
By Judy Zhou, Founder
Key Takeaways
- Auto-blog engine workflows that skip quality gates produce content at the blog-tier citation level — the lowest rung in the LLM citation hierarchy identified across 6.8 million AI citations tracked by Jason Dowdell.
- A quality gate scoring below 70/100 should block articles from auto-publishing; Meev's 16-dimension firewall is the only auto-blog tool with a hard blocking mechanism rather than a soft warning.
- AI visibility monitoring must be wired into the publishing pipeline itself — not checked manually — so every article enters a citation-tracking queue the moment it goes live across ChatGPT, Perplexity, Gemini, and other major AI search surfaces.
- The mention-citation gap (brand mentioned on the web but not cited in AI answers) is the metric most automated blogging setups aren't measuring, and closing it requires per-surface tracking, not aggregate visibility scores.
Marcus had been running his agency's content operation for three years when a client called to say a competitor's brand was showing up in ChatGPT answers for every product category they cared about. And Marcus's client wasn't mentioned once. He pulled up their publishing dashboard: 200 articles live, consistent cadence, solid on-page optimization. Everything looked right. But there was no layer in their workflow watching for AI citations, no alert for mention-citation gaps, and no mechanism to route high-performing content back into the pipeline. The auto-blog engine was running. It just wasn't watching.
Auto-blog engine workflows have evolved past the "publish fast, fix later" era. The teams winning AI search visibility in 2026 are the ones who've wired quality gates and LLM citation tracking directly into their publishing pipelines. Not bolted on as afterthoughts. According to a LinkedIn analysis by Nick Bennett at Reachdesk, content optimized for AI discovery generated 15,335 total citations in 60 days, a 43% lift over the prior period. Automated blogging at that citation volume requires more than a scheduler. It requires a pipeline that knows the difference between content that gets cited and content that gets ignored. Jason Dowdell's analysis of 6.8 million AI citations across ChatGPT, Gemini, and Perplexity found a clear hierarchy: commercial pages dominate, followed by news and research sites, then community forums, then blogs. Your auto-blog engine workflows need to produce content that competes at the commercial-page tier. Not the blog tier. And as Jakob Nielsen frames it in his GEO Guidelines, being mentioned in AI answers is now the primary share-of-voice metric for any brand operating at scale.
Here's how to build the pipeline that actually does that.

Map Your Publishing Stack First
Before you automate a single article, you need an honest inventory of what you're actually working with. I've audited content operations for brands running anywhere from one WordPress site to fifteen CMS instances across different markets, and the pattern I keep seeing is the same: teams automate the middle of the workflow while leaving the edges manual. They connect an AI writer to a scheduler, hit publish, and call it done. The stack audit is what prevents that mistake.
Start with four questions. Which CMS instances are you publishing to? What are the content sources feeding your topic planner (keyword tools, RSS, Google Trends, internal data)? Where do approval gates currently live, and are they human or automated? And critically: what breaks when volume doubles?
Multi-CMS publishing is where most auto-blog setups fracture. If you're running WordPress for your main blog, Ghost for a newsletter-style publication, and Shopify for product-adjacent content, each platform has different API behaviors, different schema expectations, and different indexing speeds. A scheduler that works cleanly for WordPress will silently fail on Ghost if you haven't mapped the authentication flow. Shopify's blog API has rate limits that matter at scale. Wix's webhook behavior is different again. Map every CMS endpoint before you wire anything to it.
The other thing to inventory: your approval gates. Most teams have informal quality checks that live in someone's head. Before automating, write those down as explicit criteria. What makes a post publishable? Minimum word count? Source requirements? Tone match? These become your quality gate inputs in Step 2. If you can't articulate the criteria, you can't automate the check.
For multi-domain operations, the Meev platform handles up to 15 domains on the Agency tier, with per-domain brand voice, topic planning, and publishing configurations. That's the kind of structural separation that makes multi-CMS publishing manageable rather than chaotic. But even if you're using a different stack, the principle holds: treat each domain as its own publishing entity with its own rules, not as a copy-paste of the first one.
