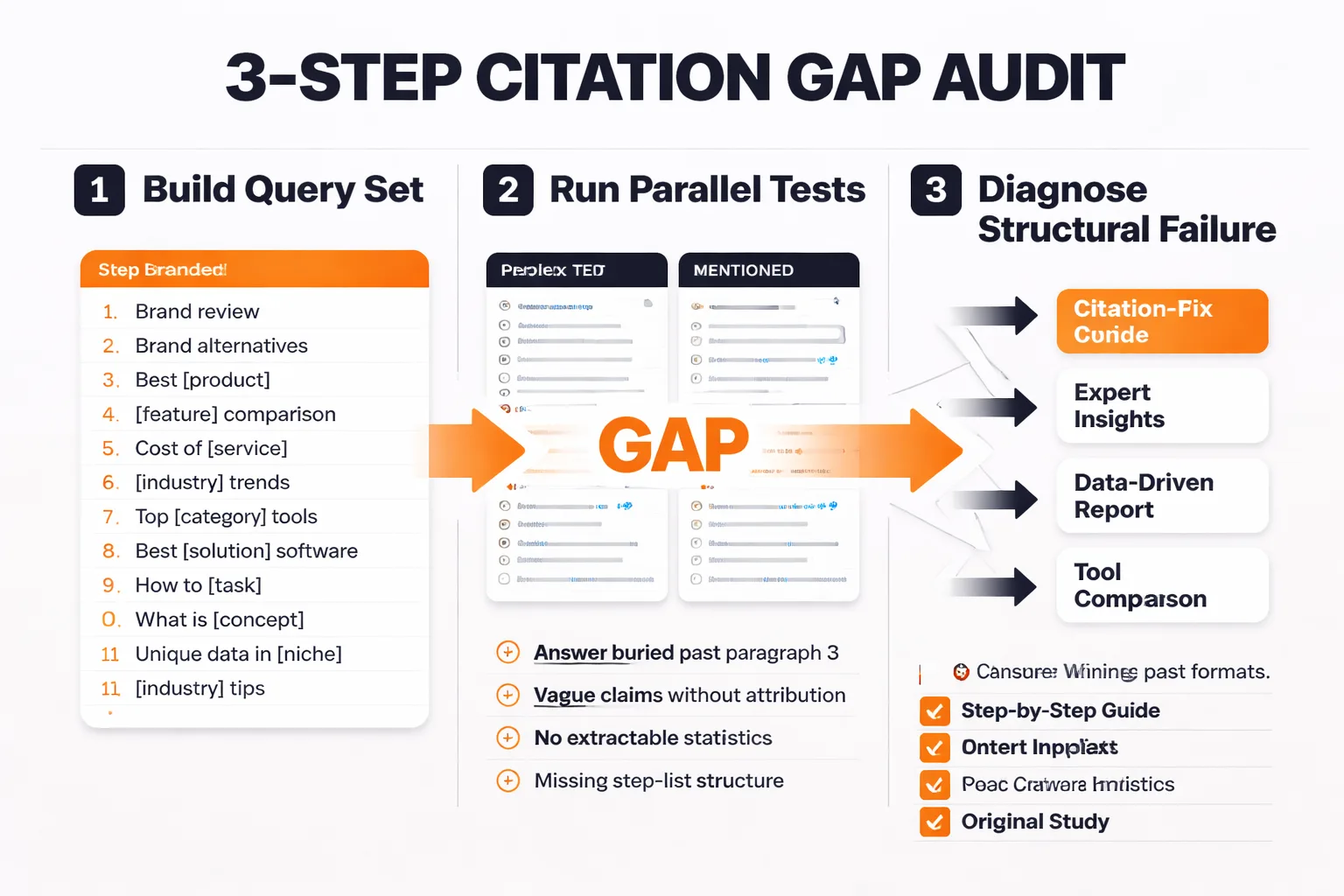
Here's the three-step process I use.
Step 1: Build your query set. List 10-15 queries where your content should theoretically rank. Include both branded queries ("[your brand] + [topic]") and unbranded informational queries where you have strong content. Don't start with vanity queries — start with the queries where a potential buyer would be researching a problem you solve. According to the Discovered Labs research, 94% of B2B buyers use AI search engines during vendor research, so this isn't a theoretical exercise.
Step 2: Run parallel tests in both engines. For each query, run it in Perplexity (free tier works) and in ChatGPT with browsing enabled. Document three things: (a) is your domain cited at all, (b) is your domain mentioned but not linked, and (c) is a competitor cited where you expected to appear. The gap between (b) and (a) is your mention-citation gap. This is the number to fix first.
