
By Judy Zhou, Head of Content Strategy
Key Takeaways
- Just 6% of URLs account for 47% of all Perplexity citations, turning AI recommendations into winner-take-most advertising real estate.
- Only 9% of AI citations across OpenAI, Perplexity, and Google reference news sources, so target the open web over prestige publishers.
- 96% of Google AI Overview citations come from sources with strong E-E-A-T signals, per analysis of 2,400 citations—build expertise, experience, authoritativeness, and trustworthiness.
- Master Generative Engine Optimization (GEO) to earn unprompted AI citations, as factual accuracy lags at 39-77% even when sources are referenced.
When a potential customer asks ChatGPT which project management tool is best for remote engineering teams, and ChatGPT answers with confidence — naming three specific products and linking to two sources — where is your brand? Not on page two. Not buried in a listicle. Just absent. In 2026, the question every growth marketer, SEO lead, and content strategist needs to be asking isn't "how do we rank?" — it's "how do we get cited?" Because AI citations have quietly become the most valuable, most overlooked real estate on the internet.
AI citation 2026 is not a visibility metric. It's an advertising channel. When ChatGPT names your product unprompted, that's a recommendation with the trust weight of a friend, the reach of a broadcast, and a cost-per-impression of zero. According to a Peec AI analysis of over 1 million citations, just 6% of URLs account for 47% of all Perplexity citations. That's winner-take-most economics, identical to how premium ad placements work. An arXiv study of 366,000+ citations across OpenAI, Perplexity, and Google found that only 9% reference news sources — meaning the vast majority of AI citations come from the open web, not the prestige publishers most brands are pitching. Google's own quality rater guidelines underpin a system where 96% of AI Overview citations come from sources with strong E-E-A-T signals, based on analysis of 2,400 citations. And a PwC study on LLM attribution found that even when AI systems cite sources, factual accuracy against those sources sits between 39% and 77% — meaning being cited and being cited correctly are two different problems.
The discipline for earning these citations has a name: Generative Engine Optimization (GEO). This guide explains how it works, where most teams go wrong, and what a serious GEO strategy looks like in practice.
The Economics of Being Named
Think of an AI citation the way you'd think of a product placement in a Netflix series. The character doesn't read an ad. They just reach for the product. The viewer absorbs the recommendation without processing it as persuasion. That's exactly what happens when Perplexity answers a buyer's research question and names your SaaS platform in the second sentence.
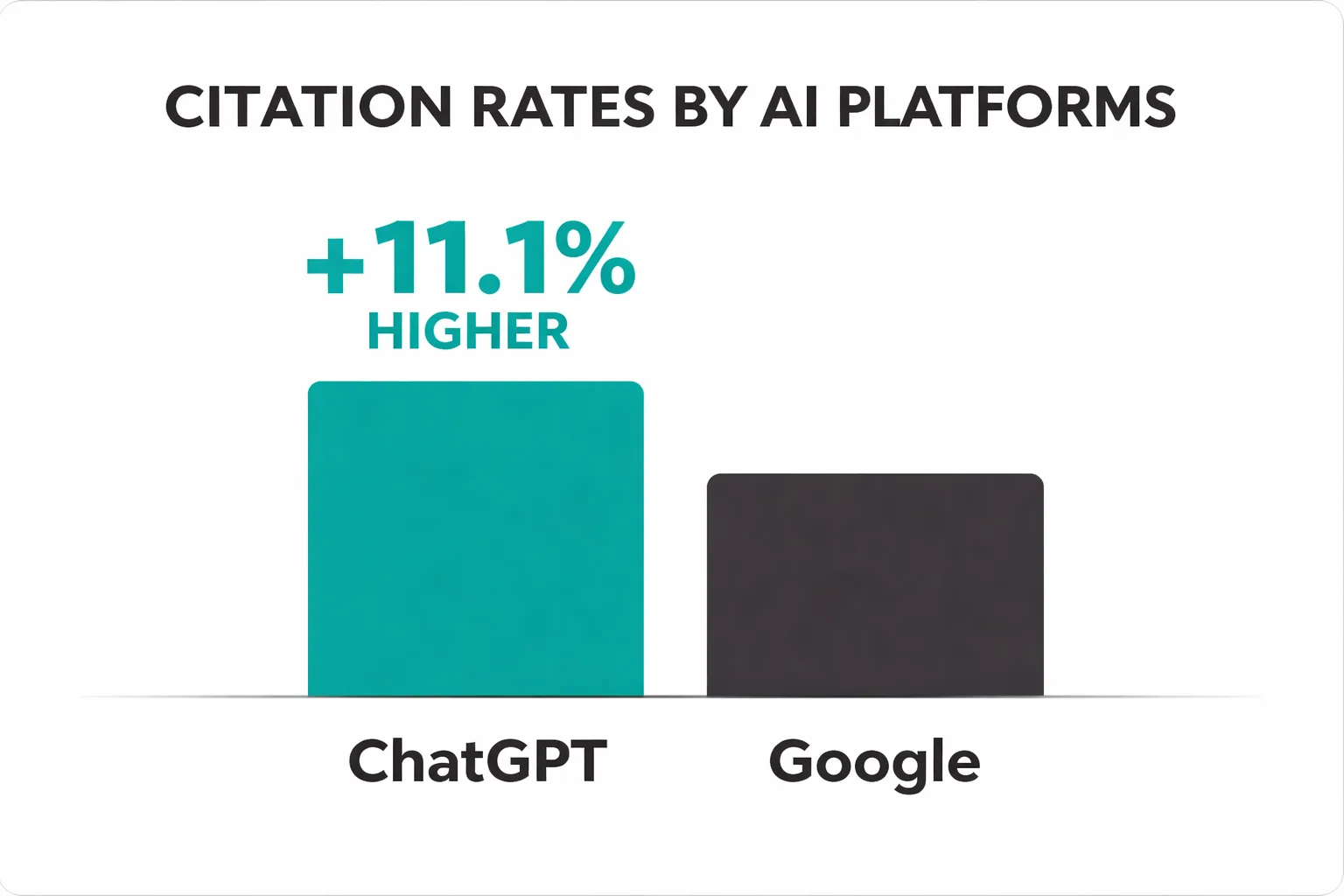
The analogy holds economically, too. Traditional digital advertising operates on a pay-per-exposure model with declining trust. Banner blindness is documented, ad blockers are widespread, and paid search click-through rates have eroded as AI answers displace the top of the SERP. AI citations, by contrast, are organic endorsements embedded inside a trusted answer. According to Peec AI's citation research, ChatGPT cites competitor websites at a rate 11.1 percentage points higher than Google does — meaning the platforms your audience uses for research are actively surfacing your competitors if those competitors have better corpus presence than you.
