
By Judy Zhou, Head of Content Strategy
Key Takeaways
- Only 11% of domains are cited by both ChatGPT and Perplexity, meaning citation eligibility is platform-specific — not just a content quality problem.
- Standard LLM leaderboard benchmarks measure reasoning and coding, not the structured output reliability and factual grounding that content workflows actually require.
- 76% of pages cited in Google AI Overviews already rank in Google's top 10, so AI visibility and traditional SEO are more aligned than most teams assume.
- The model matters less than the quality gate: a mid-tier model with a strong quality firewall consistently outperforms a frontier model with no gate at production scale.
Marcus had spent six months building topical authority for his SaaS client. Structured content, expert attribution, clean E-E-A-T signals, the full playbook. Then a competitor appeared in three consecutive ChatGPT responses for the exact queries his client owned. The competitor wasn't ranking higher on Google. They hadn't published more content. But somewhere in the training data, in the citation logic, in the source selection patterns of a model Marcus had never thought to track, they had quietly become the default answer. That was the moment he stopped reading benchmark leaderboards.
The ai model comparison problem isn't that the benchmarks are wrong. It's that they're measuring the wrong things. Most leaderboards rank models on reasoning tasks, math olympiad problems, and coding challenges. None of that predicts whether a model will produce citation-ready output, follow a structured brief, or generate content that doesn't trigger Google's scaled content abuse detection. For content teams and agencies trying to build AI search visibility in 2026, the standard rankings are close to useless.
Key claims upfront: Only 11% of domains are cited by both ChatGPT and Perplexity, meaning the model you use to generate content affects which citation pool you're even eligible for. 76% of pages cited in AI Overviews rank in Google's top 10, per a Seer study on page-one rankings and LLM mentions. Pages cited in AI Overviews earn 35% more organic clicks than non-cited competitors. And Perplexity visitors convert at 11x the rate of traditional organic search, which means citation placement is a revenue lever, not just a vanity metric.
Why AI Model Rankings Keep Misleading Content Teams
The leaderboard industrial complex has a real problem: it optimizes for what's measurable, not what's useful. Benchmarks like MMLU, HumanEval, and HellaSwag test abstract reasoning and knowledge recall. They don't test whether a model can generate a 1,200-word how-to article that passes a quality firewall, maintains factual grounding across 15 source citations, and produces structured output a CMS can ingest without manual cleanup.
I've watched content teams make expensive model decisions based on Chatbot Arena scores or the latest LLM Leaderboard 2026 rankings, then spend weeks debugging why their auto-published articles are getting flagged for thin content or why their FAQ schema is malformed. The benchmark said the model was smarter. The production pipeline said otherwise.
The deeper issue is that leaderboard rankings conflate general intelligence with task-specific reliability. A model that scores in the 95th percentile on reasoning benchmarks may still hallucinate source URLs, ignore system prompt constraints, or produce output that structurally resembles AI-generated content in ways Google's classifiers can detect. For content workflows specifically, instruction-following consistency matters more than raw intelligence. A model that reliably follows a 2,000-token brief at 90% fidelity beats a smarter model that follows it 60% of the time, every time.
There's also a citation eligibility dimension that almost nobody talks about. Different models have different training data cutoffs, different source weighting patterns, and different tendencies toward certain domains. The AI Platform Citation Source Index 2026 analysis covering 680 million citations found that only 11% of domains are cited by both ChatGPT and Perplexity. That's not a content quality gap. That's a structural difference in how each model selects sources. If you're generating content with a model that's architecturally closer to one citation pool than another, your output is already pre-sorted into a visibility tier before anyone reads it.
The Metrics That Actually Matter for Content and GEO Workflows
Four dimensions actually predict model performance for content and generative engine optimization work. Not benchmark scores. These four.
Structured output reliability is the first one. Can the model consistently produce JSON, markdown with correct heading hierarchy, FAQ schema, and HowTo markup without hallucinating fields or breaking structure mid-output? This sounds trivial. It isn't. At scale, a model that produces malformed schema 8% of the time means 8% of your published articles have broken structured data. That compounds fast across a portfolio of sites.
Factual grounding is the second dimension, and it's where most teams underestimate the variance between models. Factual grounding isn't just about whether a model knows the right answer. It's about whether the model knows when it doesn't know, and whether it will fabricate a plausible-sounding citation rather than admit uncertainty. For content that needs to cite real studies, real statistics, and real named sources, a model with strong grounding will hedge or ask for clarification. A model with weak grounding will invent a convincing DOI. The difference between those two behaviors is the difference between content that builds E-E-A-T signals and content that destroys them.
