
By Judy Zhou, Founder
Key Takeaways
- Only 12% of AI-cited URLs appear in Google's top 10 organic results for the same query, meaning traditional SEO rank is a poor proxy for AI citation success.
- ChatGPT and Perplexity share only 11% of their cited URLs, so you need a per-engine citation strategy, not a single optimization pass.
- A continuous citation review program at Reachdesk generated 15,335 LLM citations in 60 days, a 43% increase, by targeting comparison pages and review platforms specifically.
- The mention-citation gap is the key metric: high AI mention frequency with low citation rate means engines know your brand but don't yet trust it enough to point readers to you.
In the spring of 2023, a small cluster of SEO researchers noticed something strange in early ChatGPT outputs: the same thirty or forty domains kept surfacing across wildly different query categories. Nobody had optimized for this. Those sites weren't gaming anything. They had simply spent years building the kind of dense, authoritative, well-sourced content that language models, trained on the open web, had quietly learned to trust. That accidental advantage became the earliest case study in what we now call ai citation outreach, and tracing it back reveals exactly which signals still matter most heading into 2026.
The numbers should reframe your priorities immediately. Only 12% of AI-cited URLs appear in Google's top 10 organic results for the same query, meaning traditional SEO rank is a poor proxy for AI citation success. Between 50% and 90% of LLM-generated citations don't fully support the claims they're attached to, per Wu et al. in Nature Communications 2025. ChatGPT and Perplexity share only an 11% overlap in the URLs they cite, which means optimizing for one engine doesn't automatically win the other. And in a case study tracked by Nick Bennett at Reachdesk, a continuous citation review program generated 15,335 total LLM citations in 60 days, a 43% increase over the prior period. These aren't incremental gains. They're structural.
As someone who oversees AI-driven content research and publishing for hundreds of brands at Meev, I've watched teams chase AI visibility with the wrong playbook. The five steps below are the ones that actually move the citation rate needle.
The Citation Gap Most Teams Miss
Before executing any strategy, you need to understand the gap between being seen by an AI and being cited by one. They are not the same thing, and conflating them is the most expensive mistake I see brands make.
ClaudeBot crawls content at a 38,065:1 ratio compared to referral traffic sent back to sources. That means Anthropic's crawler is reading your pages at massive scale while Claude rarely points readers back to you. Being discoverable in an LLM's training or retrieval phase is fundamentally different from being selected as a citation in a final answer. The former is passive. The latter requires deliberate positioning.
I've also seen this play out in a way that's worse than being ignored entirely. Getting cited incorrectly by an AI. Surfaced for a use case that doesn't match what you actually deliver. Creates mismatched expectations at the conversion point. A prospect arrives from an AI answer believing you do X, and you do Y. That mismatch kills signup rates. Citation volume is not the goal. Accurate, high-intent citation is.
With that framing in place, here's how to build a citation rate that compounds.
Step 1. Audit Which AI Engines Are Ignoring You and Why
You can't fix what you haven't measured. The first step in any ai citation outreach program is a structured prompt audit across the engines that matter most to your audience: ChatGPT, Perplexity, Google AI Overviews, and Gemini.
Run 20 to 30 prompts that represent real buyer queries in your category. Not keyword-stuffed phrases. The actual questions a prospect would type into Perplexity at 11pm before a purchase decision. For each prompt, record: which domains appear in the cited sources, where your brand appears (first, in a list, buried at the bottom, absent), and which competitor content is winning the citation you should own.
The reason this audit matters beyond the obvious: ChatGPT and Perplexity pull from meaningfully different source pools. That 11% citation overlap I mentioned means you're looking at two distinct citation ecosystems. A brand that dominates Perplexity citations may be nearly invisible in ChatGPT answers for the same query, and vice versa. Tools like Meev's AI visibility tool track citation presence across every major AI search surface with daily refresh, which makes this audit repeatable rather than a one-time snapshot. The Perplexity AI visibility checker is particularly useful for isolating Perplexity-specific citation patterns, since Perplexity's Sonar API retrieval behavior differs from how ChatGPT surfaces sources.
Once you have your audit data, sort your findings into three buckets: queries where you're cited accurately, queries where a competitor is cited in your place, and queries where no authoritative source exists yet. That third bucket is your fastest opportunity. An uncontested query is a citation waiting to be claimed.
