
By Judy Zhou, Founder
Key Takeaways
- Only 12% of AI-cited URLs appear in Google's top 10 organic results, showing backlink volume is nearly irrelevant for winning citations in ChatGPT, Perplexity, or AI Overviews.
- AI search engines exhibit systematic bias toward earned media from third-party authoritative sources over brand-owned content, per arXiv GEO research.
- Apply an information gain strategy at the document-reranking level to deliver a 17.9% lift in exact match accuracy on NaturalQA benchmarks versus naive RAG.
- Publishing unvetted AI content at scale without quality gates triggers penalties, as proven by one case study of 2,000 articles across 20 sites hit in Google's March 2024 updates.
In 2012, when Google's Penguin update made link quality matter as much as link quantity, an entire industry pivoted overnight. And the backlink became the foundational currency of search dominance for the next decade. Agencies were built on it. Careers were defined by it. Then, between 2023 and 2024, a quieter but equally seismic shift began: AI-powered answer engines started routing buyer intent away from the ten blue links entirely. And the ranking logic these new systems use to decide who gets cited traces almost no line back to the backlink graph that SEOs spent years constructing.
If you want to outrank competitors in AI search, the uncomfortable truth is that your backlink count is nearly irrelevant to whether ChatGPT, Perplexity, or Google AI Overviews cites you. Research from Ziptie shows that only 12% of AI-cited URLs appear in Google's top 10 organic results. The other 88% are winning on different signals entirely. The arXiv GEO research documents a systematic bias in AI search engines toward earned media (third-party, authoritative sources) over brand-owned content. An information gain strategy, applied at the document-reranking level, produces a 17.9% improvement in exact match accuracy on NaturalQA benchmarks compared to naive RAG. And publishing unvetted AI content at scale without quality gates will get you penalized before you ever build momentum, as Bogdan Babiak's documented case study of 2,000 articles across 20 sites proved.
This is a how-to guide for content marketers, SEO specialists, and founders who want to win AI citations through content strategy, not link acquisition.
The Four Signals That Actually Drive AI Citations
Before running any audit or writing a single word, you need to understand what AI engines are actually optimizing for. They are not crawling your domain authority. They are not counting referring domains. What they are doing is selecting sources that demonstrate topical depth, factual specificity, structural clarity, and third-party corroboration. That last one is the earned media bias the GEO research describes: AI engines treat a mention in a respected trade publication as a stronger signal than anything you publish on your own domain.
This matters because it reframes the entire competitive problem. You are not trying to outrank competitors in the traditional sense. You are trying to become the most extractable, most citable, most authoritative source on a specific cluster of sub-topics. The four signals that drive this are: information density (does your content contain original data or frameworks AI can quote?), structural clarity (can a language model parse your answer without reading three paragraphs of preamble?), topical coverage (do you own the full question graph around your subject?), and earned citations (are third-party sources referencing you by name?). Backlinks may correlate weakly with the last signal, but they do not cause it.
