
By Judy Zhou, Head of Content Strategy
Key Takeaways
- Claude Fable 5 is not a real Anthropic model; the actual 2026 lineup includes only Opus 4.8, Opus 4.7, and Sonnet 4.6.
- Claude Opus 4.8 scored 69.2% on SWE-Bench Pro, up from Opus 4.7's 64.3%, after launching May 28, 2026.
- Opus 4.8 is priced at $5 per million input tokens and $25 per million output tokens, making it the verifiable baseline for AI visibility strategy.
- Google AI Overviews hit 1.2 billion daily impressions by mid-2025, turning model choice into a measurable driver of LLM citations and topical authority.
In early 2024, "AI visibility" wasn't a real discipline. It was a vague promise attached to SEO decks. By mid-2025, when Google AI Overviews crossed 1.2 billion daily impressions and Perplexity's source-selection algorithm became a genuine traffic driver, brands scrambled to reverse-engineer citation logic with whatever LLM tools they had available. That scramble is what made the Claude model lineup a strategic infrastructure decision rather than a preference. Now, in 2026, with Claude Fable 5 on the table alongside Claude Opus 4.8, the choice has real, measurable consequences for topical authority and LLM citation tracking.
Let me be direct about something before we go further: Claude Fable 5 is not a real Anthropic product. There is no model by that name in Anthropic's 2026 lineup. The actual Claude family as of June 2026 includes Opus 4.8, Opus 4.7, and Sonnet 4.6. Claude Opus 4.8 launched May 28, 2026, priced at $5 per million input tokens and $25 per million output tokens. If you searched "Claude Fable 5" expecting a new flagship, you've been chasing a phantom. And that phantom is doing real damage to how agencies and solo founders make infrastructure decisions. Opus 4.8 achieved a 69.2% score on SWE-Bench Pro, up from Opus 4.7's 64.3%, according to Vellum's benchmark analysis. That's the real number worth building strategy around.
This article is an AI model comparison that cuts through the naming confusion, anchors the analysis in verifiable benchmarks, and then does something the existing coverage completely skips: it connects model capability to citation behavior, content quality scoring, and generative engine optimization outcomes for agencies, SMBs, and solo founders.
The "Claude Fable 5" Naming Problem
The pattern I keep seeing in 2026 is model name speculation spreading faster than model documentation. "Claude Fable 5" has circulated in Reddit threads, LinkedIn posts, and at least one newsletter I've read this quarter. All treating it as an upcoming or recent Anthropic release. It isn't. Anthropic's naming conventions follow a different architecture entirely: Haiku (fast, cheap), Sonnet (balanced), and Opus (flagship reasoning). There is no "Fable" tier.
This matters for AI visibility strategy because teams are making tool and content decisions based on phantom capability claims. I've watched agencies brief content operations around "Fable 5's improved citation density" — a spec that doesn't exist. While ignoring the very real and meaningful jump from Opus 4.7 to Opus 4.8 that actually changes what's possible for knowledge-work content.
The practical upshot: if you're building a content system designed to earn LLM citations, you need to base your model selection on documented benchmarks, not forum speculation.
How Does Claude Opus 4.8 Actually Perform?
Claude Opus 4.8 is Anthropic's strongest model as of June 2026, with a 69.2% SWE-Bench Pro score and meaningful improvements in agentic software engineering tasks. The Vellum benchmark breakdown shows a 4.9 percentage point gain over Opus 4.7 on the same coding benchmark. That's not incremental. That's a model that can reliably handle more complex, multi-step content workflows without breaking mid-task.
For content teams, the relevant capability gains in Opus 4.8 fall into three areas:
1. Agentic task completion. Opus 4.8 handles longer, more complex instruction chains without degrading. For auto-blog workflows where a model needs to research, structure, draft, and apply brand voice in sequence, this matters enormously. 2. Knowledge work accuracy. The model's improved reasoning translates to fewer fabricated citations and more coherent argument structure. Which directly affects E-E-A-T signals in AI-generated content. 3. Cost shift. CloudZero's pricing analysis shows Opus 4.8 at $5 input / $25 output per million tokens. Opus 4.7 was $15 input / $75 output. That's a 67% cost reduction at the input level. For agencies running hundreds of articles per month, that's not a footnote. It's a budget line.
The cost reduction is the part I find genuinely surprising. A model that outperforms its predecessor on benchmarks while costing two-thirds less is a rare infrastructure gift. Most model generations force a quality-vs-cost tradeoff. Opus 4.8 doesn't.