One more thing the stack audit should surface: cannibalization risk. If your topic planner is pulling from six keyword sources simultaneously, it will generate overlapping topics. Catching that before publish is trivially easy. Catching it after you've published 40 articles on slight variations of the same query is a painful manual cleanup. Build the cannibalization check into the inventory phase, not as a retrospective.
Step 2. Connect Your Content Engine to a Quality Gate
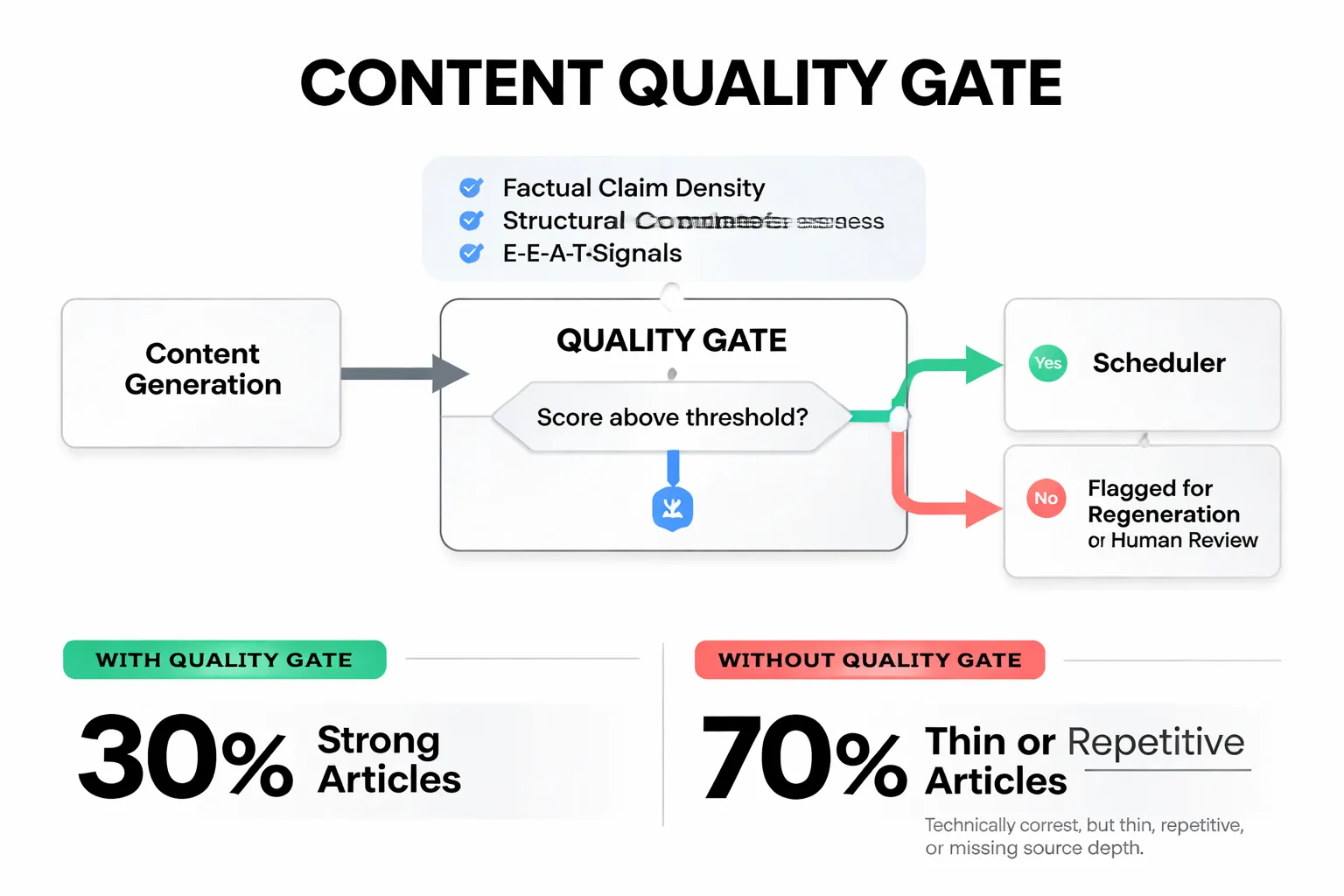
This is the step most automated blogging setups skip entirely. They generate, they schedule, they publish. No gate. The result is a corpus of content where 30% of articles are genuinely strong and 70% are technically correct but thin, repetitive, or missing the kind of source depth that gets cited by AI engines.
