
By Judy Zhou, Head of Content Strategy
Key Takeaways
- A writer agent is an autonomous or semi-autonomous LLM system that plans, drafts, evaluates, and publishes content in a loop — not a prompt-response tool, but a workflow executor with access to external APIs and CMS integrations.
- 96% of AI Overview citations come from sources with strong E-E-A-T signals, according to Wellows' analysis of 2,400 citations — meaning writer agents without author entity profiles and fact-verification are producing content AI engines are structurally built to skip.
- LLM-powered research agents achieve only 39–77% factual accuracy despite maintaining link validity above 94%, per a 2025 arXiv study — making claim-level source verification a non-negotiable guardrail for any scaled content pipeline.
- The teams winning in AI search visibility aren't publishing the most — they're publishing consistently above the E-E-A-T quality threshold where AI citation behavior appears to flip from ignore to cite.
Marcus had been running his content agency for six years when a client forwarded him a Perplexity answer that cited three of his competitors back-to-back without a single mention of his brand. His team had published more content that quarter than either rival. He pulled up the articles, read them carefully, and couldn't spot the difference. What he didn't know. What nobody on his team had told him. Was that his competitors weren't just writing faster. They were using writer agents that structured, verified, and published in ways that answer engines were built to trust.
The term writer agent now carries two distinct meanings, and confusing them is costing content teams real visibility. A writer agent in the AI sense is an autonomous or semi-autonomous LLM-based system that plans, researches, drafts, revises, and publishes content with minimal human input. Not a prompt-response tool, but a workflow executor. The distinction matters because 96% of AI Overview citations come from sources with strong E-E-A-T signals, according to Wellows' analysis of 2,400 citations, and the content those sources publish is increasingly agent-generated. LLM-powered research agents achieve only 39. 77% factual accuracy despite maintaining link validity above 94%, per a 2025 arXiv study — which means the quality gate on any writer agent matters enormously.
Writer Agent: The Working Definition
A writer agent is not a chatbot you prompt and paste from. It is a system with a goal, a set of tools, and a loop it runs until the goal is met. The goal is typically a published article that meets a defined quality standard. The loop involves research, outlining, drafting, self-evaluation, revision, and CMS delivery. Often without a human touching the keyboard between start and finish.
The distinction from a "writing tool" is architectural. A tool like a basic AI text generator waits for input, produces output, and stops. An agent persists across steps. It can call a search API to verify a claim, check a keyword database to confirm search intent, evaluate its own draft against a rubric, flag a section as weak, regenerate it, and only then submit to publish. The agent has memory within a session, access to external tools, and a feedback mechanism. That loop is what separates it from autocomplete at scale.
There's also a semi-autonomous variant worth naming. Some writer agents run fully automated from topic discovery to publish. Others pause at defined checkpoints. Say, after the outline is generated or before final publish. To request human approval. Both qualify as writer agents. The defining characteristic is the workflow loop, not the level of human involvement.
For SEO and LLM optimization purposes, this distinction has real consequences. An agent that runs a quality evaluation step before publishing is structurally different from one that doesn't. The former can be tuned to produce content that passes E-E-A-T filters. The latter produces volume with no guarantee of signal quality.
How Writer Agents Differ From AI Writing Tools
The clearest way I can put it: a writing tool answers a question; a writer agent completes a job.
When you open a general-purpose AI writing assistant and type "write me a 1,500-word article about content marketing," you get output. The tool has no awareness of what you've already published, no access to your CMS, no ability to check whether the claims it's making are accurate, and no mechanism to evaluate whether the result is good enough to publish. You do all of that. The tool is a drafting accelerator.
A writer agent starts from a different premise entirely. It begins with a goal state. A published, quality-gated article on a specific topic. And works backward through the steps required to reach it. That typically involves: pulling keyword data to confirm search intent, checking existing content on the domain to avoid cannibalization, retrieving relevant knowledge base documents, generating an outline, drafting section by section, running a self-evaluation against quality criteria, revising flagged sections, generating metadata and schema markup, selecting internal links, and submitting to the CMS with scheduling instructions. Each of those steps involves tool calls. The agent isn't just writing; it's orchestrating.
The practical difference shows up in outputs. Writing tools produce drafts that require significant editorial work before they're publishable. Writer agents produce drafts that are closer to ready. Not because the LLM is smarter, but because the workflow catches more failure modes before the human sees the result. The agent can run a duplicate content check that the tool never thought to run. It can verify that a cited statistic links to a real source. It can flag that the draft scores below a readability threshold and regenerate the introduction. These aren't AI capabilities. They're workflow design.
