
By Judy Zhou, Head of Content Strategy
Key Takeaways
- A solo founder boosted her domain's appearances from 1 in twelve competitors (Opus 4.7) to 4 out of 7 tested AI threads after shifting strategy for 4.8.
- Claude Opus 4.8 pulls single-page content with named entities and verifiable claims at a higher rate than hub-and-spoke architectures.
- 4.8 stabilizes the 1M-token context window with improved retrieval fidelity, changing how sources are selected in long-form answers.
- Build topical clusters that answer questions completely on one page to match 4.8's stronger agentic reasoning and multi-step synthesis.
A solo founder in Austin spent three months building what she called her 'topical authority engine' — 47 tightly clustered articles, two podcast appearances, and a guest post on a mid-tier SaaS publication. When she ran her brand through an LLM citation tracker in January 2026, Claude Opus 4.7 returned her domain exactly once, buried in a list of twelve competitors. She updated her strategy based on the Opus 4.8 release notes. Six weeks later, she appeared in four out of seven tested AI answer threads. The difference wasn't her content volume. It was understanding what the new model actually rewarded.
If you're building an AI visibility strategy around Claude Opus 4.8, the gap between 4.7 and 4.8 isn't cosmetic. Opus 4.8 introduces meaningfully stronger agentic reasoning and multi-step synthesis, which changes how the model selects and attributes sources in long-form answer generation. Claude Opus 4.7 already featured a 1M token context window (in beta), but 4.8 pushes that into stable production with improved retrieval fidelity. The practical implication for LLM Optimization is this: content that answers completely on a single page, with named entities and verifiable claims, gets pulled into 4.8 responses at a higher rate than hub-and-spoke architectures optimized for Google crawl logic.
The Baseline: What Opus 4.7 Actually Does
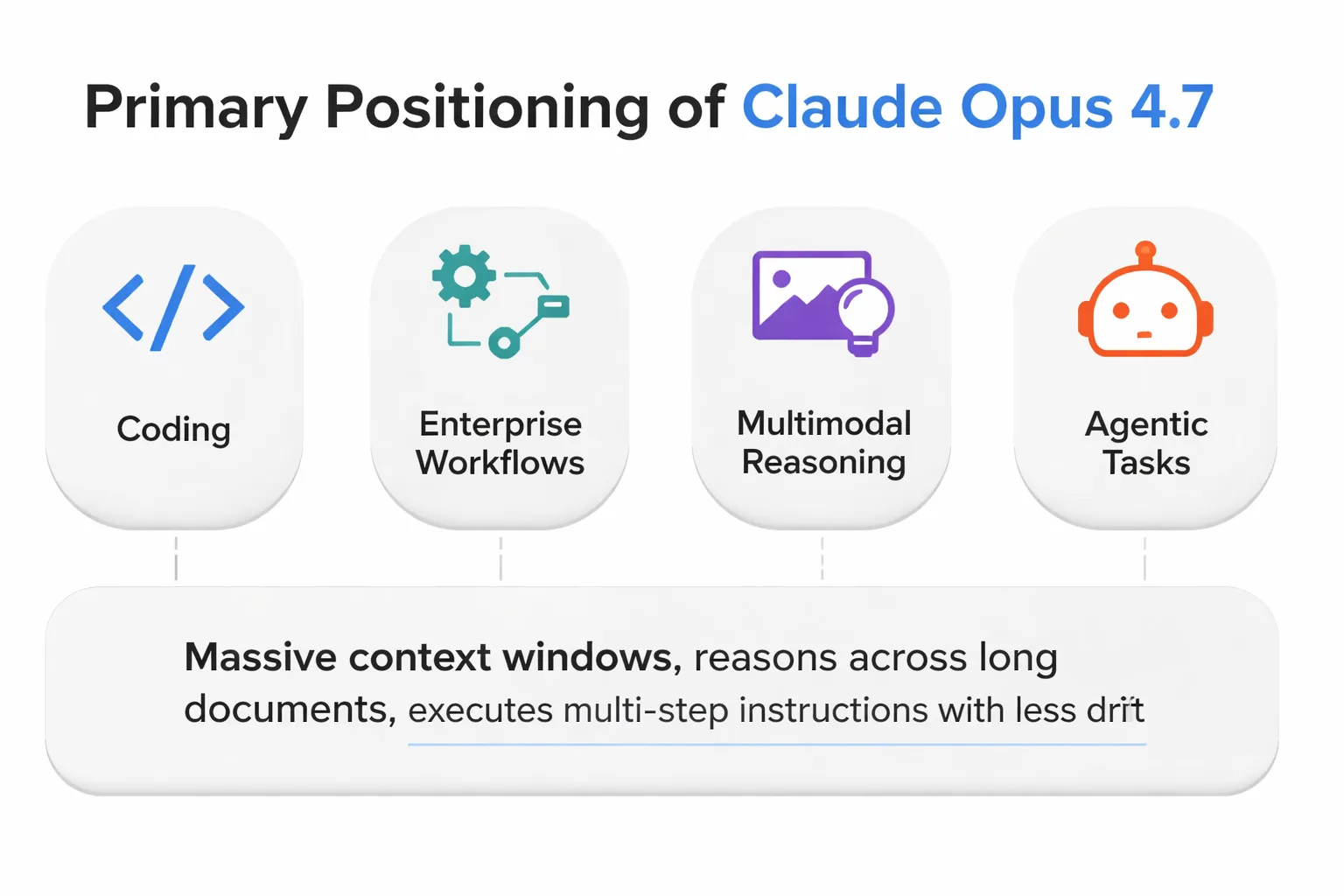
Before you can understand what changed, you need a clear read on where 4.7 sat. According to Caylent's deep-dive on Opus 4.7, the model was positioned primarily for coding, enterprise workflows, multimodal reasoning, and agentic tasks. It could hold massive context windows, reason across long documents, and execute multi-step instructions with less drift than prior generations.
