
By Judy Zhou, Head of Content Strategy
Key Takeaways
- Citation consistency across ChatGPT, Perplexity, Gemini, and Claude is the strongest leading indicator of durable AI search visibility — single-engine performance is noise, not signal.
- 76.4% of ChatGPT's most-cited pages were updated within 30 days of being cited, meaning a publish-and-forget strategy actively erodes AI citation share over time.
- 96% of AI Overview citations come from sources with strong E-E-A-T signals, and schema markup alone produces a 3-5x citation lift — the highest-ROI single implementation available.
- Prompt coverage depth — how many prompts in your topic cluster you appear in versus competitors — predicts topical authority in AI engines better than any single page's optimization score.
Marcus had spent three years building what his agency considered an airtight content library. 400 articles, strong backlinks, solid rankings. Then a client asked him to search their brand in Perplexity. A competitor with a six-month-old site appeared in the cited sources. His client's content didn't. No explanation, no ranking drop, no penalty notice. Just absence. That moment sent Marcus down a months-long investigation into what AI search engines actually reward, and what he found reordered everything he thought he knew about visibility.
AI search visibility measures something different from traditional rankings. According to HubSpot's breakdown of AI search visibility, it tracks how often a brand is mentioned, how owned content is cited, and critically, how those mentions are framed in model responses. That framing distinction is everything. Being mentioned in passing is not the same as being cited as the authoritative source on a topic. And neither of those is the same as being recommended when someone asks an AI which solution to use. The gap between those three states is where most brands are losing ground right now, without realizing it.
The four signals below aren't tracking metrics. They're predictive indicators. The upstream variables that determine whether your AI search visibility improves or erodes over the next 90 days. I've organized them in order of diagnostic priority, starting with the signal most teams misread.
Why Mention Rate Alone Is a Misleading Metric
Most teams, when they first start measuring ai search visibility, look at one number: how often their brand appears in AI responses. That's a reasonable starting point. It's also where the analysis should begin, not end.
The distinction that actually matters is between three different types of AI appearances. A mention is passive. The AI referenced your brand in passing while discussing a broader topic. A citation means the AI pulled from your content as a source for a specific claim. A recommendation is when the AI actively suggests your brand as a solution to a user's problem. Search Engine Land has reported on a 30% visibility threshold concept, where brands that appear in AI responses for fewer than 30% of relevant prompts in their category struggle to convert that visibility into measurable pipeline activity. The implication is directional: recommendation rate, not raw mention rate, is the metric that correlates with buyer action.
I've watched teams celebrate an uptick in AI mentions while their recommendation rate stayed flat. The AI was mentioning them the way a journalist mentions a company in a paragraph about industry trends. Contextually present, but not driving decisions. In B2B SaaS contexts specifically, the prompt that matters is "what tool should I use for X" — not "tell me about companies in the X space." Those are different queries, and they pull from different content signals.
The practical fix: stop measuring mention frequency as a standalone metric. Track it alongside citation rate (is your content being sourced?) and recommendation rate (is your brand being suggested?). The ratio between those three tells you far more about trajectory than any single number.
Signal 1. Citation Consistency Across LLMs
Single-engine visibility is a false positive. Full stop.
I've seen brands with strong Perplexity citation rates assume they've solved their AI visibility problem, only to find they're essentially invisible in ChatGPT responses for the same prompts. The engines don't share a citation pool. They have different training data cutoffs, different retrieval architectures, and different weighting for source types. A brand that appears consistently in ChatGPT responses but not in Perplexity or Gemini has a structural gap, not a visibility win.
The measurement approach here is straightforward but time-consuming if done manually: run the same set of 20-30 prompts across ChatGPT, Perplexity, Gemini, and Claude. Note where your brand appears, where competitors appear, and which sources each engine cites. What you're looking for is consistency — does your brand appear across all four engines for the same core prompts, or does your visibility collapse to one or two?
Citation consistency across LLMs is the strongest leading indicator of durable AI search visibility. Brands that appear across multiple engines for the same prompts are drawing from structural content properties that multiple model architectures independently recognize as authoritative. That's a much harder signal to fake than single-engine optimization.
The practical implication: if you're only tracking one engine, you're measuring a sample, not a signal. Claude visibility and Grok patterns often diverge from ChatGPT in ways that reveal gaps in how your content is structured, not just where it's distributed. Cross-engine consistency is the diagnostic. Single-engine performance is noise.
