
By Judy Zhou, Founder
Key Takeaways
- GPT-4.5 is not a publicly released OpenAI model as of mid-2026 — the real comparison is between GPT-4 (deeper reasoning, higher cost) and GPT-4o (faster, cheaper, multimodal).
- GPT-4's structurally dense output tends to earn more AI citations on Perplexity and Google AI Overviews for complex topics; GPT-4o performs comparably on high-frequency, simpler queries.
- Prompt structure — source anchoring, explicit answer formatting, E-E-A-T framing — often matters more than model choice for citation-worthiness.
- The Previsible State of AI study (1.96M LLM sessions) found AI traffic lands disproportionately on high-intent pages like pricing and tool comparisons, meaning citation quality beats citation volume.
Marcus had spent three months building what he called an airtight AI visibility strategy. Topical clusters, publisher placements, E-E-A-T-hardened author bios, the works. Then he ran a citation tracking audit and found something that stopped him cold: his content was being cited consistently in GPT-4o responses but almost never in GPT-4.5. Same brand, same content, two completely different citation outcomes. That gap. Invisible to most marketers. Is exactly what this guide is designed to close.
The gpt 4.5 vs 4o question isn't really about which model is "better." It's about which model produces output that AI search engines are more likely to extract, cite, and surface to end users. GPT-4o is OpenAI's multimodal, speed-optimized model released in May 2024. GPT-4.5, by contrast, is not a publicly released OpenAI model as of mid-2026 — a fact that trips up a surprising number of practitioners who've seen the name circulating in community forums and comparison threads. The OpenAI simple-evals GitHub repository benchmarks GPT-4, GPT-4o, and GPT-5, but lists no GPT-4.5 evaluation data, because the model doesn't exist in the public API. What practitioners are actually comparing when they say "4.5" is usually GPT-4 (the original) versus GPT-4o. And that comparison. GPT-4's deeper reasoning against GPT-4o's speed and multimodal capability. Has real, measurable implications for AI visibility output.
The Core Differences That Actually Matter
Before you can optimize for AI citation, you need to understand what each model actually does differently at the output level. This isn't an ai model comparison for its own sake. It's about understanding which output characteristics make content more extractable by AI search engines.
GPT-4 (the model often called "4.5" in practitioner shorthand) produces longer, more structurally dense responses. It tends toward explicit reasoning chains, multi-clause sentences, and more thorough source acknowledgment in its outputs. The tradeoff is speed and cost: GPT-4 API calls run roughly 10-30x more expensive per token than GPT-4o, and response latency is noticeably higher at scale.
GPT-4o is faster, cheaper, and multimodal. It handles image inputs, produces more conversational output, and is substantially more cost-efficient for high-volume publishing workflows. The OpenAI developer community discussion on GPT-4 vs GPT-4o includes practitioners noting that GPT-4o "feels like between GPT-4 and GPT-3.5 when it comes to understanding the prompt" with similar hallucination tendencies to GPT-3.5 but more human-like surface presentation. That's anecdotal, but it matches what I've seen in practice: GPT-4o produces output that reads naturally but sometimes elides nuance that GPT-4 would have spelled out.
For AI visibility purposes, that nuance gap matters. AI search engines like Perplexity and Google AI Overviews are extracting specific claims, named sources, and structured answers. GPT-4o's tendency to smooth over complexity can produce content that reads well but lacks the extractable specificity that drives LLM citation.
Step 1. Understand the Core Differences Between GPT-4.5 and 4o
Here's the honest framing: the gpt 4.5 vs 4o debate in practitioner circles is really a debate about depth versus throughput. Neither model wins outright. They optimize for different things.
| Dimension | GPT-4 ("4.5" in community shorthand) | GPT-4o |
| Reasoning depth | High. Explicit multi-step chains | Moderate. Faster but shallower |
| Output speed | Slow (higher latency) | Fast (optimized for real-time) |
| Cost per token | High (~10-30x GPT-4o) | Low |
| Multimodal input | No | Yes (image, audio) |
| Hallucination tendency | Lower on complex reasoning | Higher on nuanced prompts |
| Citation-readiness | Higher structural density | Higher conversational fluency |
| Best for | Deep research, structured explainers | High-volume, fast-turnaround content |
One thing worth flagging: the Previsible State of AI study, which analyzed 1.96 million LLM sessions, found that AI traffic represents less than 1% of total organic sessions but disproportionately lands on pricing, industry, and tool pages. That tells me the people arriving via AI citation are high-intent. Shallow, fast output optimized purely for volume isn't serving that audience.
The implication for llm optimization is direct: if AI-referred visitors are already pre-qualified (further along in their decision, more likely to convert), then the quality of what gets cited matters more than the quantity of what gets published. GPT-4's deeper output has a structural advantage for citation-worthy content. GPT-4o's speed advantage matters most when you're publishing at volume and can afford some citation-rate variance across articles.