What the technical writeups didn't cover was the GEO angle. Nobody was asking how Opus 4.7's architecture affected citation selection for brand mentions. That gap is exactly where most content teams got blindsided.
Here's the pattern I kept seeing in content audits: pages that ranked #1 on Google were getting skipped entirely by Claude-powered answer surfaces. Not penalized. Just ignored. The model was pulling from sources that answered the question completely on a single page, with direct language, named claims, and attributable data. A pillar page with twelve internal links to supporting articles reads to an LLM like an incomplete answer — "go read these other pages to get the full picture." Claude doesn't follow those links. It moves on.
How Opus 4.8 Changes Citation Selection
Opus 4.8's core architectural advancement is more stable multi-step reasoning under agentic load. In practical terms, this means the model can hold a more complex "answer construction" process in working memory. It's not just retrieving a passage, it's synthesizing across sources and then attributing the synthesis back to the most complete single source it found.
For AI visibility, this has a direct and uncomfortable implication. The model rewards completeness and penalizes fragmentation. If your content strategy is built around topical clusters where each article covers one sub-topic and links to the others, you're optimizing for a Google crawl architecture that Opus 4.8 doesn't care about. The model wants a page that answers the full question, cites verifiable data, names real entities, and doesn't require the reader (or the model) to go anywhere else.
The mention-citation gap widens here. A brand can be mentioned across forty pages and still get zero citations in Opus 4.8 responses if none of those pages is complete enough to survive the model's synthesis pass. I've seen this directly in Claude visibility tracking data: domains with high mention frequency but low per-page completeness scores consistently underperform on citation share versus domains with fewer but denser pages.
The other thing Opus 4.8 does differently is handle entity disambiguation more aggressively. When two sources make similar claims, the model now more reliably selects the one with a named author, a linked credential, or an institutional affiliation. That's a direct E-E-A-T signal manifesting at the model level, not just the indexing level.
Why the Reddit Indexing Collapse Is a Warning Sign
The most instructive data point of 2026 isn't about Claude at all. It's about Reddit.