Context window utilization is the third metric, and it matters specifically for long-form drafting. A 128K context window doesn't mean a model uses all 128K effectively. Several frontier models show measurable quality degradation past the 40K-60K token range, producing repetitive phrasing, losing thread on earlier constraints, or simply ignoring instructions that appeared early in the prompt. For agencies running auto-blog workflows with large knowledge bases, the effective context window (not the advertised one) determines whether the model can hold your brand voice, your E-E-A-T author profile, and your topic brief simultaneously.
Cost-per-token at production scale is the fourth dimension, and it's the one that determines whether a content strategy is actually sustainable. The gap between frontier model pricing and mid-tier model pricing has narrowed significantly in 2026, but it hasn't closed. At 80 articles per month across 5 domains, the difference between a $15/million-token model and a $3/million-token model is real budget. The question isn't which model is cheapest. It's which model clears your quality threshold at the lowest cost per passing article.

Want to know which AI engines are actually citing your content right now?
Head-to-Head: How Top Models Perform on Content Tasks
I'm going to be specific here, because vague model comparisons are useless. Here's how the four models content teams most commonly ask about actually perform on the workflows that matter.
GPT-4o is the most consistent instruction-follower in the group for structured content tasks. System prompt adherence is high. JSON output reliability is high. The weakness is factual grounding at the edges of its training data. For topics that require citing recent studies or 2026 data, GPT-4o will sometimes produce citations that look real but aren't. If you're running a quality-gated publishing workflow, you need fact-verification as a separate layer, not an assumption. The model is also the most expensive of the four at production scale, which matters if you're running bulk drafting across a large domain portfolio.
Claude Opus 4 is the strongest performer on long-form coherence and argumentation. If you're producing depth-first content designed for LLM citation, Claude's tendency toward nuanced, hedged, experience-adjacent writing actually aligns well with what I've seen Perplexity and ChatGPT pull from. The pattern I keep seeing is that Claude-generated content, when properly briefed with a knowledge base, produces output that reads more like the Reddit threads and first-person experience posts that dominate citation pools. The weakness is that Claude is more likely to push back on or reinterpret a brief it finds restrictive. For teams running tightly constrained templates, that unpredictability is a real operational cost.
Gemini 1.5 Pro has the most genuine multimodal integration of the group, which matters if your content workflow involves image alt text generation, video transcript summarization, or visual content briefs. For pure text content tasks, it sits slightly below GPT-4o on instruction-following consistency but meaningfully above Llama 3. The context window performance is genuinely strong. In my experience, Gemini degrades less than GPT-4o past the 60K token mark, which makes it worth evaluating for long-form workflows with large knowledge base inputs. Its Google ecosystem integration also means content generated with Gemini may have structural alignment advantages for Google AI Overviews optimization, though I'd treat that as a hypothesis worth testing rather than a confirmed pattern.
Llama 3 (and its fine-tuned variants) is the right answer for exactly one content use case: high-volume, cost-sensitive bulk drafting where you're running your own quality gate. The base model's instruction-following is inconsistent enough that you can't run it without a quality firewall. But the cost profile makes it viable for teams that can absorb that operational complexity. If you're producing 150+ articles per month and you have a 16-dimension quality gate blocking weak drafts before they hit your CMS, Llama 3 variants can dramatically reduce your per-article cost without sacrificing the published output quality.
| Model | Structured Output | Factual Grounding | Context Endurance | Cost Tier | Best Use Case |
| GPT-4o | ★★★★★ | ★★★☆☆ | ★★★★☆ | High | Quality-gated publishing, AEO formatting |
| Claude Opus 4 | ★★★★☆ | ★★★★★ | ★★★★☆ | High | Depth-first GEO content, citation-ready long-form |
| Gemini 1.5 Pro | ★★★★☆ | ★★★★☆ | ★★★★★ | Medium | Long-form with large KB inputs, multimodal workflows |
| Llama 3 | ★★★☆☆ | ★★★☆☆ | ★★★☆☆ | Low | Bulk drafting behind a quality firewall |
The contrarian take here: most content teams are over-invested in frontier model selection and under-invested in quality gates. The model matters less than whether you have a reliable mechanism for blocking weak output before it publishes. A mid-tier model with a strong quality firewall will outperform a frontier model with no gate, every time, at scale. That's not a comfortable conclusion for teams that want a simple "use this model" answer, but it's what the production data consistently shows.