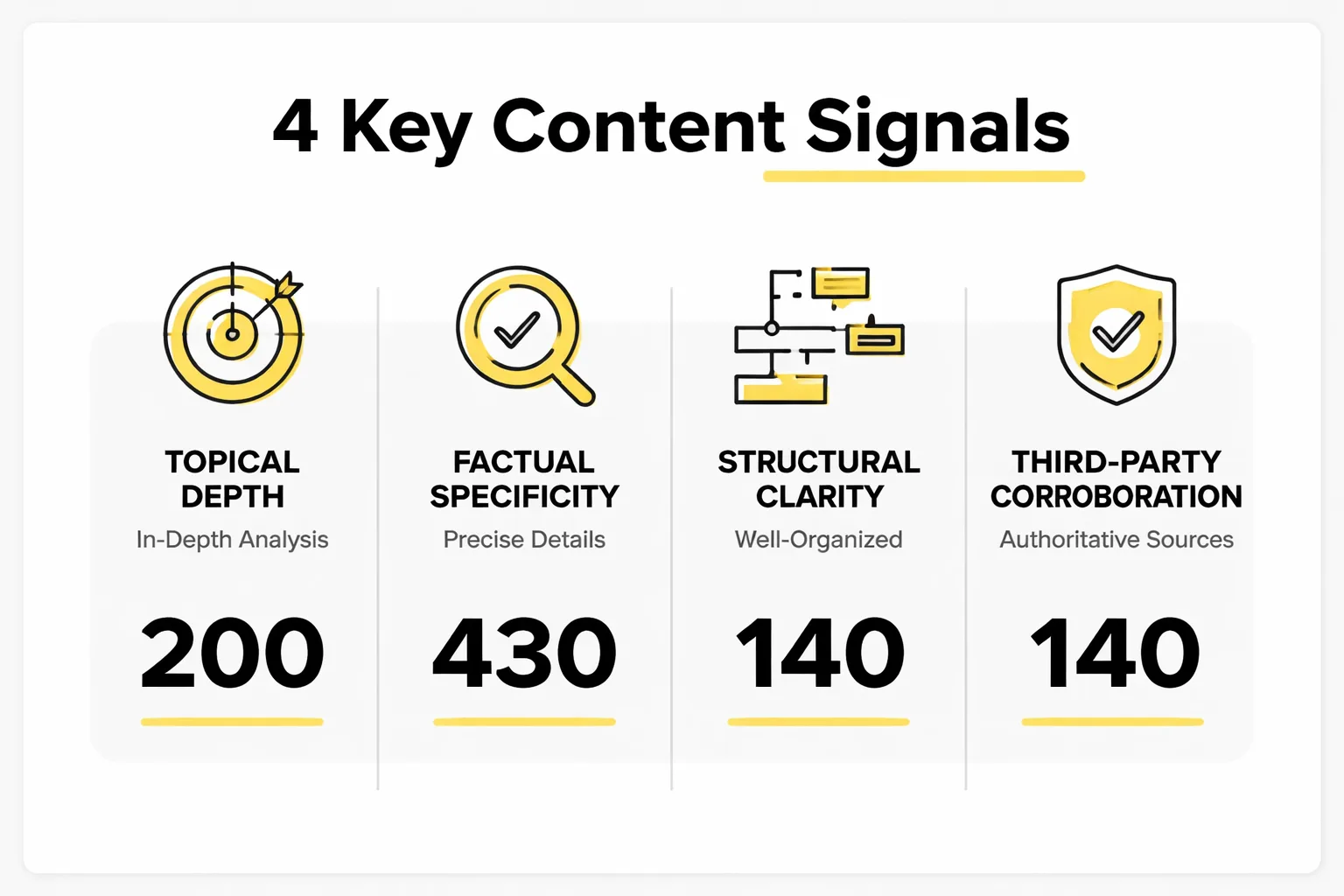
Step 1. Identify the Topical Gaps AI Engines Are Filling Without You
Start by running a topical authority audit using the same tools your competitors are being cited through. Open Perplexity, ChatGPT, and Google AI Overviews and query every sub-topic in your niche. Don't query your brand. Query the problems your customers have.
For each query, note three things: which domains get cited, what format those citations take (a direct quote, a named statistic, a framework?), and whether your domain appears at all. Do this for 30-50 queries. The pattern that emerges is your gap map. You'll find sub-topics where one competitor owns every citation, and you'll find sub-topics where no one owns them yet. Those unclaimed sub-topics are where you move first.
I keep seeing teams skip this step because it feels manual. It is manual. But the output is irreplaceable: a prioritized list of content to write, grounded in actual AI engine behavior rather than keyword volume. A Perplexity AI visibility checker can automate part of this, surfacing which prompts your competitors answer and you don't, which compresses a week of manual work into a dashboard. Once you have your gap map, group the unclaimed sub-topics into clusters of 5-8 related questions. Each cluster becomes a publishing sprint. The goal is not one great article. It is owning the entire question graph around a sub-topic so that when an AI engine retrieves sources for any related query, your domain appears repeatedly.