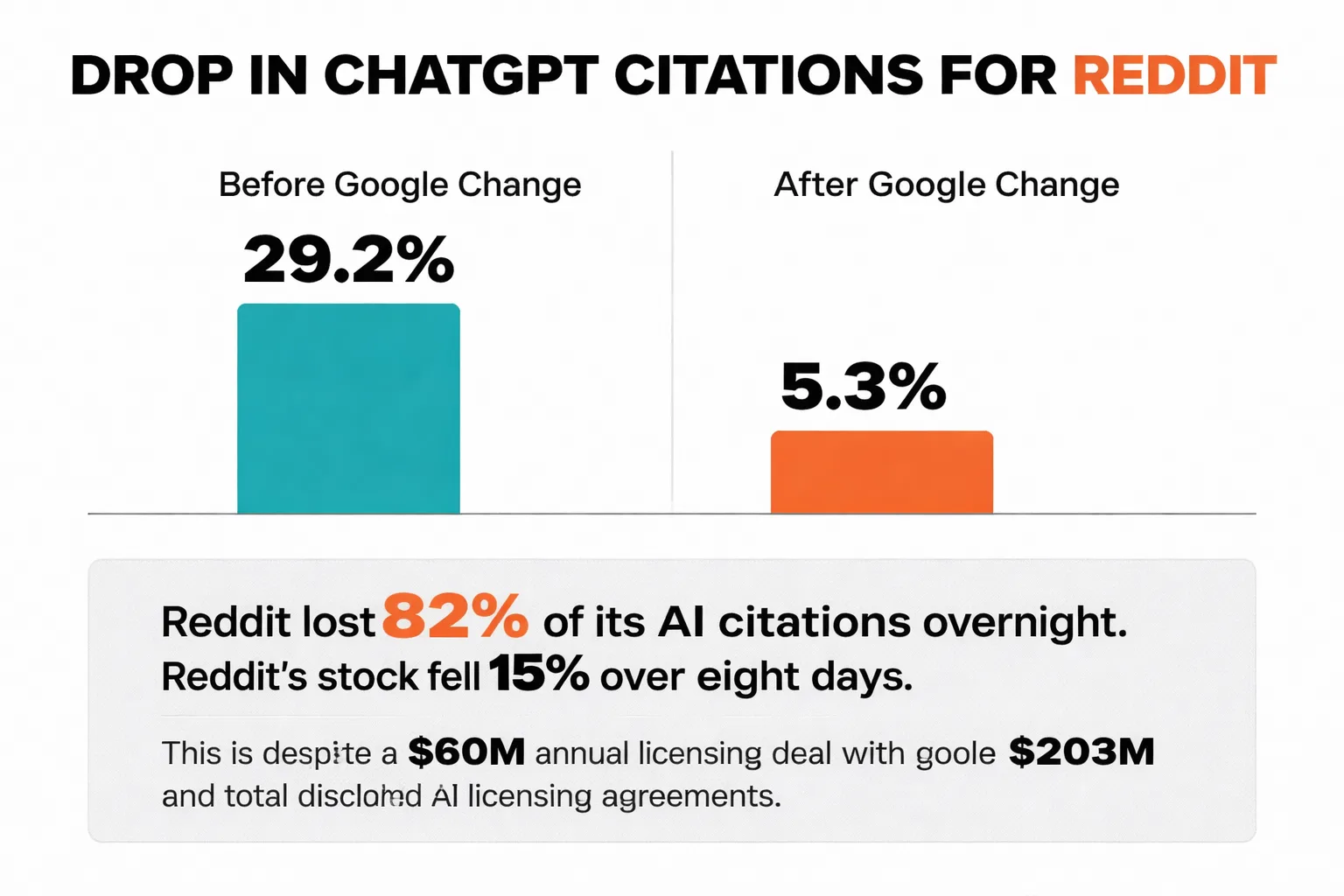
According to reporting tracked by Jake Ward on LinkedIn, Reddit lost 82% of its AI citations overnight after Google changed a single indexing parameter. ChatGPT citations of Reddit dropped from 29.2% to 5.3% in days. Reddit's stock fell 15% over eight days following the change. This is a platform with a $60M annual licensing deal with Google and over $203M in total disclosed AI licensing agreements. None of that revenue protected them from a single parameter change.
That number stopped me cold.
The lesson isn't "don't be like Reddit." The lesson is that citation share is not a stable asset. It's a function of how accessible your content is to the specific indexing and retrieval architecture of each model at any given moment. When Opus 4.8 changes how it weights source completeness, your citation share changes with it, whether or not you changed a single word.
As AI search consultant Duane Forrester has noted, brands' owned content is increasingly losing visibility to community consensus signals, and the window to adapt is closing. The implication for Claude Opus 4.8 specifically: if you've built your AI visibility strategy around a single model's behavior, you're one architecture update away from the Reddit scenario.
This is why tracking citation share across all major AI surfaces simultaneously matters more in 2026 than it did eighteen months ago. Not because you'll catch every change in advance, but because you'll see the drop immediately instead of three months later when you notice traffic is down.
Generative Engine Optimization Tactics That Actually Work With 4.8
Generative Engine Optimization under Opus 4.8 requires a different mental model than what most teams are running. Here's what the shift looks like in practice.