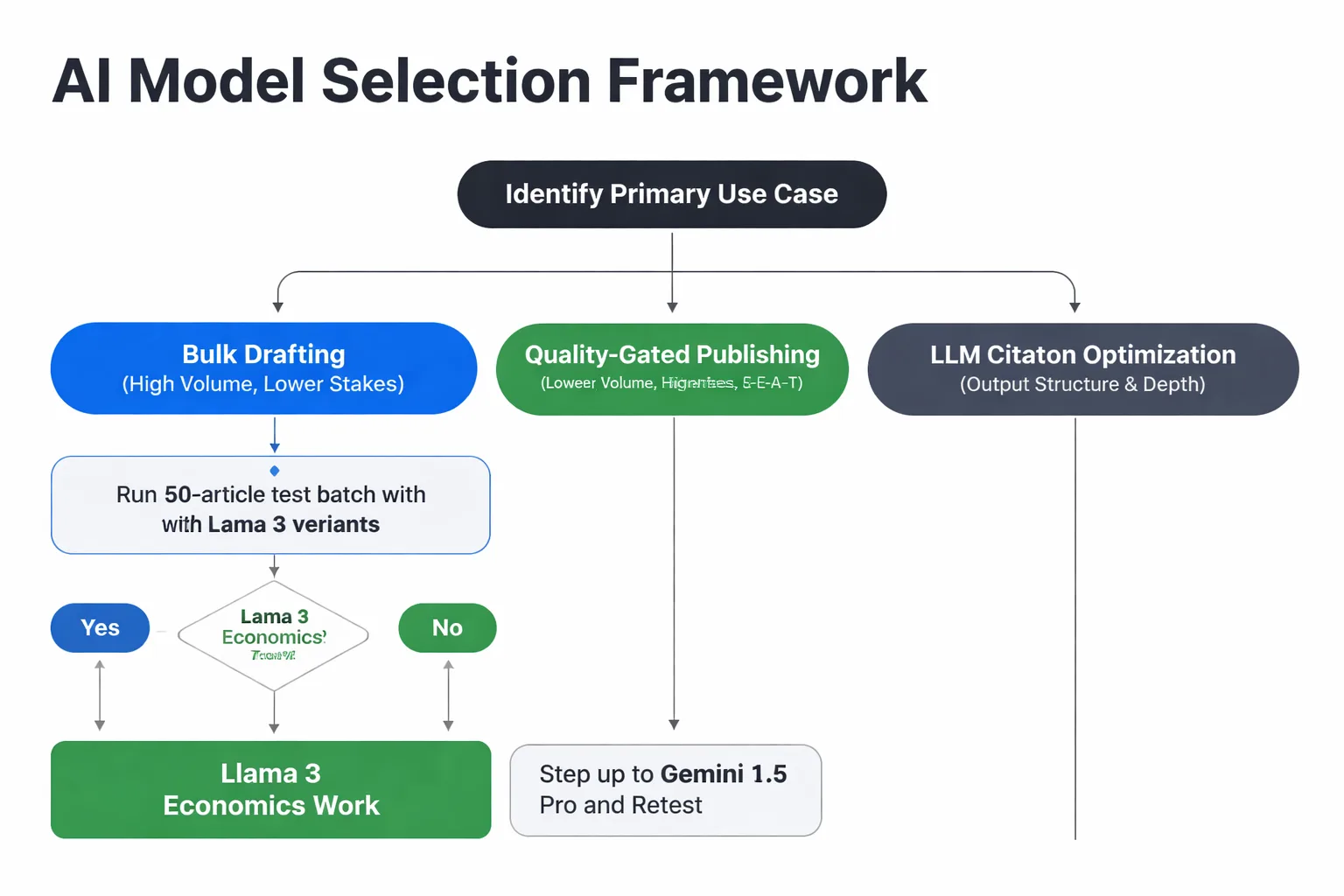
How to Pick the Right Model for Your AI Content Stack
The decision framework isn't complicated, but it requires being honest about your actual workflow constraints.
Start with your primary use case. Bulk drafting (high volume, lower per-article stakes) has different requirements than quality-gated publishing (lower volume, higher stakes per piece) or LLM citation optimization (where output structure and depth matter more than volume). Most teams are trying to do all three with the same model and the same prompt, which is why results are inconsistent.
For bulk drafting behind a quality gate, the right answer is almost always the cheapest model that clears your quality threshold. Run a 50-article test batch with Llama 3 variants and measure your pass rate through your quality firewall. If 70%+ pass, the economics work. If you're seeing 40% pass rates, step up to Gemini 1.5 Pro and retest. The quality gate is doing the work. The model is just generating candidates.
For quality-gated publishing where E-E-A-T signals matter, you need GPT-4o or Claude Opus 4. The instruction-following consistency of GPT-4o means your author entity profiles, brand voice constraints, and structured data requirements will actually land in the output. Claude Opus 4 is the better choice if your content strategy leans on depth and argumentation over template adherence.