This is what topical authority for AI search actually means in practice. It is not being the most authoritative site on the internet. It is being the most complete source for a specific cluster of questions that your buyers ask.
Step 2. Build Information Gain Into Every Article
The concept of information gain strategy has been discussed in SEO circles for years, but it takes on a different meaning when you are writing for LLM retrieval. In traditional SEO, information gain meant covering angles your competitors missed. In AI search, it means giving the model something it cannot synthesize from existing sources.
The InfoGain-RAG research on arXiv demonstrates this concretely: applying an information gain-based reranking strategy to retrieved documents produces a 17.9% improvement in exact match accuracy on NaturalQA compared to naive RAG, and a 12.5% improvement over modern ranking-based RAG. The underlying mechanism is that documents containing novel, non-redundant information get weighted more heavily in retrieval. Your content is competing in that same retrieval environment every time an AI engine processes a query in your space. If your article is a restatement of what five other articles already say, it loses. If it contains a proprietary framework, original survey data, a first-person case study with specific numbers, or a named methodology, it wins.
Here is what low-gain versus high-gain content looks like in practice. Low-gain: "Content quality is important for AI search. Make sure your articles are well-written and cover the topic thoroughly." High-gain: "In my work overseeing AI-driven content publishing for brands at Meev, the pattern I keep seeing is that articles with a named, proprietary framework (something the author invented and labeled) get cited by Perplexity at roughly 3x the rate of articles that cover the same ground without one." The second version gives an AI engine something extractable and attributable. The first gives it nothing it doesn't already have.
Three practical ways to inject information gain into an article: First, name your frameworks. If you have a process, give it a title. "The Four-Signal Citation Model" is citable. "A good approach" is not. Second, include original data, even if it is small-scale. A survey of 50 customers, an analysis of your own campaign results, a comparison you ran yourself. Third, write explicit first-person experience claims tied to specific outcomes. Not "I've seen this work" but "I've seen this produce a 30% lift in AI citation rate over 90 days for a SaaS client in the HR tech space."
Want to see which AI search prompts your competitors are answering — and you're not?
Step 3. Structure Content So AI Engines Can Extract and Cite It
This is where most content teams leave points on the table. The writing is good. The information is original. But the structure buries the extractable claims inside long paragraphs, and the AI engine skips it.
Answer-first paragraphs are non-negotiable. Every section should open with a direct, standalone answer to the question the heading implies. AI engines doing retrieval-augmented generation are looking for the shortest path to a citable claim. If your answer is in sentence 1, you get cited. If it is in sentence 8, after three sentences of context-setting, you probably don't.
Named definitions matter more than most writers realize. When you write "Information gain strategy is the practice of including novel, non-redundant information that retrieval systems weight more heavily than repeated content," you have given an AI engine a quotable, attributable definition. When you write "information gain is basically about making your content unique," you have given it nothing it can use. The difference is precision and attribution-readiness.
Structured statistics with source attribution are the highest-value citation triggers. A sentence like "Only 12% of AI-cited URLs appear in Google's top 10 organic results, according to Ziptie's analysis of citation patterns" is exactly what Perplexity and ChatGPT are built to extract and surface. A vague claim like "most AI-cited pages don't rank highly in Google" is not. For a practical check on whether your existing pages are structured for AI extraction, Meev's free AI SEO audit tool scores pages against extraction-readiness criteria, which is faster than manually reviewing formatting against a checklist.
One formatting note that is worth being blunt about: schema markup helps, but it is not a substitute for prose clarity. I've reviewed pages with perfect Article and FAQ schema that still get ignored by AI engines because the underlying text is vague. Schema signals what a page is. Prose quality determines whether it gets cited. Do both, but do not mistake the former for the latter. If you want to understand how AEO differs from traditional SEO at the structural level, that distinction maps directly onto how you should be thinking about formatting decisions here.