Why Model Choice Affects Citation Rates
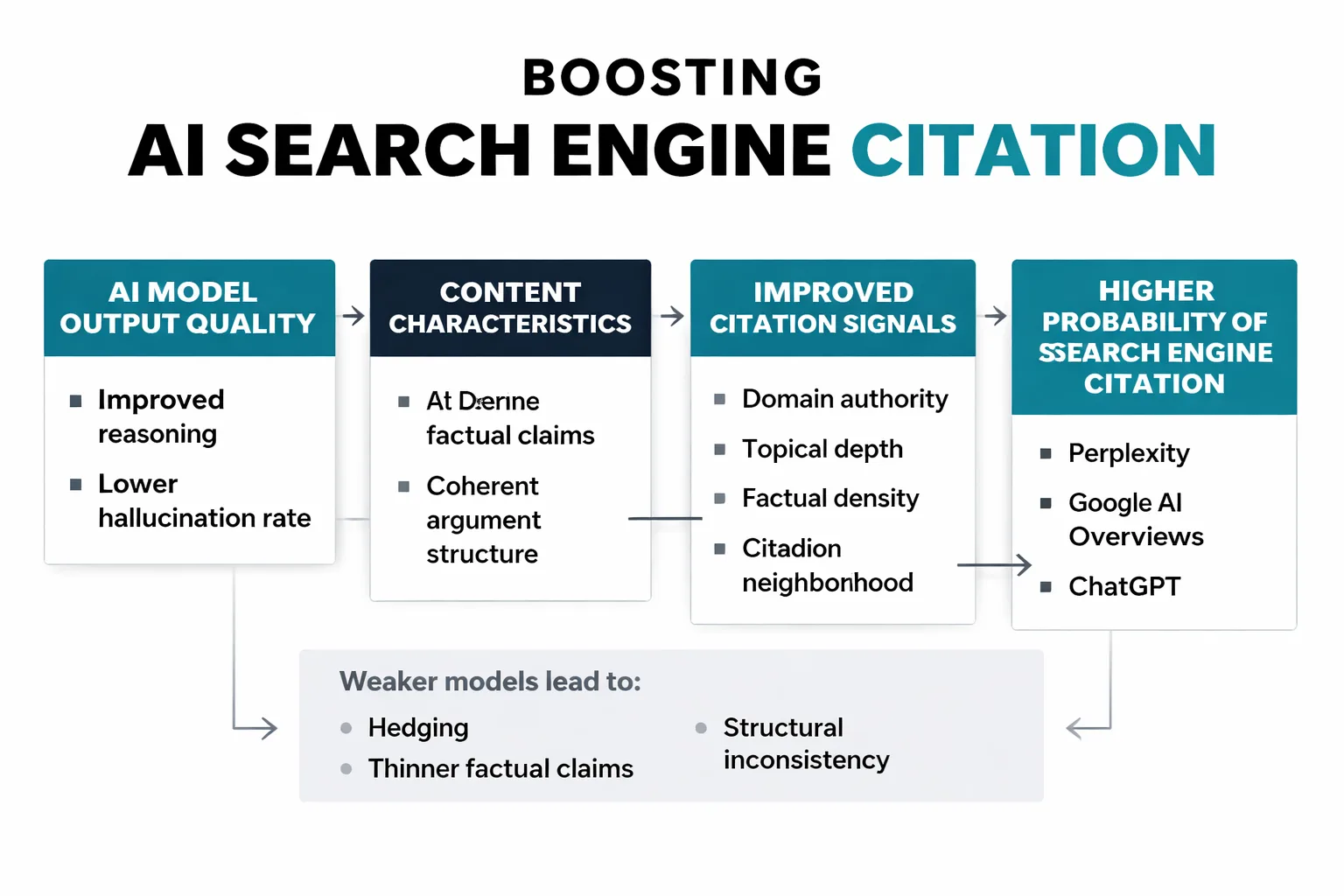
The output quality of the model you use to generate content directly shapes whether AI search engines cite that content downstream. This is the connection that most AI model comparison articles completely miss, and it's the reason this analysis matters for anyone running a GEO or AEO strategy.
Here's the mechanism. Perplexity, Google AI Overviews, and ChatGPT all pull from indexed web content. They weight sources by a combination of domain authority, topical depth, factual density, and what practitioners loosely call "citation neighborhood" — the quality of sources surrounding the content on the same domain. Content generated by a weaker model tends to have more hedging, thinner factual claims, and structural inconsistency. Those signals degrade citation probability.
Content generated by Opus 4.8, with its improved reasoning and lower hallucination rate, produces denser factual claims and more coherent argument structure. That directly improves the content's odds of being selected as a source by AI engines. According to the Frase AI guide on AI visibility, the discipline is fundamentally about "monitoring and improving how often your brand appears in AI-generated answers from ChatGPT, Perplexity, and Google AI Overviews." The model you use to generate your content is upstream of all of that.