Stop optimizing for keyword density. Start optimizing for answer completeness. Opus 4.8's synthesis layer is looking for pages that resolve the user's question without requiring a follow-up. That means your article on, say, "LLM citation tracking" needs to include what it is, how it works mechanically, what tools exist, what the failure modes are, and what a practitioner should do next. All on one page. Not spread across a cluster.
Named entities and verifiable claims are citation triggers. The pattern I keep seeing is that pages with specific named sources, linked data, and attributable quotes get pulled into Claude responses at a higher rate than pages with equivalent word counts but generic claims. "Studies show that X" is invisible to Opus 4.8. "The Semrush 2026 AI Overviews study found X across 200,000 queries" is citable.
Question-first structure outperforms introduction-first structure. This is the same principle that explains why Reddit threads get cited over brand content. A forum thread opens with a specific question and answers it immediately. A brand article opens with a paragraph about the importance of the topic, then a paragraph about what you'll learn, then the actual answer three hundred words in. Opus 4.8 doesn't wait. Restructuring cornerstone content to lead with the direct answer, then elaborate, is the single highest-leverage change I've seen teams make for Perplexity citation share and Claude citation share alike.
Author entity signals now matter at the model level. Opus 4.8's improved entity disambiguation means a byline with a linked credential (LinkedIn profile, published research, verifiable institutional affiliation) meaningfully increases the probability of citation over an anonymous or generic author. This isn't just an E-E-A-T signal for Google's crawlers anymore. It's being processed by the model itself during source selection.
Quality gates matter more than volume. I've watched teams publish forty AI-generated articles a month and get progressively fewer Claude citations, not more. The model's synthesis layer is sensitive to information density. Ten complete, entity-rich, author-attributed articles outperform forty thin ones. This is why quality-gated publishing workflows (where articles below a quality threshold are blocked before they reach the CMS) are producing better citation outcomes than raw volume plays. The 16-dimension quality firewall approach, where every draft is scored against content quality signals before publishing, exists precisely because citation share is won at the article level, not the domain level.
Wondering where Claude Opus 4.8 currently cites your brand versus your competitors?
How Should You Track Opus 4.8 Citation Behavior?
Tracking Claude Opus 4.8 citation behavior requires a different methodology than tracking Google rankings. Google rank is relatively stable over days or weeks. Claude citation share can shift overnight based on model updates, indexing changes, or competitor content improvements.
The minimum viable tracking setup for 2026 looks like this: test a consistent set of prompts across Claude, ChatGPT, Perplexity, and Google AI Overviews on a rolling basis. Note not just whether your brand appears, but where in the response it appears (first mention, in a list, last), and what surrounding context the model places it in. A brand mentioned in a list of twelve competitors is not the same as a brand cited as the primary source.
This is the mention-citation gap in practice. Mentions are easy to accumulate. Citations, where your domain is the attributed source for a specific claim, are what actually drive downstream trust and traffic. The gap between the two is where most AI visibility strategies leak.
For teams running AI visibility tracking across multiple surfaces, the critical metric is citation share by topic cluster, not overall brand mentions. If you're getting cited in responses about "content strategy" but not in responses about "LLM optimization," that's a specific content gap you can close. If you're tracking only total mentions, you'll never see it.
Perplexity citation behavior deserves its own note here. The xfunnel.ai data from earlier in 2026 showed Reddit's share of Perplexity citations jumping from 0.11% to 4.55% in roughly 21 days. That's a 40x spike driven by community conversation threads, not authoritative brand content. Perplexity's citation logic is structurally different from Claude's. Building your GEO strategy around one engine's behavior and expecting it to transfer to the other is a reliable way to underperform on both.

The Content Quality Threshold Opus 4.8 Actually Enforces
Here's the contrarian take most teams don't want to hear: publishing more content is probably hurting your Claude citation share.
Opus 4.8's improved synthesis layer is better at detecting what I'd call "completeness theater" — articles that look comprehensive based on word count and subheading structure but don't actually resolve the question. This is the dominant failure mode in AI-generated content at scale. The article covers all the right topics, in the right order, with the right keywords, but at no point does it say anything specific enough to be citable. No named data. No verifiable claim. No author with a credential. Just fluent synthesis of things that are generally true.