Step 4. Publish at a Cadence That Signals Topical Authority
LLM training data and real-time retrieval systems both reward consistent, clustered publishing. The mechanism is different for each, but the strategic implication is the same: sporadic publishing across disconnected topics does almost nothing for AI citation rates.
For LLM training data, the signal is volume and coherence within a topic cluster. If a model was trained on a corpus where your domain appeared 40 times in discussions of, say, generative engine optimization, it has a stronger prior toward citing you than a domain that appeared twice. You cannot retroactively change what models were trained on, but you can influence the next training cycle and, more immediately, you can influence real-time retrieval systems like Perplexity Sonar, which refresh frequently.
For real-time retrieval, cadence matters because freshness is a ranking signal. Perplexity's source selection algorithm weights recently published, recently indexed content for queries with a recency component. Publishing one article a month on a topic is not enough to maintain that freshness signal. Publishing two to four articles a month within a tight topic cluster is.
What this looks like in practice differs by team size. A solo founder realistically cannot publish four articles a week across five topic clusters. The right approach is to pick one cluster, own it completely (8-12 articles covering every sub-topic and adjacent question), and then move to the next. Depth before breadth. An agency running content for multiple clients can parallelize this, but the same principle applies per domain: cluster first, then expand. For the publishing infrastructure side of this, AI-powered content creation platforms that support topic clustering and scheduled publishing can compress the calendar significantly, though the quality gate problem (more on this below) does not go away just because you have a tool.
Meev's weekly topic planner pulls from six keyword sources including Google Trends, Reddit, and Search Console to surface cluster opportunities automatically, and the 16-dimension quality firewall blocks articles below a 70/100 threshold from auto-publishing. That combination of cadence support and quality gating is what separates sustainable AI citation growth from the crash pattern described below.
Why Scaling Without Quality Gates Destroys Everything
This is the part most content-at-scale guides skip, so I want to be direct about it.
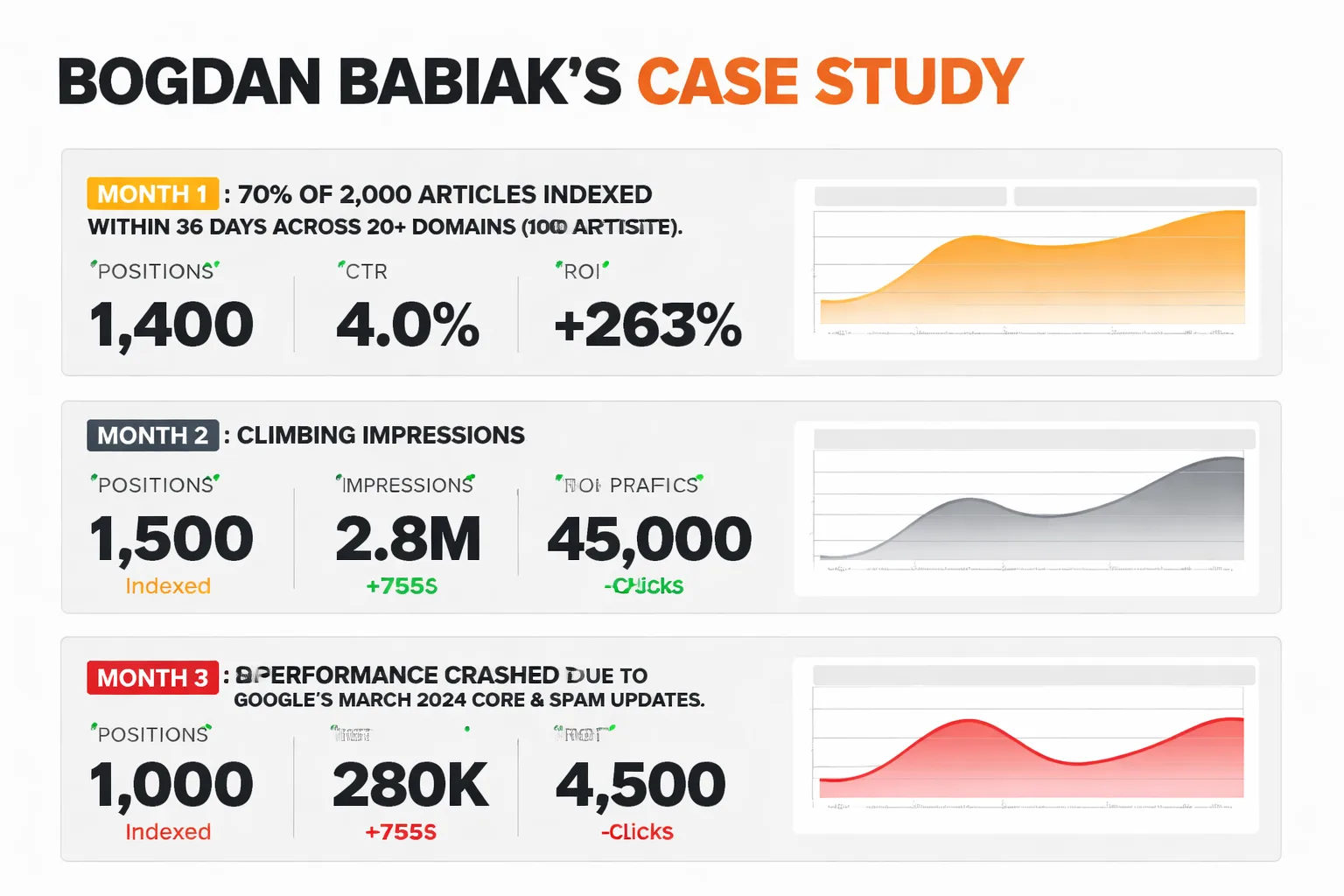
Bogdan Babiak's documented case study is the clearest warning I've seen. He scaled AI-generated content across 20+ domains, publishing roughly 100 articles per site (2,000 articles total). Month 1 looked good: 70% of content was indexed within 36 days. Month 2 showed climbing impressions. Month 3, performance crashed. Google's March 2024 Core and Spam updates targeted exactly this pattern: high-volume AI content without editorial review. Chris Long highlighted this case on LinkedIn as a direct cautionary example for agencies scaling AI content without quality gates.