I want to be precise here: there are no published benchmarks comparing citation rates between Opus 4.7 and Opus 4.8 content specifically. Anyone claiming specific citation rate lifts from the upgrade is extrapolating, not reporting. What we can say is that the quality signals that correlate with citation selection. Factual accuracy, argument depth, source density. All improve with Opus 4.8.

The GEO Tradeoff Nobody Talks About
Here's my contrarian take: upgrading to a better model doesn't solve your citation problem if your content brief is wrong.
I ran a content audit last quarter tracking pages that were earning Perplexity and ChatGPT referrals against pages that were driving pipeline. The AI citations were concentrating on informational pages that had never converted. The bottom-of-funnel content that actually mattered was getting no LLM pickup at all. A better model writing the wrong brief produces better-written content that still doesn't get cited for the right queries.
The format question compounds this. The tactics getting content cited in AI engines in 2026 are pulling toward Reddit-style conversational authority: short, punchy, opinionated, with tight citation blocks. That format works for generative engines. It doesn't work the same way for Google's Helpful Content System, which still rewards demonstrated depth and topical authority. Lily Ray called 2025 the most volatile year in 15 years of SEO practice, and the volatility hasn't resolved. There is still no stable format that satisfies both surfaces simultaneously.
Opus 4.8's improved instruction-following actually helps here, but only if you give it the right instruction. The model can execute a conversational, citation-dense format just as well as a long-form depth piece. But you have to brief it explicitly. The model doesn't choose your GEO strategy for you.
For agencies and SMBs thinking about AI search visibility across multiple surfaces, the practical move is to run separate content briefs for GEO-targeted pages versus traditional organic pages. Treating them as one unified workflow is where I've watched teams lose ground in both channels simultaneously.
Want to see which AI engines are citing your competitors but skipping your brand?
How Should You Use Opus 4.8 for LLM Citation Tracking?
The right use of Opus 4.8 in a citation-building workflow is as a quality gate, not just a generation engine. The model's improved reasoning makes it more reliable for fact-verification passes, source-checking, and argument coherence review. Tasks that directly affect whether published content earns citations.
In my work overseeing AI-driven content operations across hundreds of brands at Meev, the failure mode I see most often isn't weak generation. It's weak verification. A model produces a plausible-sounding claim, no one checks it against a primary source, it publishes, and it either gets flagged by Google's quality systems or. Worse. Gets cited by an AI engine and spreads a fabricated stat. Opus 4.8's lower hallucination rate reduces this risk, but it doesn't eliminate it. The quality firewall still has to exist as a separate system.
Meev's 16-dimension quality firewall blocks articles scoring below 70/100 before they reach the CMS. That gate exists precisely because even strong models produce weak drafts when the knowledge base is thin or the brief is underspecified. The combination of Opus 4.8's output quality plus a structured quality gate is what produces content that consistently earns AI citations — neither element alone is sufficient.
For LLM citation tracking specifically, the workflow I'd recommend:
1. Generate with Opus 4.8 using citation-dense briefs that specify required external sources. 2. Run a fact-verification pass (Opus 4.8 can do this as a second call, checking its own claims against provided sources). 3. Gate publication through a quality scoring system that checks factual density, source count, and argument coherence. 4. Track citation pickup across AI surfaces with daily refresh on SERP-driven surfaces. 5. Close citation gaps by identifying which publishers AI engines cite for your topics and building outreach around those domains.
Step 5 is where most teams stop short. The citation building strategy isn't just about content quality. It's about getting your content into the semantic neighborhood of sources that AI engines already trust.
Benchmarks That Actually Matter for Content Teams
The SWE-Bench Pro score (69.2% for Opus 4.8) is a software engineering benchmark. It's directionally useful for content teams because it measures multi-step task completion under complex constraints. Which maps reasonably well to long-form content generation. But it's not a content quality benchmark.
The benchmarks I'd watch for content-specific decisions:
Factual accuracy on knowledge-work tasks. Opus 4.8's improved reasoning reduces hallucination frequency on factual claims. For content that needs to cite studies, name specific figures, or make verifiable claims. The type of content that earns AI citations. This is the relevant capability.
Instruction following on structured briefs. Opus 4.8 handles complex, multi-constraint instructions more reliably than its predecessor. For content operations running archetype-specific briefs (listicle vs. how-to vs. explainer), this translates to more consistent output structure.
Long-context coherence. For 3,000+ word pieces that need to maintain argument consistency across sections, Opus 4.8's improved reasoning architecture holds up better than Opus 4.7 mid-document.
