
By Judy Zhou, Head of Content Strategy
Key Takeaways
- AI-referred sessions jumped 527% year-over-year in the first five months of 2025, making AI visibility the central competitive variable for agencies and solo founders in 2026.
- Structured, authority-signaled content boosts AI visibility by up to 40%, per the original GEO research on arXiv.
- Factual accuracy in LLM citations ranges from only 39% to 77% across 14 models tested, so source quality now determines whether answer engines cite your content.
- Use Claude Fable 5's longer context windows and multi-step reasoning to generate structurally coherent long-form output with fewer hallucinations than prior Claude versions.
What would it mean for your agency. Or your solo operation. If the next AI Overview, Perplexity answer, or ChatGPT citation pointed directly to your content instead of your competitor's? In 2026, that question is no longer hypothetical; it's the central competitive variable in content marketing. Claude Fable 5 content creation 2026 has emerged as the capability most aligned with how answer engines actually select, score, and surface sources. Whether you're managing a multi-CMS publishing workflow for enterprise clients or building topical authority as a one-person brand, understanding this model could redefine your visibility ceiling.
Claude Fable 5 is Anthropic's mid-tier 2026 model, positioned between the lightweight Haiku and the research-grade Mythos 5. It runs longer context windows than its predecessors, produces structurally coherent long-form output, and handles multi-step reasoning with noticeably fewer hallucinations than earlier Claude versions. AI-referred sessions jumped 527% year-over-year in the first five months of 2025, and that trajectory has only steepened into 2026. The original GEO research from arXiv found that structured, authority-signaled content can boost AI visibility by up to 40%. A PwC-adjacent study on LLM citation accuracy found that across 14 models tested, factual accuracy in citations ranged from only 39% to 77%, meaning the quality of your source material matters enormously. These four data points together explain why the model you use to generate content, and the quality controls you put around it, are no longer secondary decisions.

Fable 5 vs. Mythos 5: The Distinction That Actually Matters
A lot of practitioners conflate these two model tiers, and it costs them. Mythos 5 is Anthropic's flagship research and reasoning model in 2026. It handles deep autonomous knowledge work, extended multi-document synthesis, and the kind of chain-of-thought tasks that require genuine logical scaffolding. Fable 5 sits below it in compute cost and latency, but it's the model that most content teams will actually run at scale.
Here's the practical difference: Mythos 5 is what you'd use to analyze a 200-page technical white paper and extract a structured argument. Fable 5 is what you'd use to produce 80 publishable articles a month without the per-call cost making your unit economics collapse. For Claude Fable 5 content creation 2026, the relevant capabilities are its improved instruction-following (it sticks to style guides and structural templates far better than Claude 3 did), its reduced tendency to fabricate citations, and its ability to maintain consistent brand voice across long documents without drifting.
The fabrication point is worth pausing on. The arXiv study on LLM citation accuracy found that fewer than half of open-source models could successfully generate cited reports in a single-shot setting. Fable 5 is a closed model with stronger RLHF tuning around factual grounding, which means when you pair it with a verified knowledge base, the output is meaningfully more trustworthy than what most open-source pipelines produce. That's not a marketing claim. It's a structural property of how the model was trained.
Why AI Content at Scale Keeps Failing by Month Three
I want to be direct about something the AI content marketing 2026 conversation keeps glossing over: scaling content without a quality gate is a documented failure pattern, not a theoretical risk.
Chris Long surfaced a study by Bogdan Babiak that tested AI content scaling across 20+ sites, 100 articles per site, 2,000 articles total. Month one looked promising: 70% of content was indexed within 36 days. By month three, performance had collapsed. Google's quality assessment mechanisms, likely a combination of Helpful Content System signals and scaled content abuse detection, caught up with the bulk. The initial crawl phase indexed everything. The quality evaluation phase penalized most of it.
This is the exact failure mode that a quality firewall exists to prevent. At Meev, the 16-dimension Portfolio Quality Metric blocks articles from auto-publishing if they score below 70 out of 100. The 16 dimensions cover 11 article-quality signals (things like information gain, factual density, structural coherence) plus a 5-dimension Google Penalty Risk Matrix that flags scaled content abuse patterns before they reach your CMS. No other auto-blog platform I'm aware of has an equivalent gate. Most of them ship whatever the model produces and let you discover the problem in Search Console three months later.
The analogy I use with clients: running AI content without a quality gate is like running a restaurant where every dish that comes out of the kitchen goes directly to the customer without anyone tasting it first. You'll serve a lot of meals fast. Some of them will make people sick.