This is the economic case for treating Generative Engine Optimization 2026 as a primary channel, not an SEO appendix. The brands that get cited consistently are getting the equivalent of sponsored placements inside every relevant AI answer — for free, for as long as their content stays in the training corpus or retrieval index.
How Citation Selection Actually Works
Most teams assume AI citation works like organic search: build authority, earn links, rank higher, get cited. That model is wrong, and the data makes it uncomfortable to defend.
Wikipedia and Reddit together account for over 25% of ChatGPT's citations — Wikipedia at 13.15% and Reddit at 11.97%, according to the Semrush most-cited domains study. Neither of those platforms is curated by editorial teams chasing domain authority. They're cited because they're structurally parseable, massively indexed, and were present in training data at enormous scale before model cutoffs. The WSJ, NYT, and Bloomberg don't crack the top 20. That's not an editorial authority story. That's a corpus presence story.
Perplexity behaves differently from ChatGPT in ways that matter operationally. The Peec AI research found that 64% of URLs in Perplexity's index aren't cited directly at all, while 6% of URLs account for 47% of all citations. Perplexity also leans heavily on Reddit — 46.7% of its top citations come from the platform. Claude is 30% more likely to cite bullet-pointed pages. Google AI Overviews shows 54% overlap with traditional organic rankings, which is the highest of any platform but still means nearly half of its citations come from sources that wouldn't rank in traditional search.
An Ahrefs analysis I've seen cited internally found only 14% overlap in the top 50 cited sources across ChatGPT, Perplexity, and Google AI Overviews. I made the mistake early in my work here at Meev of building a citation strategy almost entirely around Google AI Overviews because that's where our clients had visibility data. The assumption was that performance would transfer across platforms. It didn't. Each platform has meaningfully different retrieval logic, and a unified strategy that ignores that distinction is just dilution.
The practical implication: pick one platform as your primary citation target based on where your audience actually searches, then layer in platform-specific formatting before expanding. Trying to win all three simultaneously without platform-specific content architecture is statistically failing 86% of the time.
Why Most GEO Strategies Fail
The failure mode I keep seeing is teams treating Generative Engine Optimization like SEO with a different name. Add "AI" to the keyword list. Write blog posts about AI. Wait for citations.
There's a documented case of a cybersecurity vendor that did exactly this. Six months of optimization effort. Zero AI citations. Zero AI referral traffic. Zero ROI. The problem wasn't that the content was bad in a human-readable sense. The problem was that it failed Google's quality thresholds before it ever had a chance to enter the retrieval pool, and it was structured for human narrative rather than machine extraction.