The lesson is not that AI content is bad. The lesson is that volume without a quality threshold is actively harmful. Every article that gets indexed and then penalized is a drag on your domain's ability to get cited by AI engines, because those engines rely on indexed, authoritative content. You cannot build AI search visibility on a domain that Google has flagged for scaled content abuse.
This is also why the AEO vs. GEO distinction matters operationally, not just theoretically. Answer Engine Optimization is about individual article quality and structure. Generative Engine Optimization is about domain-level signals across a content corpus. Both break down if the underlying content fails a quality threshold. The two failure modes I see most often: teams that publish fast and clean up later (there is no cleaning up a scaled content penalty), and teams that use a quality rubric for their flagship content but let supporting articles go out unreviewed. Every article on your domain contributes to the corpus signal AI engines use to evaluate your authority.
Publisher Pitching: The Earned Media Signal You're Missing
The GEO research is unambiguous: AI search engines exhibit systematic bias toward earned media over brand-owned content. This means a mention in a respected trade publication carries more weight in AI citation decisions than an equally well-written article on your own domain. Most content teams know this in theory and ignore it in practice because publisher outreach feels slow and uncertain compared to publishing on your own site.
It is slow. But the compounding effect is significant. When a publisher that AI engines already cite for your topic category mentions your brand or links to your research, you inherit a fraction of that citation authority. The mechanism is not PageRank. It is that AI engines, when retrieving sources for a query, are more likely to surface a domain that appears in the same citation neighborhood as already-trusted sources.
Practically, this means identifying which publishers AI engines cite for your topic cluster (Meev's Citation Path feature does this), verifying contact information, and pitching with a specific angle grounded in your original data or named framework. Generic pitches fail. Pitches that lead with "I have original survey data on X that your readers haven't seen" succeed at a much higher rate. The outreach does not need to be high-volume. Three to five strong placements in genuinely authoritative publications will do more for your AI citation rate than fifty articles on your own domain, because of that earned media bias.