Curious which AI engines are citing your competitors but not you?
Signal 2. Prompt Coverage Depth
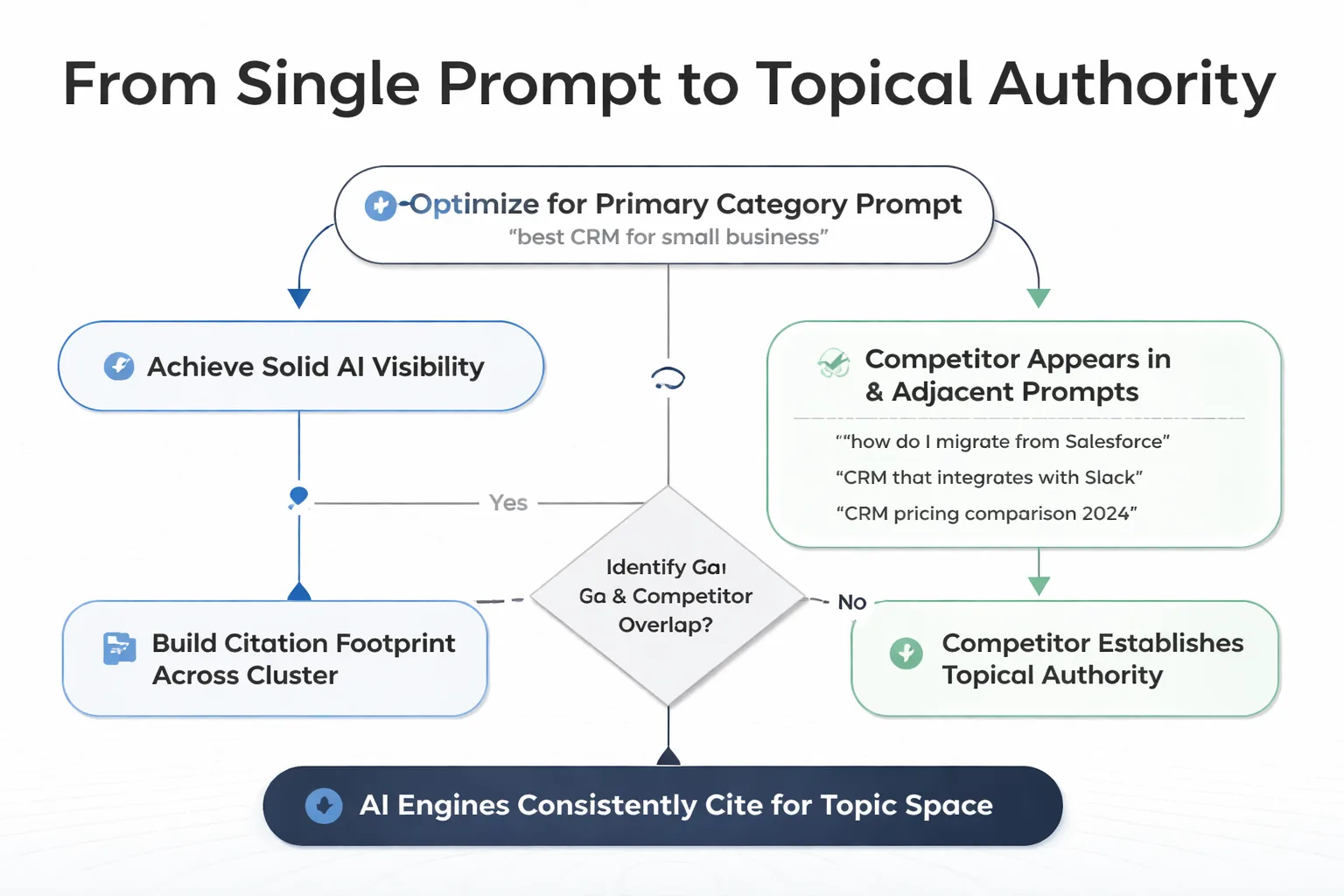
Ranking for one prompt is not topical authority. This is the signal most content teams underestimate.