A quality gate is a scoring layer that sits between content generation and the publish queue. Every draft passes through it. Drafts that score above the threshold go to the scheduler. Drafts that score below get flagged for regeneration or human review. The gate doesn't slow your pipeline down. It makes your pipeline's output worth publishing.
What should the gate measure? At minimum: factual claim density (are assertions supported by named sources?), structural completeness (does the article have a clear answer to the primary query in the first 200 words?), E-E-A-T signals (is there a named author entity, first-person expertise markers, or cited experience?), internal link coverage, and duplicate content risk. A well-designed gate also checks for keyword cannibalization against your existing corpus and flags any article that would compete with a page already ranking in the top 10.
Meev's quality firewall runs on a 16-dimension Portfolio Quality Metric, combining 11 article-quality signals with a 5-dimension Google Penalty Risk Matrix. Any article scoring below 70 out of 100 is blocked from auto-publishing. That's not a soft warning. The article doesn't go out. This is worth dwelling on because no other auto-blog tool in the market has an equivalent blocking mechanism. Most competitors ship whatever the model produces. The 16-dimension gate is what separates automated blogging from scaled content abuse, which Google's Helpful Content System actively penalizes.
For teams building their own quality gate outside a platform like Meev, the practical implementation looks like this: after content generation, run the draft through a scoring script that checks word count, source count, heading structure, and a duplicate-content hash against your existing URL list. Assign point values. Set a threshold. Route below-threshold drafts to a review queue rather than the publish queue. This is buildable in n8n or Make with a few API calls, but it requires you to define the scoring criteria explicitly. Which brings you back to the stack audit you did in Step 1.
One thing I'd flag: don't let your quality gate become a vanity metric. I've seen teams set a 60/100 threshold and then watch their gate pass 95% of drafts because the scoring criteria were too loose. Calibrate your threshold against your actual best-performing content. Pull your top 10 articles by organic traffic and AI citation count, score them against your criteria, and set your threshold at the median of that group. That's a defensible baseline.
For AEO-specific quality signals, your gate should also check whether the article contains at least one 40-60 word self-contained answer in the first section. AI engines extract from the top of documents. If your opener is a scene-setter with no extractable claim, it won't get cited regardless of how good the rest of the article is.
Step 3. Add AI Visibility Monitoring to the Same Pipeline
This is where most auto-blog setups are completely blind. They track rankings. They track traffic. They don't track whether any of their published content is being cited in ChatGPT, Perplexity, Google AI Overviews, or Claude. That's a significant gap in 2026, when AI-powered search is handling a substantial and growing share of all queries.
The problem I keep running into is that teams treat AI visibility monitoring as a separate discipline from content publishing. They might check their brand mentions in Perplexity once a month, manually, in a browser tab. That's not a workflow. That's a spot check. What you need is citation tracking wired directly into your publishing pipeline so that every article that goes live immediately enters a monitoring queue, and you get signal on its citation performance within days, not weeks.
How the monitoring layer works in practice: after each article publishes, your pipeline should automatically log the URL, the primary keyword, and the publish date to your AI visibility tracking system. That system then probes the relevant AI search surfaces. ChatGPT, Claude, Gemini, Perplexity, Grok, Google AI Overviews, Google AI Mode, DeepSeek. Using queries matched to the article's target topics. When the article gets cited, you capture the mention position (first, in a list, buried at the end), the response text, and the citing surface. When it doesn't get cited, you flag it as a mention-citation gap and route it back for content improvement.
The mention-citation gap is the metric most teams aren't measuring. It's the difference between your brand being mentioned somewhere on the web and your content actually being pulled into an AI-generated answer. Jason Dowdell's analysis makes this distinction explicit: citations represent unaided brand awareness, while recommendations represent actual visibility. Both need separate measurement. A brand that's mentioned 500 times but cited in zero AI answers has a mention-citation gap problem, not a content volume problem.