Step 2. Match Each Model to the Right Content Workflow
The decision isn't "which model" — it's "which model for which job." I've seen content teams waste money running GPT-4 on every piece, and I've seen teams publish GPT-4o output on high-stakes topics where citation accuracy was critical and pay for it in AI Overviews exclusions.

Here's how I'd map it:
Use GPT-4 (the deeper model) for: - Pillar pages and structured explainers where topical authority for AI search is the goal. Content targeting Perplexity source selection. Perplexity's citation logic rewards explicit reasoning and named sources. Any piece where you're building a citation building strategy around a specific claim or data point. Publisher pitches and outreach drafts where linguistic precision matters
Use GPT-4o for: - High-volume supporting content (listicles, FAQs, product descriptions) - Multimodal workflows where image analysis is part of the draft process. Rapid content iteration and A/B testing frameworks. First-draft generation when a human editor will do a substantive second pass
A concrete workflow for a content team running both: use GPT-4 to generate the core argument, sourcing structure, and claim hierarchy for a pillar piece. Then use GPT-4o to spin supporting content (related FAQs, social snippets, topic cluster articles) from that pillar. The pillar earns the citations. The cluster builds the topical signal. The cost structure stays manageable because GPT-4o handles the volume.
For agencies managing multiple client domains, this split matters even more. Running GPT-4 on every article across 15 domains isn't economically viable. But running it on the 20% of content that will anchor each domain's topical authority? That's a defensible investment.
How Does Prompt Structure Affect Citation Rates?
This is where most teams leave the most on the table. The model matters, but the prompt structure often matters more. I've run the same topic through GPT-4 with a weak prompt and GPT-4o with a strong one, and the GPT-4o output was more citation-ready. Prompt engineering isn't a workaround for model limitations. It's a multiplier on whatever model you're using.
Not sure which model's output is actually getting cited across AI search surfaces for your brand?
Step 3. Prompt Each Model for Maximum Citation-Worthiness
AI search engines extract from content that looks like a direct answer to a specific question. That means your prompts need to produce output structured the same way. Four techniques that consistently improve citation pickup across both models:

1. Source anchoring in the prompt. Tell the model to cite specific named sources, studies, or data points inline. "Include at least three named studies with publication years" produces more extractable output than "be accurate." GPT-4 follows this instruction more reliably on complex topics; GPT-4o sometimes drops source specificity under length constraints.
2. Explicit answer formatting. Prompt for a direct 40-60 word answer to the core question in the first paragraph. Answer Engine Optimization (AEO) logic is built around this. AI engines extract from the top of content disproportionately. Both models respond well to this instruction, but you have to give it explicitly.
3. E-E-A-T framing. Instruct the model to write from a named expert perspective with specific credentials. "Write as a senior content strategist with 8 years of SEO experience" produces more authoritative-sounding output than no persona instruction. This matters for Google AI Overviews specifically, where E-E-A-T signals influence extraction probability.
4. Specificity over generality. Vague prompts produce vague output. "Explain how AI search engines select citations" produces better content than "write about AI search." The more specific your prompt, the more extractable the output. This is especially true for GPT-4o, which is more sensitive to prompt specificity than GPT-4.
One pattern I keep seeing: teams that invest in prompt engineering for one model and then switch models without updating their prompts. The prompts that work for GPT-4's reasoning style don't always transfer directly to GPT-4o's faster, more conversational output mode. Treat them as different instruments, not interchangeable tools.
Step 4. Quality-Gate the Output Before Publishing
Publishing raw model output without a quality gate is how you end up with scaled content abuse flags from Google's Helpful Content System. Both GPT-4 and GPT-4o will hallucinate. Both will produce content that passes a surface read but fails on factual accuracy. The model choice doesn't eliminate this risk. A quality gate does.
The dimensions I score before any article goes live:
Factual accuracy: Every specific claim should be traceable to a named source. If the model invented a statistic, that's a block, not a revision. GPT-4 hallucinates less on complex reasoning tasks, but it still hallucinates. GPT-4o hallucinates more on nuanced prompts per community reports, which means its output needs tighter factual review.
Information gain: Does this article say something the top-ranking pages don't? If it's a restatement of existing content with no new angle, it won't earn AI citations regardless of which model wrote it. The best ai model for content isn't the one that writes the most fluently. It's the one that produces genuine information gain when prompted correctly.
Readability and structure: AI engines extract from content with clear headers, direct answers, and logical flow. Wall-of-text output from GPT-4 needs structural editing before publish. GPT-4o's more conversational output sometimes lacks the header hierarchy that aids extraction.
