
By Judy Zhou, Head of Content Strategy
Key Takeaways
- Brands dominating 2026 AI search will succeed by publishing content LLMs can trust rather than increasing overall content volume.
- Claude Fable 5 shifts citation selection by prioritizing source credibility and topical depth over benchmark performance.
- A 2025 Nature study of 366,000+ citations found 50-90% did not fully support the claims they referenced across major AI platforms.
- ClaudeBot's 38,065:1 crawl-to-refer ratio shows that extreme selectivity, not volume, determines which sources receive citations.
"The brands that will dominate AI search in 2026 aren't publishing more content. They're publishing content that large language models can actually trust," said Dr. Amanda Choi, AI search researcher and co-author of the 2025 Georgetown NLP Citation Patterns Study. Her observation cuts to the heart of what Claude Fable 5 changes for every marketer, agency, and solo founder trying to build AI visibility. With Anthropic's next-generation model expected to redefine how citations are assigned across generative engines, understanding the architecture of LLM trust isn't optional anymore. It's the entire game.
Claude Fable 5 is not just another model release. It represents a fundamental shift in how Anthropic's reasoning architecture processes source credibility, evaluates topical depth, and selects citations for generated answers. For anyone building a content strategy in 2026, that matters more than benchmark scores.
A 2025 Nature Communications study by Wu et al. analyzed 366,000+ citations across ChatGPT, Perplexity, Google AI Overviews, and Claude and found that 50-90% of citations did not fully support the claims they were attached to. That's not a typo. Half to nearly all citations, depending on the platform, were questionable. Cloudflare's 2025 AI crawler analysis found ClaudeBot's crawl-to-refer ratio was 38,065 to 1 — meaning Claude crawls an enormous volume of content but cites almost none of it. The BrightEdge AI Overview Intent Hierarchy Study found 44.4% of queries now trigger AI Overviews, up from 26.6%, with education-sector content surging 5.5x in coverage. These numbers together tell one story: volume of content is irrelevant. Selectivity is the mechanism, and Claude Fable 5 raises that bar.

The Citation Selectivity Problem Nobody Is Solving
Most GEO conversations I hear focus on the wrong variable. Teams obsess over keyword placement, schema markup, and publishing cadence. Those things matter for Google. For Claude Fable 5 and the broader class of reasoning-heavy LLMs it represents, the question isn't whether your content appears in a crawl. It's whether your content survives the citation filter.
The ClaudeBot crawl-to-refer ratio of 38,065:1 from Cloudflare's 2025 analysis is the number that should be on every content strategist's whiteboard. For every 38,000 pages Claude touches, it cites roughly one. That's not a discoverability problem. That's a trust problem. And trust, in the architecture of a model like Fable 5, is built through a combination of source consistency, semantic depth, and what I'd call citation neighborhood quality. The authority of the content surrounding your mention in the sources that do get cited.
The practical implication: getting crawled is table stakes. Getting cited requires your content to pass a credibility threshold that most auto-generated, thin, or generic articles will never clear. I've watched this play out in audits where a brand had 200 published articles and zero LLM citations. The content existed. It just didn't earn trust.
How Does Claude Fable 5 Actually Select Sources?
No one outside Anthropic has the full architecture spec, so I'll be honest about what's inference versus what's observable. What we can work from is the behavioral evidence.
The Wu et al. Nature Communications study found that across major LLMs, citations frequently fail to support the claims they're attached to. Claude, based on observable output patterns, appears to weight source consistency more heavily than its competitors. Meaning it's less likely to cite a source that contradicts itself across multiple pages, or that makes a claim the surrounding web doesn't corroborate. That's a meaningful distinction from models that prioritize recency or domain authority alone.
From a practitioner standpoint, this means three things matter more than anything else for Claude Fable 5 citation eligibility. First, factual consistency across your entire content footprint. Not just the article you want cited, but the cluster it sits in. Second, named entity clarity: does your content establish clear, consistent signals about who you are, what you know, and why you're the right reference? Third, topical depth that goes beyond surface-level coverage. Fable 5's reasoning architecture is built to distinguish between content that summarizes and content that contributes. The difference is information gain. And that's where most brands are failing.