For Perplexity specifically, source selection follows a different logic than Google ranking. Perplexity's Sonar API prioritizes freshness, source authority, and structural clarity. An article that ranks #4 on Google might be Perplexity's first citation if it has cleaner answer structure and more recent data. That asymmetry is why you need per-surface tracking, not just aggregate visibility scores.
Meev handles this monitoring architecture natively. Every published article enters the AI visibility tracking queue automatically. The platform tracks mention position across every major AI search surface, surfaces the actual response text behind each mention, and generates a per-article citation report. The Citation Path feature goes further: it identifies which publishers AI engines are citing for your topics, surfaces verified contact information, and drafts outreach pitches grounded in your knowledge base. That closes the loop from "we're not being cited" to "here's who to contact and what to say."
For teams building their own monitoring layer: the core requirement is a query library matched to your published content. For each article, generate 3-5 queries a user might type into ChatGPT or Perplexity to find that information. Run those queries on a scheduled basis (daily for high-priority topics, weekly for evergreen content). Log the responses. Parse them for your brand name and domain. Track whether your URL appears in citations. This is buildable, but it's operationally intensive at scale. At 80+ articles per month, manual query monitoring becomes a full-time job. That's where a dedicated ai search visibility tool earns its cost.
The GEO research on arXiv (2311.09735) frames the broader principle: topical authority affects LLM citation patterns. But topical authority isn't just about publishing volume. It's about publishing consistently on a topic cluster, with each article citing credible sources and linking internally to related content. Your monitoring layer should track citation rates by topic cluster, not just by individual article, so you can see whether your authority is building or stagnating in each area.
Is your auto-blog engine tracking which articles get cited by ChatGPT and Perplexity — or just counting page views?
Step 4. Schedule, Publish, and Verify Across Channels
The scheduling layer is where the workflow becomes tangible. You have a quality-gated content queue. You have monitoring attached to every article that publishes. Now you need the mechanics of actually getting content out the door across multiple channels, on a consistent cadence, without manual intervention.
Scheduling logic that actually works: don't publish everything at once. Spread articles across the week with timezone awareness. If your primary audience is US-based, publishing at 2am EST means your article enters the index during low-traffic hours and gets its first crawl before the morning search spike. That's a minor advantage, but at scale it compounds. More importantly, stagger your publishing cadence so you're not flooding Google's crawl budget on a single day. For a site publishing 20 articles per month, that's roughly one article every 1.5 days. For 80 articles per month, you're looking at 2-3 per day, which requires careful scheduling to avoid cannibalization between articles publishing in the same week.
For multi-CMS publishing, each platform needs its own API configuration. WordPress uses the REST API with application passwords. Ghost uses its Admin API with JWT authentication. Shopify's Blog Posts API has a rate limit of 2 requests per second per app. Wix requires webhook configuration through their Velo platform. Custom endpoints need their own authentication flow. The point isn't to memorize these. It's to document them in your stack audit (Step 1) and test each connection before you automate anything at volume.
Post-publish verification is the step teams skip when they're confident in their quality gate. Don't skip it. In the first 48 hours after each article goes live, verify four things: the article is indexed (check Google Search Console for the URL in the coverage report), the IndexNow ping was received (your publishing platform should log this), the schema markup is rendering correctly (use Google's Rich Results Test), and the internal links are resolving without 404s. These are mechanical checks, not quality checks. A quality-gated article can still fail on all four if there's a CMS configuration issue or a publishing API error.
Meev handles IndexNow pinging and Google Search Console sitemap submission automatically on every publish. That dual-indexing approach is something most auto-bloggers don't implement. They rely on Google's crawler finding new content organically, which can take days. IndexNow gets the URL in front of Bing and other participating search engines within hours. GSC submission accelerates Google's awareness. Together, they compress the time between publish and first crawl significantly.
For the AEO vs GEO dimension of your post-publish checklist: within 48 hours, run your article's primary query through at least two AI search surfaces manually. Note whether your article appears in citations. If it doesn't, check whether the article's first 200 words contain a self-contained answer to the query. If they don't, that's your fix. AI engines extract from the top of documents. An article that buries its answer in paragraph four will not get cited, regardless of how strong the rest of the content is.