Here's the pattern I keep seeing: a brand optimizes heavily for their primary category prompt ("best CRM for small business," for example) and achieves solid AI visibility there. Then a competitor starts appearing in the adjacent prompts — "how do I migrate from Salesforce," "CRM that integrates with Slack," "CRM pricing comparison 2026" — and quietly builds a citation footprint that the first brand doesn't even know exists. By the time the first brand notices, the competitor has established topical authority across the cluster, and the AI engines have developed a consistent pattern of citing them for anything in that space.
Prompt coverage depth measures how many of the prompts in your topic cluster you're actually appearing in, versus how many your competitors are filling. The audit process: map every prompt type in your category (head terms, comparison prompts, use-case prompts, objection prompts, pricing prompts, migration prompts), run each one across your target AI engines, and score which brand appears most consistently. What you're building is a prompt coverage map. A visual representation of where you own citation share and where you're absent.
The gaps in that map are the highest-ROI content opportunities in your entire strategy. Not because they'll improve your Google rankings (they might), but because AI engines build topical models of which sources are authoritative for which subtopics. If a competitor is filling the "how to migrate from X" prompt cluster and you're not, the AI has learned to associate them with that problem space. Recovering that association requires consistent, structured content that directly addresses those prompts. Not general category content.
One number that grounded this for me: according to Semrush's analysis of 150,000+ LLM citations, Reddit leads all citation sources at 40.1% frequency, with Wikipedia second at 26.3%. Brand content is competing for a fraction of the remaining share. That means prompt coverage depth matters even more than it would in a world where brand content dominated. You're fighting for a smaller pool, so owning more of the relevant prompts is the only way to build a defensible position.
Signal 3. Content Freshness Signals in AI Indexes
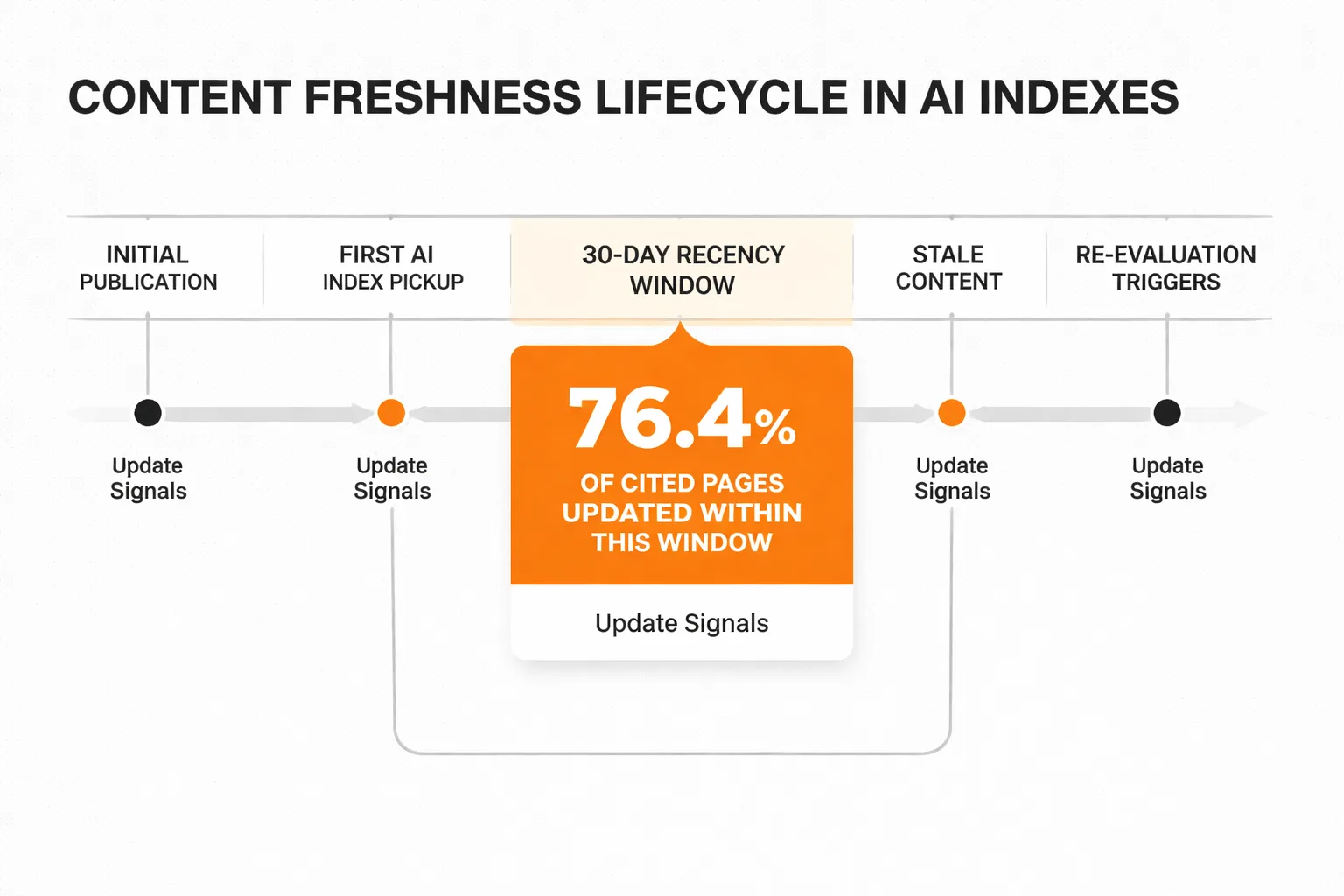
Stale content loses citation slots. This is not a hypothesis. It's a documented pattern.