How Does Information Gain Actually Work in AI Citation?
Information gain is one of three evaluation criteria in RAG (retrieval-augmented generation) pipelines, alongside semantic relevance and entity coherence. In plain terms: an AI engine is more likely to cite a source that adds something new to the answer, not one that restates what every other page already says.
This is the contrarian take most content teams need to hear. The mass-volume content play for citation building is broken. I've watched brands pour budget into publishing cadences that generate zero citation traction because the content is optimized for quantity over genuine usefulness. The data backs this up: 80% of Reddit posts that get cited by AI engines had fewer than 20 upvotes. Not thousands. Not hundreds. Fewer than 20. AI isn't rewarding output volume. It's rewarding genuine community signal and original perspective.
Information gain in practice means four things: original data your competitors don't have (even small surveys or internal benchmarks count), clear and precise definitions that resolve ambiguity on a contested term, structured answers that let an AI engine extract a clean response, and E-E-A-T signals that establish the author as a real expert with real credentials. The last one matters more than most teams realize. Citation accuracy varies significantly by platform, with the best-performing platform achieving roughly 66% citation accuracy and the worst below 50% (Venkit et al., arXiv 2024). Engines that struggle with citation accuracy are actively trying to improve it. And they do that by weighting sources with strong author entity signals more heavily.
Content formats that earn AI citations: original research with methodology disclosed, FAQ-structured articles with self-contained 50-80 word answers per question, comparison pages that name specific alternatives with specific differentiators, and data-backed opinion pieces where the author's credentials are verifiable. Content formats that don't earn citations: thin listicles with no original perspective, generic how-to content that mirrors the top 10 results, and anything that reads as promotional rather than informational. The distinction isn't about length. It's about whether the content adds something the AI couldn't reconstruct from its training data alone.
Understanding the difference between AEO vs SEO is foundational here. Answer engine optimization prioritizes extractable, self-contained answers. Traditional SEO prioritizes keyword density and backlink volume. Those two goals occasionally overlap, but they diverge more often than most practitioners expect.
Wondering which AI engines are citing your competitors instead of you right now?
Step 2. Produce Information-Gain Content AI Engines Want to Cite
The practical execution of information-gain content starts before you write a single word. Pull the prompt audit results from Step 1 and identify the queries where competitors are being cited. Read those competitor pages carefully. Ask: what is this page saying that the AI extracted? Now ask: what is this page not saying that a genuine expert in this space would add?

That gap is your brief.
For each target query, build one piece of content that does three things the cited competitor doesn't: adds a data point (even a single original statistic from your customer base, your internal tooling, or a survey you ran), names a specific failure mode or edge case the competitor glosses over, and includes a byline with verifiable credentials. Not a generic "written by the marketing team" attribution. A named author with a LinkedIn profile, published work, or a demonstrated track record in the field.
65% of AI citations come from content published in the past year, which means recency matters alongside depth. A well-structured, information-dense piece published in 2026 will generally outperform a thinner piece from 2023, even if the older piece has more backlinks. This is one of the clearest ways AI citation behavior diverges from traditional organic ranking signals.
If you're scaling content production, the quality gate matters more than the volume. I've seen the failure mode play out in Bogdan Babiak's experiment (documented by Chris Long on LinkedIn): 20 new domains, 100 AI-generated articles each, 2,000 total pieces. 70% indexed within 36 days. Initial impressions growth in months one and two. Then a performance crash by month three. No editorial gate. No information gain. Just volume. The pattern I keep seeing is that pure auto-publish pipelines without human review don't just plateau. They actively get demoted. Meev's 16-dimension quality firewall exists specifically to catch this before a weak draft reaches your CMS, but the underlying principle applies regardless of your tooling: every piece that goes live should add something the existing indexed web doesn't already have.
Step 3. Execute Targeted AI Citation Outreach
This is where most teams stop at "write good content and hope." That's not a strategy. Targeted ai citation outreach means identifying the specific publishers and pages that AI engines already trust for your topic, then getting your brand cited within that existing trusted content.
The logic is sound: if an AI engine has learned to cite a particular domain for queries in your category, a mention of your brand on that domain carries citation weight you can't manufacture by publishing on your own site. You're borrowing trust that took the publisher years to build.