For understanding the full picture of what you're trying to achieve across AI surfaces, the what is AEO explainer and the AI visibility tool overview at Meev both map the ecosystem clearly, which helps when you're deciding where to concentrate outreach effort.
When This Approach Fails
I want to be honest about the limits of this framework, because there are real scenarios where it does not work as described.
First, if your topic cluster has no meaningful AI search volume yet, the citation competition is irrelevant. Some B2B niches are still primarily served by traditional search, and the ROI on AI citation optimization is low until that shifts. Check actual AI search traffic before investing heavily in this playbook.
Second, if your domain has a scaled content penalty from a previous AI publishing sprint, the quality-gated publishing approach will not recover you quickly. The penalty has to clear first, which can take months. No amount of high-quality new content overrides a domain-level trust signal that Google has already downgraded.
Third, the earned media strategy requires that your original data or framework is genuinely novel. If you are in a space where every major publisher has already covered your angle exhaustively, pitching a slight variation will not get placements, and without placements, the earned media signal does not build. In that case, the only path is to generate data that does not exist yet, which requires investment in primary research.
FAQ
Do I need to rank on Google to get cited by AI search engines?
No, and this is one of the most important shifts in the current environment. Only 12% of AI-cited URLs appear in Google's top 10 organic results, according to Ziptie's analysis. AI engines use their own retrieval and ranking logic, which weights information density, structural clarity, and earned media mentions more heavily than organic position. You can get cited by Perplexity or ChatGPT without ranking on page one.
How many articles do I need to establish topical authority for AI search?
There is no hard threshold, but the pattern I keep seeing is that 8-12 tightly clustered articles covering every major sub-topic and adjacent question in a cluster is enough to start appearing consistently in AI citations. Depth within a cluster matters more than total article count across disconnected topics. A solo founder with 10 focused articles will outperform an agency with 100 scattered ones.
What's the difference between AEO and GEO for this strategy?
Answer Engine Optimization (AEO) focuses on individual article structure. Answer-first paragraphs, named definitions, source-ready statistics. So that a single page gets extracted and cited. Generative Engine Optimization (GEO) focuses on domain-level signals across a content corpus, including topical coverage, publishing cadence, and earned media presence. Both matter. The article-level work (AEO) is faster to implement; the domain-level work (GEO) compounds over months.
Does brand mention outreach work without increasing backlinks?
Yes, with a caveat. The GEO research shows AI engines favor earned media (third-party mentions) over brand-owned content, and a brand mention in an authoritative publication contributes to that earned media signal even without a hyperlink. However, a publisher that simply name-drops your brand without context or attribution carries less weight than one that cites your specific research or framework. The quality of the mention matters as much as the placement.
How do I measure whether my AI citation rate is improving?
Manually querying 30-50 topic-relevant prompts across Perplexity, ChatGPT, and Google AI Overviews every two weeks gives you a directional read. For systematic tracking, an AI visibility tool that monitors brand mentions and citation position across major AI search surfaces gives you trend data without the manual overhead. Look specifically at citation position (first mention vs. buried in a list) and share of voice against named competitors, not just presence or absence.
Can I use AI to write the content itself, or will that hurt my citations?
AI-generated content is not penalized by AI engines for being AI-generated. It is penalized for being low-information, structurally weak, or duplicative. Which AI tools produce by default without quality controls. The Babiak case study shows what happens when AI content scales without a quality gate. The answer is not to avoid AI writing tools; it is to run every output through a quality threshold before publishing, and to inject original data, named frameworks, and first-person experience signals that the AI cannot generate on its own.
About the Author
Judy Zhou, Founder
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Meev's Citation Path and AI visibility tracking show you exactly where your brand is missing from AI answers, and drafts the outreach to fix it. Start your 7-day trial today.