Want to see which AI engines are citing your competitors instead of you right now?
How Does Claude Fable 5 Handle E-E-A-T Signals?
E-E-A-T for AI search is a different problem than E-E-A-T for traditional Google ranking, and most practitioners are treating them as identical. They're not.
For Google's Helpful Content System, E-E-A-T signals are inferred from authorship markup, topical depth, outbound citation quality, and the demonstrated expertise embedded in the prose itself. Fable 5 can contribute to all four of these when it's properly scaffolded. Author entity profiles with structured schema markup, outbound citations to high-authority sources, and knowledge base retrieval that grounds claims in verified data all push E-E-A-T scores upward. The model doesn't create expertise. It amplifies the expertise you've already documented.
For LLM citation selection, the mechanism is different. AI engines like Perplexity and ChatGPT aren't reading your schema markup. They're pattern-matching against the semantic neighborhood of your content: what sources you cite, what entities you mention, how your claims align with what the model already knows to be true. The SparkToro research on AI brand recommendations found that AI models are highly inconsistent in brand recommendations, with factual accuracy ranging from 39% to 77% across 14 LLMs tested. That inconsistency is partly a function of source quality in the training data. If your content is consistently cited by authoritative publishers, the model's internal representation of your brand improves over time.
Fable 5 helps here because it produces content with the structural properties that AI engines extract from: clear claim-evidence pairs, named sources with inline attribution, and self-contained sections that answer discrete questions. Those aren't stylistic choices. They're the architectural features that make content extractable.
Does Generative Engine Optimization 2026 Require a Separate Workflow?
Short answer: yes, and pretending otherwise is the mistake I made in late 2025.
I tried running a unified brief, one content format optimized for both Google organic and AI citation pickup, across a cluster of informational pages. The AI visibility improved. The Google organic performance softened. That tradeoff is real, and it's not resolved yet. The tactics that get content cited in Perplexity and ChatGPT, conversational framing, tight citation blocks, punchy opinionated claims, pull against what Google's Helpful Content System rewards, which is demonstrated depth and topical authority built over time.
Generative Engine Optimization 2026 as a discipline is still forming. The original arXiv GEO paper established the foundational framework: add statistics, cite authoritative sources, use clear quotable sentences, and structure content so that generative engines can extract discrete answers. That framework holds. What it doesn't tell you is how to do all of that without softening the depth signals Google looks for. My current approach is to treat GEO and traditional SEO as separate workstreams with separate briefs, not a single unified strategy. That's slower. It's also honest.
For agencies managing multiple client domains, this means your content calendar needs two tracks. One track optimizes for topical authority and depth, long-form pieces that build semantic coverage of a subject. The other track produces citation-optimized content: structured, claim-dense, with named sources and self-contained answer blocks. Meev's archetype-aware writing system handles this distinction at the generation layer, with Explainer and How-To archetypes carrying different retrieval weights and structural templates than Listicle or Problem-Solver archetypes. The ai model comparison question for your stack isn't just which model is smartest. It's which platform enforces the right structure for the right content type.
Building an AI Citation Outreach Strategy Around Fable 5
Here's the contrarian take most content teams need to hear: the content you publish is only half the citation equation. The other half is whether authoritative publishers are citing you, and that requires active outreach, not passive publishing.
Somewhere between 80% and 90% of LLM responses draw from organically earned placements, not manufactured co-citation campaigns. I've watched teams run high-volume mention campaigns that generated impressive vanity metrics and zero compounding effect on AI visibility. The failure mode is consistent: mentions that land in thin content, where there's no surrounding semantic signal to reinforce your authority, don't move the needle in LLM training data. Editorially earned mentions, where a journalist or editor chose to include you because you were genuinely the right reference, behave differently.
The practical workflow I've landed on has three steps. First, identify which publishers AI engines actually cite for your topics. This is the Citation Path function in Meev: it surfaces the domains that Perplexity, ChatGPT, and Google AI Overviews pull from when answering questions in your niche. Second, find verified contact information for those publishers. Third, draft pitches that are grounded in your knowledge base and specific to the publisher's editorial angle, not generic "we'd love to contribute" emails. The Grok visibility tracking and DeepSeek visibility tracking dashboards in Meev show you which surfaces are already citing you and which have citation gaps, so you can prioritize outreach by actual opportunity rather than guessing.