Here's how to prioritize outreach targets. First, use your prompt audit data to identify which third-party domains are being cited for your target queries. These are your tier-one targets. Second, look at comparison pages and review aggregators in your category. Nick Bennett's Reachdesk case study found that compare pages nearly tied with review pages as the top citation source for LLM answers. A finding that should shift where you invest outreach effort. Third, identify journalists and authors who have written about your category in the past 12 months and whose articles are appearing in AI answers.
For outreach pitches, specificity is everything. A generic pitch asking for a brand mention will be ignored. A pitch that says "your article on [specific topic] is currently being cited by Perplexity for [specific query] — I have a data point that would make that answer more accurate and complete" has a genuine reason for the editor to respond. You're offering information gain to the publisher, not just asking for a favor.
Meev's Citation Path feature (Pro tier and above) automates the first half of this process: it finds the publishers AI engines cite for your topics, surfaces verified contact information, and drafts personalized outreach pitches grounded in your knowledge base. The outreach itself still requires human judgment on timing and framing, but the prospecting work that used to take hours gets compressed significantly.
One outreach template that works:
Subject: Data point for your [topic] article. Currently cited by Perplexity
Hi [Name], your piece on [specific topic] is surfacing in Perplexity answers for [query]. I noticed it doesn't include [specific data point or perspective]. We recently [published original research / ran a survey / analyzed X] that shows [specific finding]. Happy to share the full dataset if it would strengthen the piece. No ask for a link. Just thought the data would be useful.
That framing works because it leads with value, references a specific piece of evidence the editor can verify, and removes the transactional pressure of a link request. The mention often follows naturally once the relationship is established.
Step 4. Optimize Your Pages for AI Source Selection
Even the best content gets ignored by AI engines if the page structure makes extraction difficult. This step is about removing friction between your content and an AI's source selection process.
Schema markup is the most direct signal. FAQ schema, HowTo schema, and Article schema with a named author entity all help AI engines understand the structure and authority of your content. What is AEO covers the full technical picture, but the short version is this: structured data is a machine-readable signal that your page contains an authoritative, extractable answer. Engines that support structured data in their retrieval process use it. Don't leave it out.
Answer blocks matter more than most SEOs realize. For every question your page targets, write a 50-80 word self-contained answer in the first paragraph of that section. The answer should make sense extracted in isolation, without needing the surrounding context. This is how AI engines pull quotes and summaries. If your answer requires reading three paragraphs of setup before it resolves, it won't get extracted cleanly.
Author entity signals: every page you want cited should have a named author with a linked bio, verifiable credentials, and ideally a consistent publishing history on your domain. Anonymous or team-attributed content gets deprioritized in citation selection. This is the E-E-A-T principle applied specifically to AI source selection rather than traditional organic ranking.
The llms.txt file is newer and worth implementing now. It's a structured file that tells AI crawlers which sections of your site are permitted for citation, similar to how robots.txt works for search crawlers. Meev's free LLMs.txt Validator checks whether your current file is correctly formatted and flags any issues that would cause crawlers to misread your permissions. It takes ten minutes to implement and removes a class of technical friction that's otherwise invisible.
Finally: outbound citations. Pages that cite primary sources themselves are more likely to be cited by AI engines. The logic is that a page with no outbound references looks like a closed information loop. A page that cites original research, official documentation, and named studies signals that it's part of a broader information ecosystem. Which is exactly the kind of source an AI engine wants to reference.
For a deeper look at how AEO vs GEO differ in their technical optimization requirements, the distinction matters when you're deciding where to invest page-level optimization effort.
Step 5. Measure, Iterate, and Close the Gap
Measurement without a framework is just data collection. The metric that matters most is the mention-citation gap: the difference between how often your brand appears in AI answers and how often it appears as a cited source. A brand can have high mention frequency and near-zero citation rate, which means the AI knows about you but doesn't trust you enough to point readers to you.