Analysis of ChatGPT's most-cited pages found that 76.4% were updated within 30 days of being cited, according to data surfaced in ZipTie's review of E-E-A-T signals for AI search. That number stopped me cold when I first encountered it. It means the recency window for AI citation is dramatically shorter than the recency window for organic search, where a well-established page can hold rankings for years without updates.
The mechanism is different across engine types. Google AI Overviews has a crawl-based architecture that's relatively similar to traditional search. If Googlebot has re-crawled your page recently, the AI Overview system has fresher signals to work with. Perplexity is more aggressive about real-time retrieval, which is part of why it leans so heavily on Reddit (40.1% citation frequency per Semrush data) — forum threads get new activity constantly, which keeps them fresh in retrieval systems that weight recency.
For brand content, the practical implication is that a publish-and-forget strategy actively hurts AI search visibility over time. A page that earned citations six months ago and hasn't been touched since is competing against fresher sources that have been updated since then. The AI doesn't know your page was authoritative in November. It's evaluating what's authoritative now.
What triggers re-evaluation in AI indexes? Based on the patterns I've tracked: substantive content updates (adding new data, new sections, or updated statistics), new inbound links from cited sources, and schema markup changes that signal structured updates. Cosmetic edits (fixing typos, changing a headline) don't appear to move the needle. The update needs to add information gain. Something the previous version didn't contain.
The actionable framework here is a quarterly content refresh cycle specifically targeting your highest-performing AI-cited pages. Not a full rewrite. A targeted update: add the most recent data point available, update any statistics that have newer versions, add a section addressing a question that's emerged in the topic cluster since publication. That's enough to reset the freshness signal without requiring the resource investment of a full content rebuild.
Signal 4. E-E-A-T Proxy Indicators in LLM Outputs

AI engines cannot verify your credentials. They infer them.
That distinction matters more than most content strategies account for. When a human editor evaluates E-E-A-T, they can click through to an author's LinkedIn, check their publication history, verify their institutional affiliation. An LLM can't do any of that in real time. What it can do is look for proxy signals — structural and contextual markers that correlate with genuine expertise in its training data.
Analysis of 2,400 AI Overview citations found that 96% came from sources with strong E-E-A-T signals, according to Wellows' citation research cited by ZipTie. The same analysis found that content with schema markup appears 3-5x more often in AI recommendations, and that pages with quantitative claims get cited at a 40% higher rate than pages with purely qualitative statements. These aren't soft preferences. They're structural biases in how AI engines evaluate source credibility.
The four proxy indicators that move the needle most:
Author entity signals. Does your content have a named author with a consistent publication history across your domain? AI engines track entity consistency. An author who appears across 20 articles on a topic cluster builds a stronger authority signal than anonymous or rotating bylines. This is why author entity profiles matter in content systems that are publishing at scale.
Third-party mentions. AI engines are 6.5x more likely to cite content that has been referenced by external sources, per the ZipTie analysis. This is the closest proxy to traditional link-building, but the target is different: you want citations from the domains AI engines already trust, not just high-DA sites. Finding which publishers AI engines actually cite for your topics. And building a presence on those platforms. Is a more targeted strategy than generic link acquisition.