Where Auto-Blog Engine Workflows Break Down
I want to be direct about the failure modes here, because every how-to article on automation glosses over them.
Failure mode 1: The quality gate passes content that's technically correct but strategically wrong. A 16-dimension scoring system can miss whether an article is actually differentiated from the 50 other articles on the same topic. Scoring for structure and source density doesn't score for information gain. If your article says the same thing as every competitor, it will pass your quality gate and fail to get cited by any AI engine. The fix is adding an information gain check: does this article contain at least one claim, data point, or example that isn't in the top 5 competing pages? That's a harder check to automate, but it's the one that actually predicts citation performance.
Failure mode 2: Monitoring data becomes noise at scale. When you're tracking citation performance across 200+ articles and multiple AI search surfaces, the signal-to-noise ratio drops fast. Teams end up with dashboards full of data and no clear action. The fix is ruthless prioritization: track citation rates by topic cluster, not by individual article, and focus optimization effort on clusters where you're getting impressions but no citations.
Failure mode 3: Multi-CMS publishing creates content that's identical across domains. If you're auto-publishing the same article to five domains with minor variations, Google's Helpful Content System will flag it as scaled content abuse. Each domain needs genuinely distinct content, not spun versions of the same draft. Your content engine needs per-domain knowledge bases and voice configurations, not a single template applied everywhere.
Frequently Asked Questions
How many articles per month can an auto-blog engine workflow handle before quality degrades?
Quality degradation isn't a function of volume. It's a function of gate strength. A workflow with a properly calibrated quality gate can handle 150+ articles per month without degradation. The risk is that teams raise their publishing volume without recalibrating their quality threshold. If your gate was set based on a 20-article-per-month corpus, it needs recalibration when you scale to 80. Meev's self-learning engine analyzes article patterns monthly and refines quality criteria automatically, which addresses this without manual recalibration.
Does publishing more content improve AI citation rates, or does quality matter more?
Both matter, but in different ways. Volume builds topical authority signals that AI engines use to evaluate source credibility. Quality determines whether individual articles get extracted and cited. The GEO research (arXiv:2311.09735) frames topical authority as a citation driver, but Jason Dowdell's 6.8 million citation analysis shows that commercial pages and news/research sites dominate citation hierarchies regardless of volume. The practical answer: publish consistently on a topic cluster, but make each article citation-worthy on its own merits.
What's the difference between an AI citation and an AI recommendation, and why does it matter for my workflow?
A citation is your brand or URL appearing in an AI-generated answer. A recommendation is the AI actively suggesting your brand as the solution to a user's problem. These are different visibility metrics and require different content strategies. Citations are won through structural clarity and source authority. Recommendations are won through brand sentiment, review signals, and consistent presence across multiple AI surfaces. Your auto-blog engine workflow should optimize for citations first. Recommendations follow from citation density over time.
How do I know if my automated content is triggering Google's Scaled Content Abuse policy?
The clearest signal is a manual action in Google Search Console. But you can detect risk earlier by checking your content against three criteria: Is each article genuinely differentiated from your existing corpus? Does each article serve a distinct user intent? Is there a named author entity with verifiable credentials attached to each piece? If you're auto-publishing without author entity profiles, without information gain checks, and without per-domain voice differentiation, you're in the risk zone. Meev's 5-dimension Google Penalty Risk Matrix scores each article against these criteria before publish.
Can I run this workflow without a dedicated platform like Meev?
Yes, but the operational cost is significant. You'd need to stitch together an AI writer, a quality scoring script, a multi-CMS publishing layer, and a separate AI visibility monitoring tool. The monitoring layer alone requires a query library, scheduled API calls to multiple AI search surfaces, and a logging system. That's buildable in n8n or Make, but it's a 40-60 hour build and an ongoing maintenance burden. The platform approach makes sense when you're publishing more than 30 articles per month across more than one domain. Below that threshold, a manual workflow with spot-checks is often more efficient.
About the Author
Judy Zhou, Founder
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Wire AI visibility monitoring into your publishing pipeline today and stop flying blind on LLM citations.