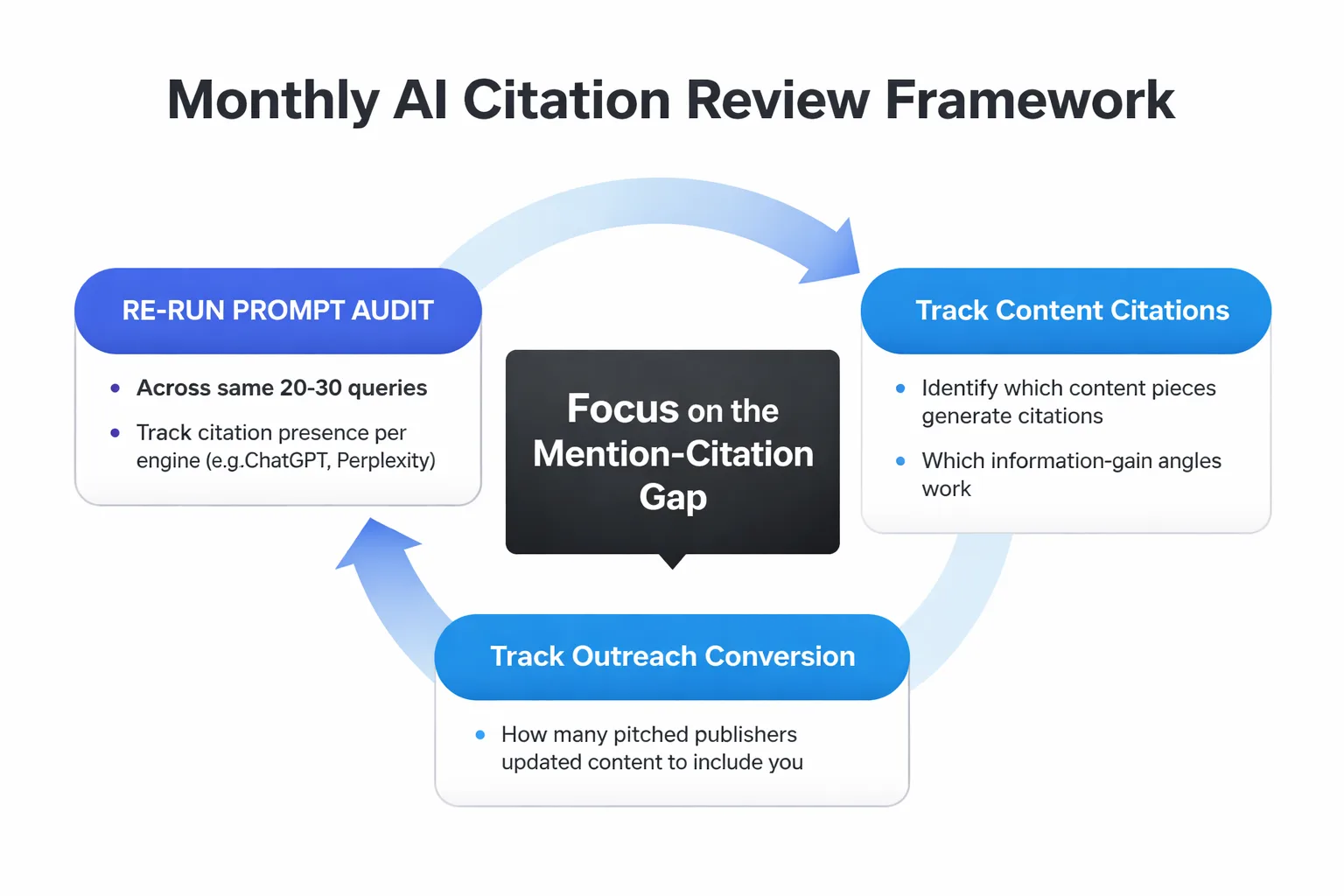
Set up a monthly review with three components. First, re-run your prompt audit from Step 1 across the same 20 to 30 queries. Track citation presence per engine, not just overall. Because ChatGPT and Perplexity pull from different source pools, a gain in one engine doesn't mean you've closed the gap in the other. Second, track which pieces of content are generating citations. This tells you which information-gain angles are working and which aren't. Third, track outreach conversion: of the publishers you pitched, how many updated their content to include your data or mention? What was the time lag between pitch and citation appearance in AI answers?
HubSpot's AEO program reportedly grew leads from AI by 1,850% — a number that's hard to contextualize without knowing the baseline, but the directional signal is clear. Brands that treat AI citation as a structured, measured program rather than a passive byproduct of good content are seeing compounding returns. The Reachdesk case study (43% citation lift in 60 days) reinforces the same pattern: continuous review and iteration beats one-time optimization.