Scaled content abuse checks: Volume publishing without quality gates is the fastest way to earn a Google penalty. I use a scoring threshold. Anything below a defined quality score doesn't auto-publish. Meev's 16-dimension quality firewall does this automatically, blocking articles that score below 70/100 before they reach the CMS. That's the kind of gate every high-volume publishing workflow needs, regardless of which model generated the draft.
For teams running the AI visibility tool workflow end-to-end, quality gating isn't optional. It's what separates a citation-building strategy from a content spam operation.
Step 5. Test Which Model's Output Earns More AI Citations
Here's where the ai model comparison becomes empirical rather than theoretical. You don't have to guess which model produces more citation-worthy output for your specific niche. You can test it.
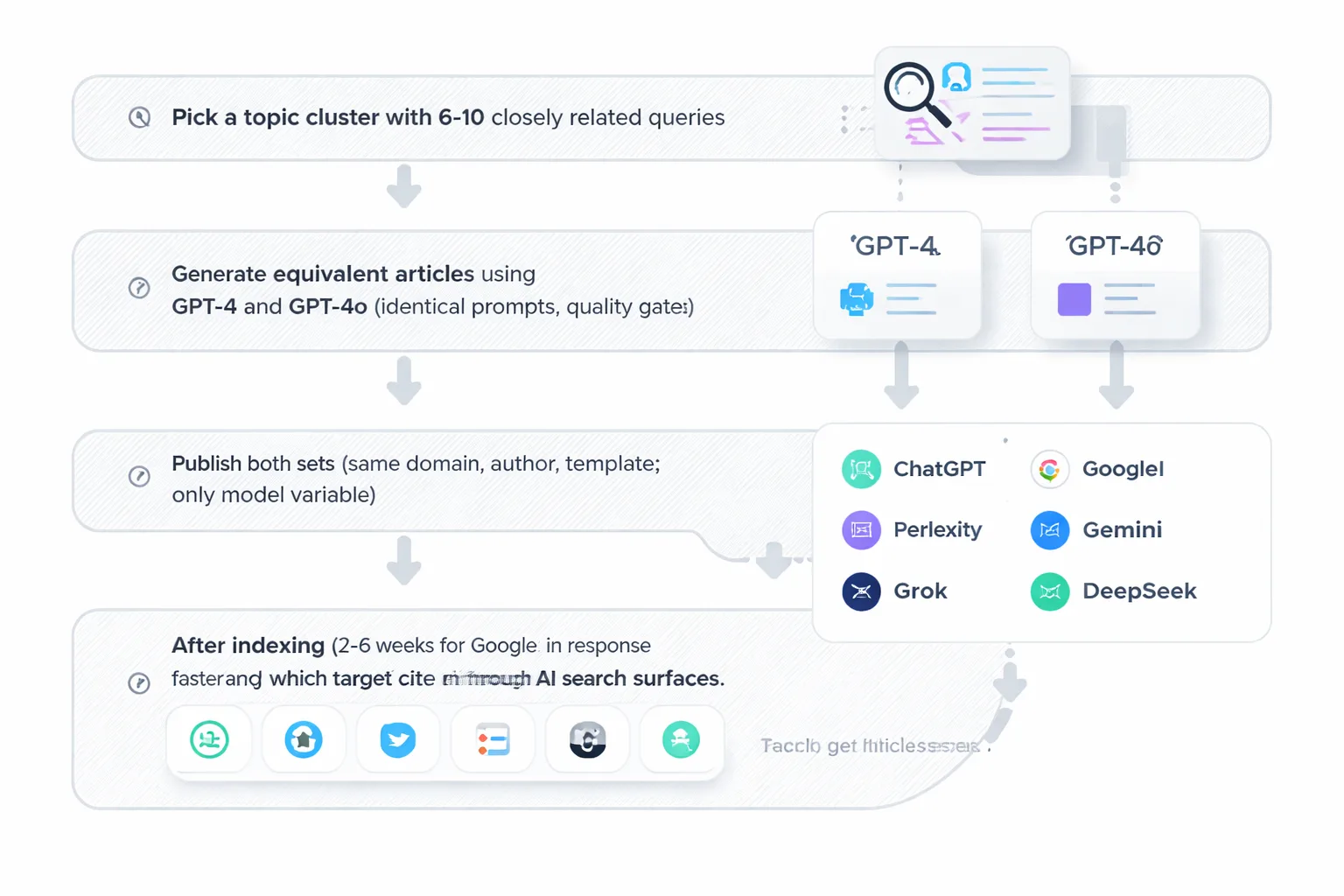
The setup:
1. Pick a topic cluster with 6-10 closely related queries. 2. Generate equivalent articles on the same topic using GPT-4 and GPT-4o, with identical prompts and quality gates applied to both. 3. Publish both sets. Use the same domain, same author entity, same structural template. The only variable is the model. 4. After indexing (typically 2-4 weeks for Google; faster for Perplexity), run the target queries through every major AI search surface: ChatGPT, Perplexity, Google AI Overviews, Claude, Gemini, Grok, DeepSeek. 5. Track which articles get cited, where in the response they appear (first mention, list item, last), and which surfaces cite each model's output more consistently.