One more difference that practitioners underestimate: tool-use. A writer agent can call external APIs mid-task. It can query Google Trends, pull from an RSS feed, hit a search index, or post directly to WordPress via REST API. A writing tool can't do any of that without a human copying and pasting between interfaces. That tool-use capability is what makes writer agents viable for scaled content pipelines rather than one-off drafting assistance.
Is your writer agent actually producing content that AI engines will cite — or just content that gets indexed and ignored?
Where Writer Agents Fit in a Content Stack
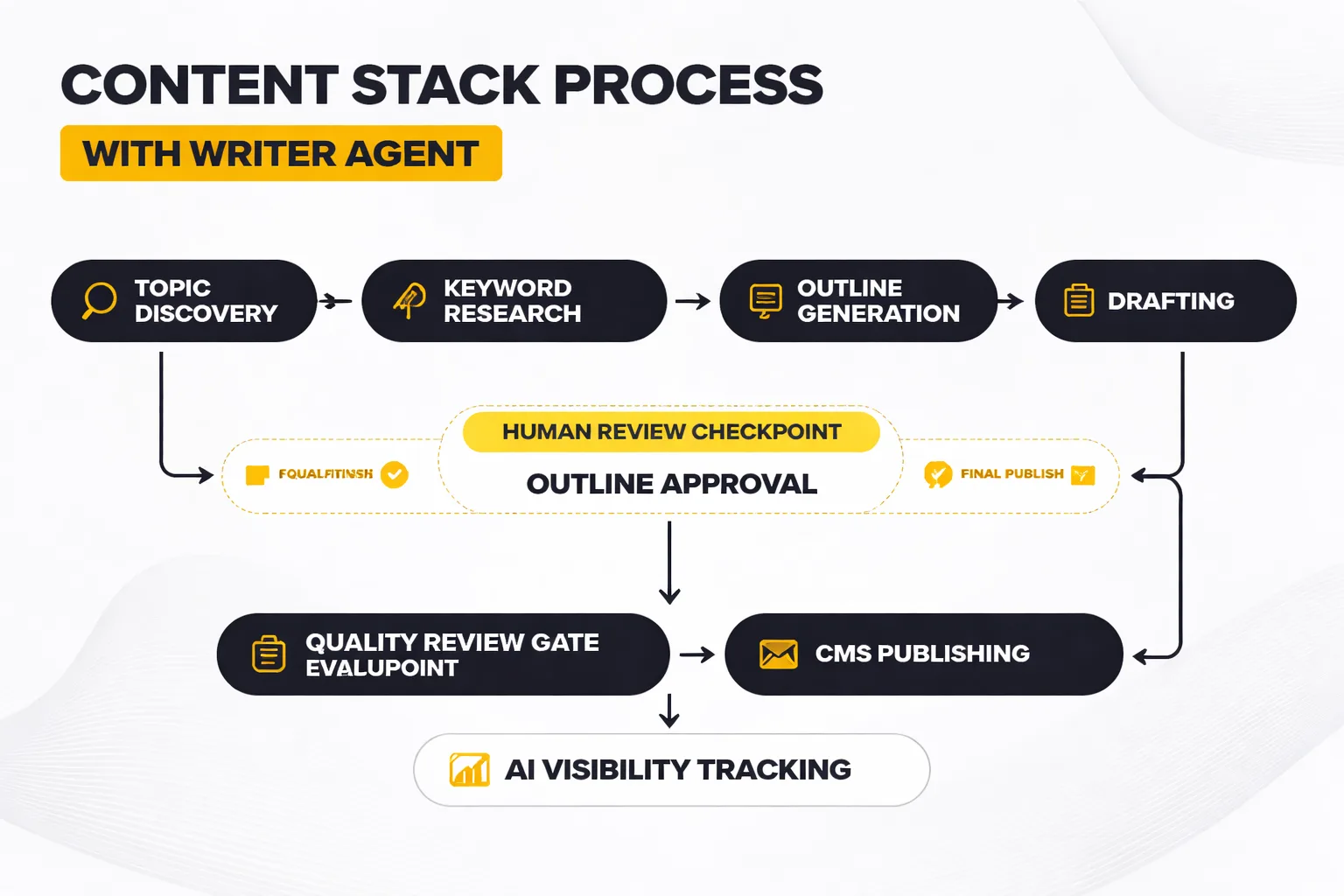
Writer agents slot into four distinct use cases, and they don't perform equally well across all four. Knowing which use case you're actually running determines whether an agent is the right tool.