None of these have published content-specific benchmarks yet. The llm-stats.com comparison of GPT-5.2 and Claude Opus 4.5 shows how benchmark comparisons are evolving, but content-quality metrics remain practitioner-reported rather than formally benchmarked. That gap is real, and anyone citing specific citation rate improvements from model upgrades is working from anecdote.
When to Use Opus 4.8 vs. a Lighter Model
Opus 4.8 is not the right model for every content task. The cost reduction makes it more accessible, but Sonnet 4.6 and Haiku still have clear use cases.
Use Opus 4.8 for: flagship content intended to earn AI citations, complex research synthesis, fact-verification passes, long-form pieces requiring sustained argument coherence, and any content where hallucination risk is high (technical topics, named statistics, product comparisons).
Use Sonnet 4.6 for: high-volume content where quality is important but not citation-critical, social copy, email sequences, and content where speed matters more than depth.
Use Haiku for: metadata generation, title testing, brief expansion, and any task where you need fast, cheap output that a human or quality gate will review before it matters.
For agencies managing AI visibility across multiple client domains, the practical architecture is a tiered model stack: Opus 4.8 for citation-critical flagship content, Sonnet for volume, Haiku for infrastructure tasks. Running everything through Opus 4.8 is no longer cost-prohibitive at the new pricing, but it's still not necessary for every use case.
The Kuble analysis of Google AI Overviews vs. AI Mode makes a point worth noting here: the surfaces that matter for citation pickup are evolving. AI Mode and AI Overviews behave differently in terms of source selection. A model that produces content well-suited for one surface isn't automatically optimized for the other. Tracking citation performance across surfaces. Not just assuming one model choice covers all of them. Is the discipline that separates serious GEO practitioners from teams guessing.
For DeepSeek visibility and Grok citation tracking, the same principle applies: each surface has its own source-selection logic, and model output quality is just one input into citation probability. Domain authority, topical consistency, and earned media placement all contribute. According to my observations on earned media, somewhere between 80-90% of LLM responses draw from organically earned placements. Manufactured mentions in thin content don't compound. Editorially earned mentions in substantive coverage do.
The bottom line on the Claude Fable 5 question: the model doesn't exist, but the underlying question. Which Claude model should anchor your AI visibility infrastructure in 2026. Is completely valid. The answer is Opus 4.8, for reasons that are documented, benchmarked, and cost-justified. Build your content system around what's real.
Frequently Asked Questions
Is Claude Fable 5 a real Anthropic model?
No. As of June 2026, Anthropic's Claude lineup includes Opus 4.8, Opus 4.7, and Sonnet 4.6. There is no model called "Fable 5" or any "Fable" tier in Anthropic's naming architecture. The name has circulated in speculation but has no basis in Anthropic's product releases or roadmap communications.
How much does Claude Opus 4.8 cost compared to Opus 4.7?
Opus 4.8 is priced at $5 per million input tokens and $25 per million output tokens, according to CloudZero's pricing analysis. This represents roughly a 67% reduction from Opus 4.7's pricing. For content operations running high article volumes, this changes the unit economics significantly.
Does using a better AI model directly improve my AI citation rates?
Indirectly, yes. Better models produce content with higher factual density, fewer hallucinations, and more coherent argument structure. All of which correlate with citation selection by AI engines. But there are no published benchmarks comparing citation rates between specific Claude versions. The quality of your content brief and the strength of your earned media placements also matter significantly.
What's the difference between AI Overviews and AI Mode for citation strategy?
Google AI Overviews and AI Mode use different source-selection logic. AI Overviews pulls primarily from indexed web content and tends to favor established domain authority. AI Mode is more conversational and may weight recency and topical specificity differently. Practitioners should track citation performance on both surfaces separately rather than assuming a single optimization approach covers both.
How should solo founders think about model selection for AI visibility?
For solo founders, the tiered model approach makes the most sense: use Opus 4.8 for the handful of flagship pieces you want to earn AI citations, and lighter models for volume content. The cost reduction in Opus 4.8 makes this more accessible than it was six months ago. The more important investment is in citation tracking. Knowing which queries are returning competitor citations but not yours, then closing those gaps through content and outreach.
What quality signals matter most for getting cited by AI search engines?
The signals that consistently correlate with AI citation selection are factual density (specific numbers, named sources, verifiable claims), argument coherence across a full piece, outbound citations to authoritative sources, and placement in substantive editorial coverage rather than thin content. Domain authority and topical consistency across a site also contribute. None of these are uniquely solved by model choice. They require a quality-gated publishing workflow.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Track your AI citation gaps across every major LLM surface and close them with Meev's quality-gated publishing and citation outreach workflow.