I had a client with a similar profile — well-established B2B publisher, strong domain rating, genuinely expert authors — getting consistently outperformed in Perplexity and ChatGPT responses by a scrappier competitor with a fraction of the backlink profile. When we pulled the competitor's content, it was almost aggressively boring: dense comparison tables, tightly labeled data points, almost no narrative prose. Our client's content was beautifully written and completely machine-illegible. LLMs aren't rewarding storytelling. They're pattern-matching against parseable structure.
We spent a quarter building a structured outreach program designed to get journalists and publishers linking to our content, theorizing that more inbound links would translate into more ChatGPT citations. It didn't move the needle. The link-building playbook we borrowed from SEO is largely irrelevant to GEO. What appears to matter is whether your content format and structure were present in the pre-training data — not whether a Condé Nast editor cited you post-publication.
The second failure mode is scaled content abuse. Google's quality threshold is actively filtering AI-generated content at the ranking stage before it can even reach AI retrieval systems. Publishers scaling auto-generated blog posts without quality gates are losing AI citations even when they're technically ranking — because the content fails the E-E-A-T evaluation that Google's Helpful Content System applies through machine learning classifiers. There's no published numerical threshold, despite what some vendors imply. It's a qualitative filter that behaves like a binary gate: you're either in the citation pool or you're not.

Wondering which AI platforms are actually citing your content right now?
Building Content AI Models Actually Cite
The structural shift that's actually moved the needle for teams I work with: treat every high-priority article as two documents in one. The narrative layer serves human readers. The embedded data layer — comparison tables, definition blocks, numbered findings, labeled statistics — serves retrieval.
For ChatGPT citation visibility, the priorities are corpus presence and consensus signaling. ChatGPT favors sources that appear across multiple contexts in training data, not just sources that rank well in current search. That means publishing consistently over time, getting referenced by other sources (not just linked to), and structuring content so that specific claims are extractable as standalone sentences.
For Perplexity citation tracking, the concentration data is the key insight. Because 6% of URLs get 47% of citations, the goal is to become one of those 6% in your topic cluster — not to broadly optimize. That means depth over breadth: one genuinely authoritative piece on a topic outperforms ten thin pieces targeting adjacent keywords.
For Claude visibility, the 30% citation lift for bullet-pointed pages is actionable. Restructure your highest-priority content to front-load key claims as bulleted findings. Claude's retrieval behavior rewards explicit structure more than prose density.
For Google AI Overviews optimization, the 54% overlap with organic rankings means traditional SEO still matters here more than on other platforms — but only as a floor, not a ceiling. The 46% of AI Overview citations that don't come from top-ranking pages are coming from sources with strong E-E-A-T signals that may not dominate traditional SERPs. The 96% E-E-A-T signal rate in AI Overview citations isn't a coincidence. It's the filter.
On E-E-A-T specifically: the "Experience" addition in 2022 changed what the framework rewards. First-person signals, named authors with verifiable credentials, documented methodologies — these are no longer nice-to-haves. They're the difference between content that passes the quality gate and content that doesn't. The mistake is assuming E-E-A-T is a score you optimize toward a number. It's not. Google's system uses machine learning classifiers generating weighted signals with no published cutoffs. The practical approach is to make the experience signals unmistakable: named authors, specific examples, verifiable claims, primary research where possible.
The Citation Accuracy Problem Nobody Talks About
Here's the contrarian take most GEO guides skip entirely: being cited by an AI doesn't mean being cited correctly.
The PwC study on LLM source attribution found that even frontier LLMs maintain factual accuracy of only 39-77% against their cited sources, despite link validity above 94%. The links work. The facts are often wrong. Fewer than 50% of open-source LLMs successfully generate cited reports in one-shot settings at all.
This matters for brand strategy in a way most teams haven't fully processed. If ChatGPT cites your pricing page but misquotes your price, that's not a win. If Perplexity cites your case study but attributes the results to a competitor, that's actively damaging. The implication is that GEO isn't just about getting cited — it's about making your content citation-proof. Specific claims should be short, self-contained, and impossible to misattribute. Numbers should appear in labeled contexts, not buried in paragraphs. The goal is to make your content so structurally clear that even a 39%-accuracy LLM gets your key facts right.
I treat citation accuracy as a content QA step now, not an afterthought. Before publishing any piece we want cited, we ask: if an LLM extracted just three sentences from this article, which three would they pull, and are those three sentences accurate and attributable?
Measuring AI Search Visibility 2026
Measuring AI search visibility is harder than measuring organic traffic, and the tooling is still maturing. The platforms I've looked at most closely — Profound and tools like it — don't share a conversion framework for translating citation data into expected referral behavior. That gap matters enormously for budget justification. If you're evaluating an AI search visibility tool, the question I'd ask before committing: show me a correlation between score movement and GA4 LLM-sourced sessions over at least a 90-day window with disclosed sample sizes. Right now, no published comparison I've found provides that. Treat any platform's citation score as a sentiment proxy until someone demonstrates the traffic connection.