For LLM citation optimization, this is where model selection gets genuinely interesting. The Seer study finding that 62% overlap exists between Google rankings and ChatGPT visibility means your Google ranking strategy and your AI visibility strategy are more aligned than most teams assume. Strong Google rankings remain the primary driver of AI citation eligibility. Which means the model you use for content generation matters less than whether the output clears Google's quality signals. Claude Opus 4's tendency toward nuanced, experience-grounded writing is an advantage here, but only if you're also tracking where you actually appear across AI surfaces.
Tracking matters more than most teams realize. If you don't know which AI engines are citing you, which competitors are appearing in your target prompts, and what the citation gap looks like between your domain and the top-cited sources in your niche, model selection is guesswork. Platforms like Meev track brand mentions across ChatGPT, Claude, Gemini, Perplexity, Grok, Google AI Overviews, and DeepSeek with per-LLM drill-down, so you can see exactly where your content is landing and where the gaps are. That data should inform your model selection, not the other way around.
A practical scoring matrix for teams evaluating models:
1. Run 20 articles through your standard brief with each candidate model. 2. Score each output on: structured data completeness, factual claim verifiability, instruction adherence, and depth score (word count isn't depth. Assess whether the output makes a specific, arguable claim). 3. Calculate pass rate through your quality threshold. 4. Divide cost-per-article by pass rate to get effective cost-per-passing-article. 5. Pick the model with the lowest effective cost that meets your E-E-A-T requirements.
For agencies managing multiple domains, this calculation changes by client. A high-stakes B2B SaaS client needs a different model selection than a high-volume e-commerce client. Tools like Meev vs Profound and Meev vs Peec AI comparisons can help you understand what citation tracking and quality-gating look like across different platform architectures before you commit to a workflow.
One more thing worth saying plainly: the Position Digital AI SEO statistics for 2026 aggregate makes clear that citation patterns across AI platforms are shifting faster than any single model comparison can capture. The top 15 domains capture 68% of AI citation share across major LLMs, which means the citation pool is more concentrated than most teams assume. Model selection optimizes the quality of your content. Citation path strategy determines whether that content is even in the pool that gets cited. Both matter. Neither works without the other.
For teams serious about DeepSeek visibility or Grok citation tracking, the model you use to generate content is one variable. The citation outreach strategy, the publisher relationships, and the topical authority signals you're building are the other variables. Optimizing only the model is like tuning your car engine while ignoring the road.
Frequently Asked Questions
Is the LLM leaderboard 2026 useful for content marketing decisions at all?
Yes, but narrowly. The leaderboard is useful for filtering out models that are genuinely weak on instruction-following or factual grounding. It's not useful for predicting which model will produce the best auto-blog output or the most citation-eligible content. Treat it as a floor check, not a selection guide. Once you've eliminated the bottom quartile, run your own production tests on the specific tasks your workflow requires.
How does model choice affect Google AI Overviews optimization?
Indirectly. Google AI Overviews pulls heavily from pages that already rank in Google's top 10. The Seer study found 76% of cited pages rank in the top 10. So the model's impact on AI Overviews eligibility runs through Google ranking quality, not through any direct model-to-Overviews pipeline. Use the model that produces content most likely to rank. That means strong E-E-A-T signals, factual grounding, and depth over brevity.
Does using Claude vs. GPT-4o change which AI engines cite my content?
Not directly. The model you use to generate content doesn't determine which AI engine cites it. Citation eligibility is determined by your domain authority, your Google ranking position, your topical authority signals, and whether your content appears in the training or retrieval pools of each engine. What the model choice does affect is whether your output clears the quality signals that make citation eligibility possible in the first place.
What's the minimum quality gate setup for a small team running AI content?
At minimum: a factual claim verification step (human or automated), a structured data check (does the schema render correctly?), and a depth score threshold (is the article making a specific claim, or just summarizing what everyone already knows?). Meev's 16-dimension quality firewall automates this at scale, blocking articles below 70/100 before they reach your CMS. For small teams without that infrastructure, a manual checklist covering those three dimensions will catch the majority of quality failures before publish.
How often should I re-evaluate my model selection?
Every quarter, at minimum. The model landscape in 2026 is moving fast enough that a model that was the right cost-quality tradeoff in Q1 may have been superseded by Q3. More practically: re-evaluate whenever your quality pass rate drops more than 10 percentage points from your baseline, or whenever a new model release generates credible production benchmarks from teams running similar workflows to yours. Don't chase every release, but don't assume last quarter's answer is still right.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Track your brand across ChatGPT, Perplexity, Gemini, and 5 other AI surfaces — and find the citation gaps your competitors are filling.