Structured data. Schema markup functions as a machine-readable credential. FAQ schema, Article schema, HowTo schema. These signal to AI engines that your content is structured for extraction, not just for human readers. The 3-5x citation lift for schema-marked content is the most actionable single-implementation win available to most content teams right now.
Original research and quantitative claims. 67% of ChatGPT's top citations come from first-hand or original research, per the ZipTie data. If your content is primarily synthesizing what others have said, you're competing for the remaining 33% of citations against every other secondary source on the web. Original data. Even a small survey, a proprietary analysis, a dataset from your own product. Creates a citation anchor that secondary content can't replicate.
For teams tracking Google AI Overviews performance specifically, the E-E-A-T proxy signals overlap significantly with Google's Helpful Content system criteria. But the weighting is different: structured data and original research matter more for AI citation than they do for traditional organic rankings, while keyword optimization matters less. That's a meaningful strategic shift for teams that have historically optimized primarily for organic.
The Contrarian Take on LLM Citation Building
Here's what the entire AI visibility industry is getting wrong: most of the "citation building" playbooks being sold right now assume that getting your brand mentioned in more places will cause LLMs to start citing you more. I've spent time looking for documented cases where a brand mention outreach campaign actually caused an LLM to start attributing content correctly to a specific brand. As of mid-2026, I haven't found a single verified example.
What the research actually shows is that LLM citation patterns are driven by structural content properties. Freshness, schema, original research, cross-platform consistency. Not by the volume of brand mentions in secondary sources. The hallucinations and citation errors that researchers are documenting trace back to training data architecture failures, not to whether your brand appeared in 40 niche blog posts this quarter.
I'm not saying outreach has zero value. Getting cited by the publishers AI engines already trust (Reddit communities, Wikipedia, high-authority vertical publications) is genuinely useful. But the specific claim that broad brand mention campaigns move LLM citation rates is unvalidated. Teams should stop treating it as a controllable lever the way we treat, say, schema implementation or content freshness. Those have documented, quantifiable effects. Brand mention volume does not.
The four signals above are the ones with actual predictive validity. Citation consistency across LLMs, prompt coverage depth, content freshness, and E-E-A-T proxy indicators. These are the variables that, when improved, produce measurable shifts in AI search visibility. An ai search visibility tool that tracks all four across engines gives you a diagnostic framework. Tracking mention volume without these signals gives you a number that feels meaningful but predicts nothing.
Frequently Asked Questions
How is AI search visibility different from traditional SEO rankings?
Traditional SEO measures where your pages rank in a list of blue links. AI search visibility measures whether AI engines mention, cite, or recommend your brand when answering user questions. And how those appearances are framed. A brand can rank on page one for a keyword and still be absent from AI responses for the same topic, because the two systems evaluate content through different criteria.
How many prompts should I track to get a reliable visibility baseline?
The minimum viable prompt set for a meaningful baseline is 20-30 prompts distributed across your topic cluster: 5-8 head category prompts, 8-10 comparison and use-case prompts, and 5-8 decision-stage prompts (pricing, migration, objection handling). Running fewer than 20 prompts produces a sample too small to distinguish consistent visibility from lucky appearances.
Does Google AI Overviews optimization differ from Perplexity optimization?
Yes, significantly. Google AI Overviews has roughly 54% overlap with organic rankings, so strong organic positions translate more directly to AIO visibility. Perplexity draws 47% of its citations from Reddit and weights real-time retrieval heavily. Meaning conversational, community-validated content outperforms polished brand content there. You need separate content tracks for each engine, not a single unified strategy.
How often should I update content to maintain AI citation freshness?
The 30-day recency window in ChatGPT citation data suggests a monthly update cadence for your highest-priority pages. That doesn't mean full rewrites. Substantive additions (new statistics, a new section addressing an emerging question, updated data points) are sufficient to reset freshness signals. Quarterly deep reviews plus monthly lightweight updates is the framework I'd recommend for most teams.
What's the fastest E-E-A-T proxy improvement to implement?
Schema markup. The 3-5x citation lift for schema-marked content is the highest-ROI single implementation available, and it requires no content changes. Just technical implementation. Start with Article schema on all existing content, then layer in FAQ schema for pages with Q&A structure and HowTo schema for instructional content. Most teams can complete this implementation in a single sprint.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Track your citation consistency across ChatGPT, Perplexity, Gemini, and Claude — and find the prompt gaps your competitors are quietly filling.