What you can measure today: direct referral traffic from AI platforms (visible in GA4 as traffic from chatgpt.com, perplexity.ai, etc.), brand mention frequency in AI responses (tracked manually or via monitoring tools), and citation rate by content type (which formats get cited more often). These are imperfect proxies, but they're real signals connected to real outcomes.
For teams using scaled content workflows, the measurement discipline matters even more. The difference between content that earns AI citations and content that gets filtered by quality thresholds is often invisible in traditional analytics until you look at AI-sourced sessions specifically. If you're running high-volume publishing through a platform like Meev, quality gates need to be part of the workflow before content goes live — not a retrospective audit.

Putting GEO Into Practice
The teams getting traction with Generative Engine Optimization 2026 are doing a few things consistently that others aren't.
First, they've stopped treating GEO as a content volume play. The cybersecurity vendor failure case isn't an outlier — it's the default outcome for scaled content without quality gates. Every piece that enters the publishing pipeline should pass a citation-readiness check: named author with verifiable credentials, at least one primary data point with a source URL, structured data layer (table, definition block, or numbered findings), and a self-contained extractable claim in the first 200 words.
Second, they've built platform-specific content variants for their highest-priority topics. Not entirely different articles — the same core research, reformatted for different retrieval preferences. The ChatGPT version emphasizes consensus signals and citable standalone sentences. The Perplexity version goes deeper on a narrower question. The Claude version leads with bullet-pointed findings.
Third, they're monitoring the mention-citation gap. A brand mention in an AI response without a citation is a missed opportunity — the AI knows about you but isn't attributing you. That gap is often closeable with structural changes to the content being referenced. Meev's content operations workflow includes this as a standing audit: identify pages that generate brand mentions without citations, then restructure for parseability.
The teams that treat AI citations as a passive SEO byproduct will keep watching competitors get named in answers their customers trust. The teams that treat AI citation 2026 as a primary channel — with dedicated strategy, platform-specific formatting, and citation accuracy as a QA step — are building the kind of visibility that no ad budget can replicate.
That's the shift. Citations are the new ads. The question is whether you're running them.
Frequently Asked Questions
How is Generative Engine Optimization different from traditional SEO?
Traditional SEO optimizes for ranking positions in a list of results. Generative Engine Optimization optimizes for inclusion in a synthesized AI answer. The signals are different: SEO rewards backlink authority and keyword density, while GEO rewards corpus presence, structural parseability, and E-E-A-T signals. A page can rank on page one of Google and never appear in a ChatGPT response — the two systems use different retrieval logic and different source preferences.
Which AI platform should I prioritize for citation optimization?
Start with where your audience actually searches, not where you have the most visibility data. If your buyers are using Perplexity for vendor research, optimize there first. If they're using ChatGPT, the corpus presence and consensus signals matter most. Google AI Overviews has the highest overlap with traditional organic rankings (54%), so if you're already investing in SEO, that's often the lowest-lift starting point. Avoid spreading effort evenly across all platforms without platform-specific formatting — the overlap between top cited sources across platforms is only around 14%.
Does publishing AI-generated content hurt AI citation rates?
It can, but the mechanism is indirect. AI-generated content isn't penalized for being AI-generated. It's filtered when it fails Google's quality thresholds — which happens more often with scaled auto-generated content because quality gates are frequently absent. The documented failure cases involve content that was thin, lacked E-E-A-T signals, or was structurally identical across many pages. Quality-gated AI content with named authors, primary data, and genuine depth can and does earn citations.
How do I know if my content is being cited by AI platforms?
GA4 now captures referral traffic from AI platforms like chatgpt.com and perplexity.ai as distinct traffic sources. That's the most direct signal. For brand mentions without citations (the mention-citation gap), you'll need a monitoring tool or manual prompt testing across platforms. AI search visibility tools like those compared at Meev vs Profound track citation frequency, but treat their scores as directional proxies until you can correlate them with actual GA4 LLM-sourced sessions over a 90-day window.
What's the fastest way to improve E-E-A-T signals for AI search?
Three changes move the needle fastest: add a named author with a verifiable credential (linked bio, publication history, or professional profile) to every high-priority page; include at least one primary data point with a source URL in the first 200 words; and restructure the page to include at least one comparison table, definition block, or numbered findings list. These changes make E-E-A-T signals explicit rather than implied, which is what Google's machine learning classifiers are evaluating. There's no published numerical threshold — the goal is to make the signals unmistakable, not to hit a score.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
See exactly where your brand appears (and where it's missing) across ChatGPT, Perplexity, and Google AI Overviews — before your competitors close the gap.