Auto-blog engines are the most common deployment. The agent runs on a schedule. Daily, weekly, or triggered by trending topic signals. Discovers topics, drafts articles, and publishes them to the CMS automatically. The human sets the parameters once and reviews performance in aggregate rather than article by article. This works well for informational content at scale where the primary goal is topical coverage. It breaks down for content that requires genuine expertise, original reporting, or nuanced takes that can't be derived from existing sources.
Scaled content pipelines are similar but typically more structured. A content operations team defines templates, quality rubrics, and approval workflows. The agent fills the pipeline; humans review at defined gates. The efficiency gain is real: a team that previously produced 20 articles per month can produce 80-150 with the same headcount, provided the quality gate is tight enough to catch the drafts that shouldn't publish. The pattern I keep seeing is that teams underinvest in the quality gate and then wonder why their scaled content isn't performing.
AEO content factories are a newer use case that I find genuinely interesting. The goal isn't just to rank on Google. It's to get cited by AI search engines like Perplexity, ChatGPT, and Google AI Overviews. The agent is tuned to produce content with specific structural characteristics: definition-first openings, self-contained Q&A sections, named claims with attributed sources, and schema markup that signals factual reliability. Generative Engine Optimization (GEO) as a discipline is young enough that nobody has a definitive playbook, but writer agents are increasingly the execution layer for teams running these experiments at scale.
AI visibility campaigns use writer agents differently. Here, the agent's job isn't to produce the primary content. It's to produce supporting content that creates the citation context around a brand. Explainers, definitions, comparison pieces, and FAQ articles that establish vocabulary and framing. The theory is that if you control how a concept is named and defined across multiple pieces, AI engines are more likely to reproduce that framing when answering related queries. I've seen this work directionally, though I'd stop short of calling it proven.
What still needs human review across all four use cases: anything requiring original reporting, expert interviews, proprietary data, or genuine editorial judgment about what's worth saying. Writer agents are good at synthesizing existing knowledge. They are not good at generating new knowledge. That boundary matters.
The Risks: Quality, E-E-A-T, and Scaled Content Abuse

I'll be direct: writer agents are a quality risk if you deploy them without guardrails. The risks aren't hypothetical.
The E-E-A-T problem is structural. According to Wellows' analysis of 2,400 AI Overview citations, 96% come from sources with strong E-E-A-T signals. ZipTie.dev frames this as a binary gatekeeping filter: you're either in or you're out, and thin content generated without author entity signals, without demonstrated expertise, and without verifiable credentials is out. This is different from traditional SEO, where E-E-A-T was a quality nudge. In AI search, it appears to function as a threshold. A writer agent that publishes 150 articles per month without author profiles, without named experts, and without fact-verification is building a library that AI engines are structurally inclined to ignore. Moz's guidance on AI content and E-E-A-T makes the same point: integrating E-E-A-T principles into AI-driven content isn't optional if you want content that ranks in SERPs and resonates with real human interests.
The factual accuracy gap is the one that surprises people. The arXiv study on LLM deep research agents tested 14 LLMs and found factual accuracy ranging from 39% to 77% — despite those same agents maintaining link validity above 94% and relevance scores above 80%. That gap is the dangerous part. An agent can cite a real URL that doesn't actually support the claim it's making. The link looks valid. The relevance looks fine. The fact is wrong. Without a verification step that checks claim-to-source alignment (not just link existence), you're publishing errors at scale. The study also found that fewer than half of open-source models successfully generate cited reports in one-shot settings. Meaning the first draft often fails at citation integrity entirely.
The Google Helpful Content System risk is real and underappreciated. Google's scaled content abuse policies target content produced primarily for search engines rather than humans. And bulk-generated content is explicitly named. The signal isn't just volume; it's whether the content demonstrates genuine value that couldn't have been produced by a system with no real-world experience or expertise. Writer agents that produce generic, derivative articles at high frequency are exactly the profile that triggers these filters. Teams running auto-blog engines without a quality gate are taking a penalty risk that they often don't discover until a manual action or a traffic cliff.
The mention-citation gap deserves its own callout. In my work overseeing content strategy across multiple brands, I've watched teams celebrate AI mentions that turn out to be misattributions. The Tow Center's March 2025 study tested 1,600 queries and found citation failure rates above 60% across AI search engines. Getting mentioned by an AI engine and getting accurately cited are two different outcomes. Writer agents optimized purely for mention frequency. Without attention to how claims are framed and verified. Are building visibility on a foundation that misattributes as often as it attributes correctly.