For solo founders, this workflow is more achievable than it sounds. You don't need 150 articles a month. You need 10 articles that are genuinely citation-worthy, plus 5 targeted outreach campaigns to publishers who already cover your topic. That's a manageable sprint.
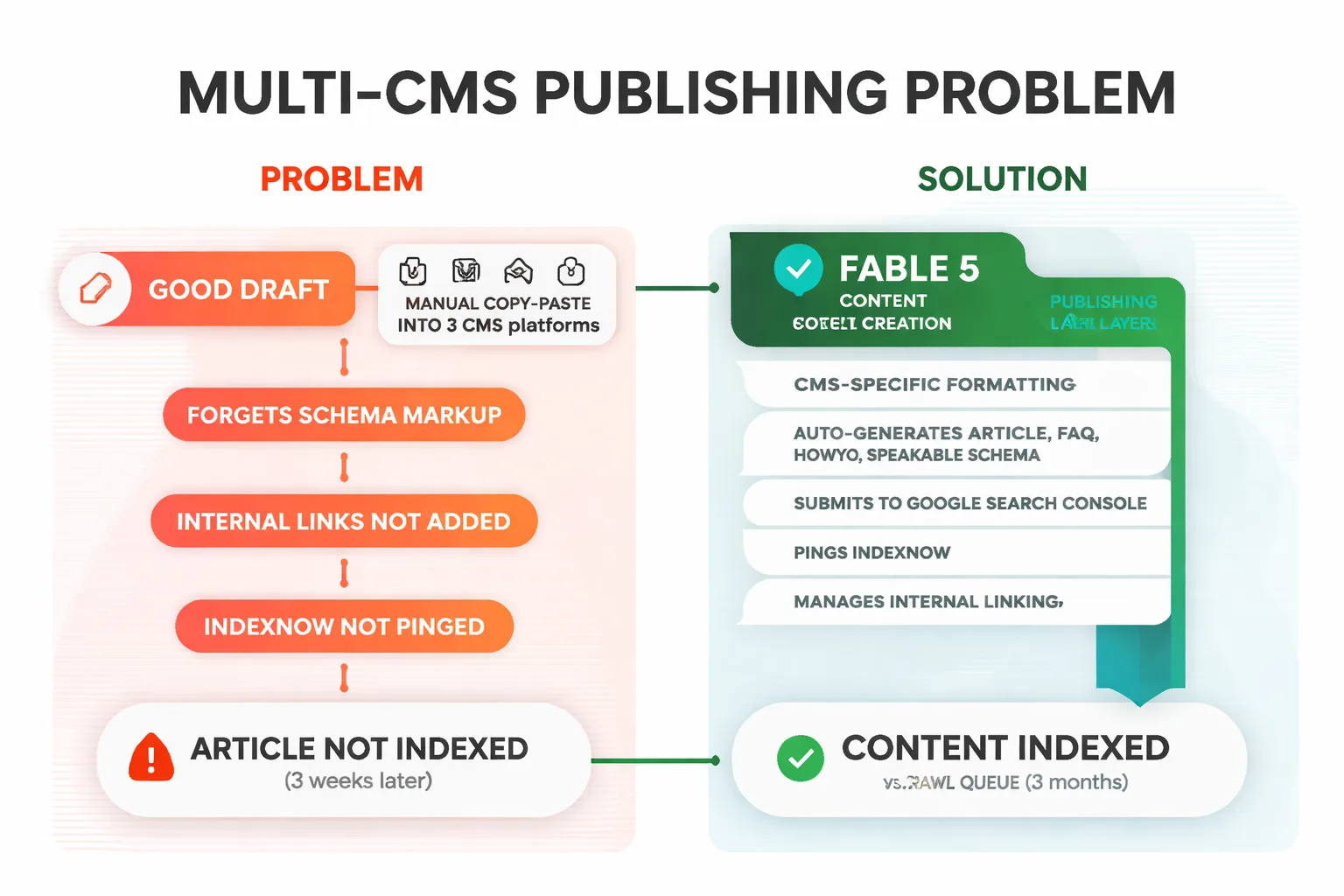
The Multi-CMS Publishing Problem Nobody Talks About
Agencies running content for multiple clients across WordPress, Ghost, Shopify, and custom CMS environments know this pain: the publishing workflow is where quality dies. You've got a good draft. Then it goes through a manual copy-paste into three different CMS platforms, someone forgets the schema markup, the internal links don't get added, and IndexNow never gets pinged. Three weeks later you're wondering why the article isn't indexed.