Step 3: Diagnose the structural failure. For every query where you're mentioned but not cited, pull the page that should have been cited and run it through the five content format criteria above. Nine times out of ten, the direct answer is buried three paragraphs in, or the key claim is phrased as a vague generalization rather than a specific, extractable statement. Fix the structure before you do anything else.
For llm citation tracking at scale, free tools won't get you far. Platforms like Meev track citations across ChatGPT, Claude, Gemini, Perplexity, and Grok with daily cadence, which matters because citation patterns shift faster than monthly audits can capture. If you want a comparison of the tracking options available, the Meev vs Peec AI comparison covers the differences in methodology and pricing across dedicated AI search visibility tools.
One thing I've learned from running these audits: the citation gap is almost always larger than teams expect. A page can have top-10 Google rankings, strong E-E-A-T signals, and zero citations in either AI engine — because the answer is structured for a human reader skimming a blog post, not for a retrieval model extracting a passage. Those are different optimization targets, and most content written before 2023 was optimized for the wrong one.
Closing the Gap Requires Platform-Specific Thinking
The single biggest mistake I see in generative engine optimization strategies is treating Perplexity and ChatGPT as interchangeable. They're not. They have different architectures, different source preferences, different citation triggers, and different advantages for different types of publishers.
Perplexity rewards recency, structural clarity, and community-validated framing. ChatGPT rewards established authority, original data, and presence in the citation graph of sources it already trusts. A strategy that optimizes for one without acknowledging the other will leave citations on the table.
The good news: the content formats that win citations in both engines are the same formats that serve readers well. Direct answers, specific numbers, clear structure, attributable claims. The discipline required for AI citation is just good editorial practice applied with more precision than most teams have historically used. If you've been treating your blog as a keyword-capture vehicle, the adjustment isn't dramatic. But it is deliberate.
For teams serious about perplexity vs chatgpt citation performance, start with the audit. Measure your actual gap before investing in any platform or outreach strategy. The data will tell you which engine is the bigger opportunity for your domain, and that answer is different for every publisher.
Resources worth reviewing as you build your approach: our AI content creation 2026 state of play covers the quality signals that gate AI-era publishing, and the Meev vs Frase comparison is useful if you're evaluating whether a dedicated citation tracker adds value over a general SEO research tool.
Frequently Asked Questions
Does Perplexity cite every source it retrieves? No. Perplexity retrieves multiple candidate documents per query but only surfaces citations for the sources it directly quotes or synthesizes from in the answer. A page can be retrieved and scored without appearing as a citation. The distinction between retrieval and citation is what creates the visibility-versus-citation gap that most publishers don't measure.
How often does ChatGPT browse the web versus use training data? This depends on the query and the user's settings. ChatGPT Plus with browsing enabled will trigger a web search for queries that require current information, but for evergreen topics it frequently answers from training data without fetching any live sources. This means citation behavior is inconsistent and harder to optimize for than Perplexity's always-on retrieval.
Can a new domain with low authority get cited by ChatGPT? Yes, but the path is narrow. Original data and proprietary research that can't be sourced elsewhere is the most reliable route. If your content is the only available answer to a specific question, ChatGPT's browsing behavior will surface it regardless of domain authority. The chudi.dev example — 671 Copilot citations in 90 days from a previously unknown domain — is the clearest proof point for this.
What's the fastest way to improve Perplexity citation rates? Restructure existing high-traffic pages so the direct answer appears in the first 50-80 words. Perplexity's retrieval system scores for answer proximity heavily. Pages where the key claim is buried after context-setting paragraphs consistently underperform pages where the answer leads. This is a one-time structural edit, not an ongoing campaign.
Should I be tracking citations in both engines separately? Yes. BrightEdge found source overlap between AI engines as low as 16%, meaning a citation in Perplexity tells you almost nothing about your citation status in ChatGPT. Tracking them together in aggregate masks the platform-specific gaps that require different fixes. Dedicated AI search visibility tools that break out citation data by engine are worth the investment once you're publishing at any meaningful volume.
Does publishing on Reddit help with Perplexity citations? Indirectly, yes. Perplexity cites Reddit for 46.7% of its top answers, and that preference reflects the platform's bias toward community-validated, conversational content. Publishing on Reddit isn't a scalable citation strategy, but understanding why Reddit performs so well — direct answers, upvote validation, thread depth — should inform how you structure content on your own domain.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Run your first citation gap audit with Meev — track your brand across Perplexity, ChatGPT, Claude, Gemini, and Grok in one dashboard, with no credit card required to start.