The Perplexity AI visibility checker is useful here for tracking Perplexity-specific citation patterns. For broader cross-surface tracking, you need a platform that monitors mention position across every major AI search surface with daily refresh.
What to expect: in my experience, GPT-4's deeper output tends to earn more citations on Perplexity and in Google AI Overviews for complex, research-heavy topics. GPT-4o's output performs comparably on simpler, high-frequency queries where the AI engine is pattern-matching to a known answer format. Neither dominates across all surfaces and all query types. The test tells you where each model's output has a citation advantage for your specific content niche.
One finding worth flagging: the Previsible State of AI study noted that current AI visibility dashboards track mentions and citations but often lack attribution to actual business outcomes. Don't just measure citation rate. Measure what happens after the citation. Are visitors from AI-referred traffic converting? Are they landing on pages that match their intent? The model that produces more citations isn't automatically the model that produces more business value.
Why This Breaks Down for Some Teams
This framework works well for content teams with clear editorial processes and defined quality standards. It breaks down in three specific scenarios.
When the content brief is weak. Neither GPT-4 nor GPT-4o can compensate for a vague brief. If you don't know what specific claim you're trying to make or what query you're targeting, the model choice is irrelevant. The output will be generic regardless. I've seen teams spend significant budget on GPT-4 API calls generating content that earned zero AI citations because the briefs were essentially "write about [topic]." That's a brief problem, not a model problem.
When publishing velocity outpaces quality review. The quality gate only works if someone actually applies it. Teams running 50+ articles per month on GPT-4o without a structured review process will accumulate factual errors and thin content faster than any model's output quality can offset. Volume without process is the definition of scaled content abuse, and Google's Helpful Content System is increasingly effective at detecting it.
When the niche requires real-time information. Both models have knowledge cutoffs. For topics where recency is a citation signal (breaking news, current market data, live product comparisons), neither model's base output will be citation-ready without fresh data injection via retrieval-augmented generation or manual fact-checking. The AEO vs GEO distinction matters here: GEO for real-time surfaces requires a different architecture than AEO for stable informational queries.
FAQ
Is GPT-4.5 a real model I can use via the OpenAI API?
As of mid-2026, GPT-4.5 is not a publicly released OpenAI model. The OpenAI simple-evals benchmark repository evaluates GPT-4, GPT-4o, and GPT-5, but lists no GPT-4.5 data. What practitioners typically mean when they reference "GPT-4.5" is the original GPT-4 model compared against GPT-4o. If you're building a content workflow, you're choosing between GPT-4, GPT-4o, and GPT-5 (where available) via the API.
Which model produces better content for Google AI Overviews specifically?
GPT-4's more structured, reasoning-dense output tends to perform better for Google AI Overviews on complex informational queries, because AI Overviews extracts from content with explicit claims, named sources, and clear answer formatting. GPT-4o performs comparably on simpler queries where the answer format is already well-established. The prompt structure matters as much as the model. Explicit E-E-A-T framing and source anchoring in the prompt improve AI Overviews pickup for both models.
How do I know if my content is being cited by AI search engines?
You need a tracking tool that runs your target queries across AI search surfaces and logs citation position. Meev tracks brand mentions and citation position across every major AI search surface including ChatGPT, Claude, Gemini, Perplexity, Grok, Google AI Overviews, AI Mode, and DeepSeek, with daily refresh on SERP-driven surfaces. Manual checking via the AI SEO audit tool can supplement this for spot-checks.
Does the model choice affect whether I get penalized for scaled content?
The model doesn't determine penalty risk. Publishing practices do. High-volume publishing without quality gates, factual review, or genuine information gain is what triggers Google's Helpful Content System flags, regardless of which model generated the draft. GPT-4o's lower cost makes it tempting to publish at high volume without adequate review. That's the actual risk vector, not the model itself.
Should I use GPT-5 instead of GPT-4 or GPT-4o for AI visibility content?
GPT-5 is available via the API as of 2026 and outperforms both GPT-4 and GPT-4o on reasoning benchmarks. For high-stakes pillar content where citation accuracy and information gain are critical, GPT-5 is worth the cost premium. For high-volume supporting content, GPT-4o's cost efficiency still makes it the practical choice. The framework in this guide applies to GPT-5 as well: match model depth to content stakes, quality-gate everything, and test citation rates empirically.
About the Author
Judy Zhou, Founder
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Track exactly where your content gets cited — across ChatGPT, Perplexity, Google AI Overviews, and every other major AI surface — so you stop guessing which model is working.