What guardrails actually matter? Based on what I've seen work:
1. A multi-dimension quality score that blocks articles below a threshold from auto-publishing. Not a vibe check, a scored rubric. 2. Author entity profiles attached to every article, with real credentials that can be verified. 3. Claim-level source verification, not just link insertion. 4. Cannibalization detection before the draft is written, not after. 5. Human review at the outline stage for any topic requiring genuine expertise.
Platforms like Meev approach this with a 16-dimension Portfolio Quality Metric that scores every article across 11 quality signals and a 5-dimension Google Penalty Risk Matrix. Blocking articles below 70/100 from auto-publishing entirely. That's the kind of gate that separates a writer agent deployment from a content spam operation. For teams also tracking AI search visibility alongside their publishing pipeline, the feedback loop matters: you need to know whether the content you're publishing is actually getting cited, not just indexed.
The contrarian take I'll put on record: most teams deploying writer agents are solving the wrong problem. They're optimizing for output volume when the constraint is output quality. A writer agent that publishes 10 well-verified, E-E-A-T-strong articles per month will outperform one that publishes 150 thin articles in AI citation share. Not because AI engines reward restraint, but because the quality threshold for citation appears to be binary. Below it, volume doesn't help. Above it, volume compounds. The teams winning in AI search visibility right now aren't the ones publishing the most. They're the ones publishing consistently above the threshold.
FAQ

Is a writer agent the same as an AI agent?
Not exactly. An AI agent is the broader category: any LLM-based system that uses tools, maintains goals across multiple steps, and operates with some degree of autonomy. A writer agent is a specific type of AI agent whose domain is content creation. All writer agents are AI agents; not all AI agents are writer agents. The distinction matters when evaluating platforms. A general-purpose AI agent framework requires significant configuration to function as a writer agent, while purpose-built writer agents have content-specific tool integrations (CMS APIs, keyword databases, quality rubrics) built in from the start.
Can writer agents publish directly to WordPress or other CMSs?
Yes, and this is one of the capabilities that separates genuine writer agents from AI writing assistants. A writer agent with CMS integration can authenticate via API, create a draft, set metadata (title, slug, meta description, featured image), apply schema markup, schedule publication, and trigger indexing submissions. All without human intervention. WordPress REST API is the most common integration target, but Ghost, Shopify, Wix, and custom webhook endpoints are also supported by mature platforms. The practical caveat: CMS publishing capability without a quality gate is a liability, not a feature. The agent needs a mechanism to decide what gets published, not just the ability to publish.
How do you evaluate output quality from a writer agent?
The honest answer is that most teams don't evaluate it rigorously enough. A useful quality framework covers at minimum: factual accuracy (are claims sourced and do sources support the claims?), E-E-A-T signals (is there a named author with verifiable credentials?), originality (does the content add something not already present in top-ranking sources?), structural completeness (does it answer the query fully?), and Google Penalty Risk (does it exhibit patterns associated with scaled content abuse?). Scoring these manually for every article is impractical at scale, which is why quality-gated writer agent platforms that score automatically and block weak drafts before publish are worth the evaluation. For teams also monitoring Perplexity citation share and ChatGPT visibility, post-publish AI citation tracking closes the loop: if your content isn't getting cited despite publishing, the quality signal is telling you something the output score may have missed.
Do writer agents replace human writers?
For informational, research-synthesizing content at scale: they reduce the human workload substantially. For content requiring original reporting, expert interviews, proprietary data, or genuine editorial voice: no. The pattern I keep seeing is that the best-performing content operations use writer agents to handle the high-volume, lower-differentiation content tier. Definitions, comparisons, how-tos, FAQs. While human writers focus on the content that requires real-world experience to produce. That division of labor is more productive than either extreme: all-human (slow, expensive) or all-agent (fast, quality-inconsistent).
What's the difference between a writer agent and an auto-blogger?
An auto-blogger is typically a simpler system: it discovers topics, generates content, and publishes on a schedule, often with minimal quality evaluation. A writer agent is architecturally more sophisticated: it uses multiple tool calls, runs evaluation loops, can revise its own output, and typically has configurable quality gates. In practice, many products marketed as "auto-bloggers" are writer agents under the hood. And many products marketed as "writer agents" are glorified auto-bloggers without meaningful quality control. The test is simple: does the system have a mechanism to block its own output from publishing when that output is weak? If yes, it's operating as a writer agent. If it publishes everything it generates, it's an auto-blogger regardless of what the marketing says.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
See how Meev's quality-gated writer agent tracks AI citation share across ChatGPT, Perplexity, and Google AI Overviews — and blocks weak drafts before they reach your CMS.