For llm citation tracking at scale, Meev's platform tracks mention position (first, in a list, last), per-engine citation rates, and the actual response text behind every mention with weekly trend data. That level of granularity lets you diagnose whether a citation gap is a content problem (you're not producing information-gain material for that query), a structural problem (your pages aren't optimized for extraction), or an outreach problem (the trusted publishers in your category haven't included your brand yet).
The iteration cadence I recommend: monthly prompt audit, quarterly content refresh on your top 10 target queries, and ongoing outreach with a pipeline of 15 to 20 publisher targets at any given time. That rhythm compounds. The brands that started building citation authority in 2023 without knowing what they were doing now hold positions that are genuinely hard to displace. The brands that start in 2026 with a deliberate program will build that same compounding advantage, just faster.
Where This Approach Breaks Down
I want to be honest about the scenarios where this five-step framework doesn't deliver what you'd expect.
First: highly commoditized queries. If you're in a category where the top cited sources are Wikipedia, major news outlets, and government domains, no amount of outreach will displace them in the near term. AI engines have strong priors toward institutional sources for certain query types. The play there is to target the adjacent, more specific queries where institutional sources don't exist yet.
Second: brand-new domains with no citation history. The citation patterns AI engines rely on are built from training data and retrieval behavior that rewards established trust signals. A domain launched in 2026 with no backlinks, no author entity history, and no existing citations faces a cold-start problem that content quality alone won't solve quickly. The outreach step matters more for new domains precisely because you need to borrow trust from established publishers while you build your own.
Third: categories where AI engines actively hedge. For health, legal, and financial queries, AI engines often deliberately avoid citing specific brands and instead surface general information or official sources. Citation outreach in YMYL (Your Money Your Life) categories requires a different strategy that prioritizes regulatory and institutional publisher relationships over general publisher pitching.
Frequently Asked Questions
How long does it take to see results from AI citation outreach?
Most practitioners see measurable citation movement within 60 to 90 days of consistent execution. The Reachdesk case study achieved a 43% citation lift in 60 days with a continuous review program. Content updates tend to show results faster than new content, since the page already has some crawl history with AI engines. Outreach-driven citations depend on how quickly the target publisher updates their content and how frequently the AI engine refreshes its source pool.
Do I need to optimize differently for ChatGPT vs. Perplexity vs. Google AI Overviews?
Yes, and the differences matter. ChatGPT and Perplexity share only 11% of their cited URLs, per DataForSEO research. Perplexity uses real-time retrieval and prioritizes recently published, well-structured pages. Google AI Overviews leans heavily on pages that already rank in organic search. ChatGPT (without browsing) pulls from training data, which means older, high-authority content carries more weight. A complete ai citation outreach strategy addresses all three rather than assuming one optimization covers all surfaces.
Is llms.txt actually necessary for AI citation?
It's not a hard requirement, but it removes a specific class of friction. Without an llms.txt file, AI crawlers make their own decisions about which sections of your site to index for citation purposes. With a correctly formatted file, you're giving explicit guidance. For sites with paywalled content, member-only sections, or pages you don't want cited out of context, it's particularly valuable. Use Meev's free LLMs.txt Validator to check your current setup.
How do I measure the ROI of AI citation outreach?
The most direct ROI signal is traffic from AI referral sources (visible in GA4 as direct or referral traffic from Perplexity, ChatGPT, etc.) correlated with citation rate changes. The harder attribution problem is that AI citations often influence purchase decisions before a user ever clicks through. Track citation rate as a leading indicator, then watch for downstream movement in branded search volume and direct traffic. HubSpot's reported 1,850% lead growth from AI is an extreme example, but the measurement framework is the same: citation rate up, then pipeline up.
What's the single most important piece of content to create first?
Start with a comparison page that names your top three competitors by name and provides specific, verifiable differentiators. Comparison pages are among the most-cited content formats in LLM answers for commercial queries. They answer the exact question a buyer asks an AI engine before a purchase decision, and they're the format where AI engines most often surface specific brand citations rather than generic category information. Nick Bennett's Reachdesk data showed compare pages nearly tied with review pages as top citation sources. That's a strong signal about where to invest first.
About the Author
Judy Zhou, Founder
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Run a free AI visibility audit on your domain and see exactly where your citation gaps are across ChatGPT, Perplexity, and Google AI Overviews.