Claude Fable 5 content creation 2026 solves the generation problem. It doesn't solve the distribution problem. That requires a publishing layer that handles CMS-specific formatting, auto-generates Article, FAQ, HowTo, and Speakable schema markup, submits to Google Search Console and pings IndexNow on every publish, and manages internal linking with archetype-aware anchor placement. These aren't nice-to-have features. They're the difference between content that gets indexed in 36 days and content that sits in a crawl queue for three months.
For agencies comparing platforms, the Meev vs. Jasper AI comparison and the Meev vs. Copy.ai comparison are worth reviewing if you're evaluating whether a generation-only tool covers your actual workflow needs. Generation-only tools hand you a draft. A closed-loop platform handles the draft, the quality gate, the CMS publish, the schema injection, the indexing submission, and the AI visibility tracking in one system.
When Should You Prioritize AI Visibility Over Organic SEO?
This is the question I get most often from agency clients, and the honest answer is: it depends on where your funnel actually converts.
I ran a content audit last quarter where we identified pages getting Perplexity and ChatGPT referrals and assumed they were compensating for Google traffic drops. They weren't, net. The AI citations were hitting informational pages that never converted. The bottom-of-funnel content that drove pipeline was getting no LLM pickup at all. That's a survivorship bias problem baked into almost every GEO success story: the practitioners reporting wins are measuring traffic, not pipeline.
The Elon University survey found that more than 52% of U.S. adults now use LLMs like ChatGPT, Claude, and Gemini regularly. That's a real audience. But it's an audience at the top of the funnel, asking exploratory questions. If your business converts on informational intent, AI visibility is your primary channel. If your business converts on transactional or comparison intent, traditional SEO and paid search still dominate, and AI visibility is a brand awareness play, not a pipeline driver.
For solo founders especially, I'd recommend tracking AI search visibility across surfaces before making major workflow changes. Know which surfaces are already citing you, which prompts trigger your competitors instead of you, and what the citation gap actually looks like before you reorganize your content strategy around closing it. The Meev vs. Peec AI comparison covers how different platforms approach this tracking problem if you're evaluating your options.
FAQ
What makes Claude Fable 5 different from other AI models for content creation?
Fable 5 sits between Anthropic's lightweight Haiku and the research-grade Mythos 5 in the 2026 model lineup. Its key advantages for content teams are stronger instruction-following (it adheres to style guides and structural templates more consistently), reduced hallucination rates when paired with a verified knowledge base, and lower per-call cost than Mythos 5. For teams running 80+ articles per month, those properties matter more than raw reasoning capability.
How do I avoid Google's scaled content abuse penalties when using AI at scale?
The Bogdan Babiak study cited by Chris Long on LinkedIn tested 2,000 AI-generated articles across 20+ sites and found that 70% indexed within 36 days, but performance collapsed by month three. The pattern is consistent: bulk AI content passes the initial crawl phase and fails the quality evaluation phase. The mitigation is a quality gate that scores articles on information gain, factual density, structural coherence, and penalty risk signals before they reach your CMS. Articles below a defined threshold get blocked, not published.
Is Generative Engine Optimization 2026 compatible with traditional SEO?
Not always, and treating them as identical is a mistake. GEO-optimized content uses conversational framing, tight citation blocks, and punchy claim-evidence pairs. Traditional SEO rewards demonstrated depth and topical authority built over time. These formats pull in different directions. The practical solution is separate content tracks with separate briefs, not a single unified approach that tries to satisfy both surfaces simultaneously.
How does AI citation outreach actually work for a solo founder?
Start by identifying which publishers AI engines cite for your specific topics. Then find verified contacts at those publishers and draft pitches grounded in your existing content and expertise. The pitch brief should focus on earning placement in substantive editorial coverage, not generic backlink requests. Even 5-10 well-placed citations in authoritative publications can meaningfully shift how LLMs represent your brand over time, because the semantic neighborhood around those mentions reinforces your authority signals.
What should I track to measure AI search visibility?
At minimum: which AI surfaces mention your brand, where in each answer your brand appears (first mention, in a list, last), which competitor domains are being cited instead of you for your target prompts, and whether your citation share is trending up or down week over week. Tracking mention count without position context misses the signal. An AI answer that mentions you last, after three competitors, is very different from one where you're the primary cited source.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Track your brand's citation gaps across every major AI search surface and start closing them with Meev's Citation Path workflow.