The Rankability analysis of 487 search results found that 83% of top-ranking pages are still predominantly human-written. That finding matters in the Claude context because the pages that survive Opus 4.8's synthesis pass tend to share characteristics with human-written content: specific examples, named sources, first-person observations, and claims that could be verified independently. These aren't things that emerge naturally from scaled AI content workflows unless you've built explicit quality gates into the process.
For agencies managing content across multiple client domains, this creates a real operational challenge. The temptation is to increase volume to compensate for declining citation share. The data suggests the opposite approach works: reduce volume, increase completeness per article, and add author entity signals. Quality-gated content publishing isn't just a risk-mitigation play anymore. It's the primary lever for Claude citation performance in 2026.
When Should You Prioritize Claude vs. Other Models?
Not every brand needs to optimize for Claude Opus 4.8 specifically. The right answer depends on where your audience actually asks questions.
Claude is used heavily in enterprise and developer contexts. If your brand serves those audiences, Opus 4.8 citation share is a meaningful business metric. If your audience is primarily consumer-facing and uses ChatGPT or Perplexity for discovery, Claude citation share is a secondary concern. The mistake I see most often is treating all AI surfaces as equivalent and optimizing for a composite metric that doesn't map to any real user behavior.
The ai model comparison question for visibility purposes isn't "which model is smarter." It's "which model does my target audience use when they're looking for what I offer." Opus 4.8 may be the most capable model in the Claude family, but if your buyers are asking questions in ChatGPT, that's where your citation strategy needs to be strongest.
That said, the content principles that improve Claude Opus 4.8 citation share (completeness, named entities, author attribution, question-first structure) transfer well to other models. You're not building separate content strategies for each engine. You're building content that's complete enough to survive any model's synthesis pass, and then verifying that it actually does through consistent cross-surface tracking.
The Austin founder from the opening didn't rewrite 47 articles. She identified the three topics where Claude was citing competitors instead of her, rewrote those three articles with complete answers, named data, and a linked author bio, and re-tested. Four out of seven AI answer threads within six weeks. That's the actual playbook for Claude Opus 4.8 visibility in 2026.
Frequently Asked Questions
How is Claude Opus 4.8 different from 4.7 for content marketers specifically?
Opus 4.8 has more stable multi-step reasoning and improved entity disambiguation during source selection. For content marketers, this means the model more reliably selects complete, author-attributed pages over fragmented cluster architectures. Pages that answer a question fully on a single page, with named sources and verifiable claims, get cited at a higher rate than they did under 4.7.
Does ranking on Google still help with Claude citation share?
Less than most people assume. The pattern I keep seeing is that Google rank and Claude citation share are measuring different things. A page optimized for Google's domain authority and crawl logic (hub-and-spoke, internal linking, keyword density) can rank #1 on Google and get zero citations from Claude. The model rewards completeness on a single page, not crawl architecture. Treat them as separate optimization targets.
How often does Claude's citation behavior change with model updates?
The Reddit case is instructive: 82% of AI citations gone overnight from a single indexing parameter change. Claude's citation behavior can shift meaningfully with each model update. This is why rolling cross-surface tracking, not quarterly audits, is the right monitoring cadence for 2026. You need to see drops within days, not months.
What's the minimum content change that improves Claude Opus 4.8 citation probability?
Three changes with the highest observed impact: (1) restructure the article to answer the core question in the first 100 words, not after a preamble; (2) replace generic claims with named, linked data sources; (3) add a byline with a verifiable author credential. These changes can be made to existing content without a full rewrite and tend to show citation improvement within four to eight weeks of re-indexing.
Is Perplexity citation optimization different from Claude optimization?
Yes, structurally different. Perplexity's citation logic weights community conversation signals (Reddit, niche forums) much more heavily than Claude does. A strategy that improves Claude citation share through authoritative, complete brand content may not move Perplexity citations at all. You need separate content motions for each engine, tracked independently.
Should SMBs care about Claude Opus 4.8 specifically, or just AI visibility generally?
For most SMBs, the right frame is cross-surface AI visibility with Claude as one tracked surface, not the primary optimization target. Unless your specific audience uses Claude heavily (enterprise, developer, research contexts), focus on content completeness principles that transfer across models, and track citation share across ChatGPT, Perplexity, and Google AI Overviews simultaneously. The principles are consistent; the weighting differs by surface.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Track your Claude citation share across every major AI surface, see exactly where the mention-citation gap is costing you, and get the content intelligence to close it.