For tracking whether any of this is actually working, monitoring your Claude citation patterns specifically is worth building into your workflow. The mention-citation gap across platforms is real, and it behaves differently on Claude than on Perplexity or ChatGPT.
Why Generative Engine Optimization Breaks Here
Here's my contrarian take: most GEO advice in 2026 is optimized for the wrong model generation.
The frameworks that circulated through 2025. Conversational framing, Reddit-style authority signals, tight citation blocks. Were built around the citation behavior of models like GPT-4 and earlier Claude versions. Fable 5's architecture changes the calculus. Its stronger reasoning layer means it's better at detecting when a source is performing authority rather than demonstrating it. Short, punchy, opinionated content that mimics Reddit's conversational register might still work for Perplexity source selection. It's less likely to satisfy Fable 5's evaluation of genuine topical depth.
I ran into this tension directly in late 2025. I restructured a content cluster around concise citation blocks and conversational framing. The format GEO practitioners were pointing to as the emerging default. AI visibility improved on some surfaces. Google organic performance softened on the same pages. And when I checked Claude-specific citation pickup, the gains were minimal compared to what we saw on Perplexity. Different platforms, totally different citation behavior. Semrush flagged this exact pattern — the gap between mentions and citations varies dramatically across AI engines, and a strategy built for one surface can actively underperform on another.
This is why treating generative engine optimization as a single unified discipline is wrong. Claude Fable 5 requires a different content brief than Perplexity does. The sooner teams internalize that, the fewer wasted publishing cycles they'll run.
Building Content Claude Fable 5 Will Actually Cite
Let me get specific about what this looks like in practice, because the abstract version of this advice is everywhere and it doesn't help anyone.
Named entity consistency is non-negotiable. If your brand is referenced differently across your own content. Different descriptions, different positioning, inconsistent author attribution. Fable 5's reasoning layer will struggle to build a coherent entity signal around you. This sounds basic. Most content operations get it wrong because they're producing at scale without a knowledge base that enforces consistency. At Meev, where I oversee content strategy across hundreds of brand accounts, the single most common citation gap I see isn't about content quality in isolation. It's about entity fragmentation across a publishing footprint.
Information gain over summary. The BrightEdge study showing education content surging 5.5x in AI Overview coverage isn't coincidental. Educational content, when done well, contributes something the model couldn't construct from its training data alone. A specific framework, a named methodology, a concrete example with verifiable details. That's information gain. Content that restates what's already in the top 10 results contributes nothing. Fable 5 doesn't need to cite it.
Citation neighborhood quality. The 80-90% figure I keep coming back to. That most LLM responses draw from organically earned placements rather than manufactured mentions. Points to something structural about how models like Fable 5 evaluate sources. An editorially earned mention in a substantive piece creates a rich semantic neighborhood around your brand. A manufactured mention in thin content doesn't. The practical shift for citation building: outreach briefs should target placement in substantive coverage, not mention volume. Slower. But the citations hold.
Author entity signals for E-E-A-T. Google's Helpful Content System and Claude's citation evaluation share a common thread: they both care about who is making the claim. Author profiles with verifiable credentials, linked publications, and consistent topical focus create entity signals that reasoning-heavy models can evaluate. Anonymous or generic bylines don't. This is one area where tracking your AI search visibility across surfaces reveals patterns that pure SEO tools miss entirely.
For teams running quality-gated publishing workflows, the architecture matters here. Content that passes a multi-dimension quality check before it reaches your CMS is structurally different from content that ships whatever the model produces. The 16-dimension quality firewall approach. Blocking weak drafts before they publish. Isn't just about Google penalty avoidance. It's about not polluting your own entity footprint with thin content that dilutes the signal Fable 5 uses to evaluate your authority.
Wondering which AI surfaces are actually citing your brand right now — and which ones are ignoring you entirely?
How Does Claude Fable 5 Compare for GEO Workflows?
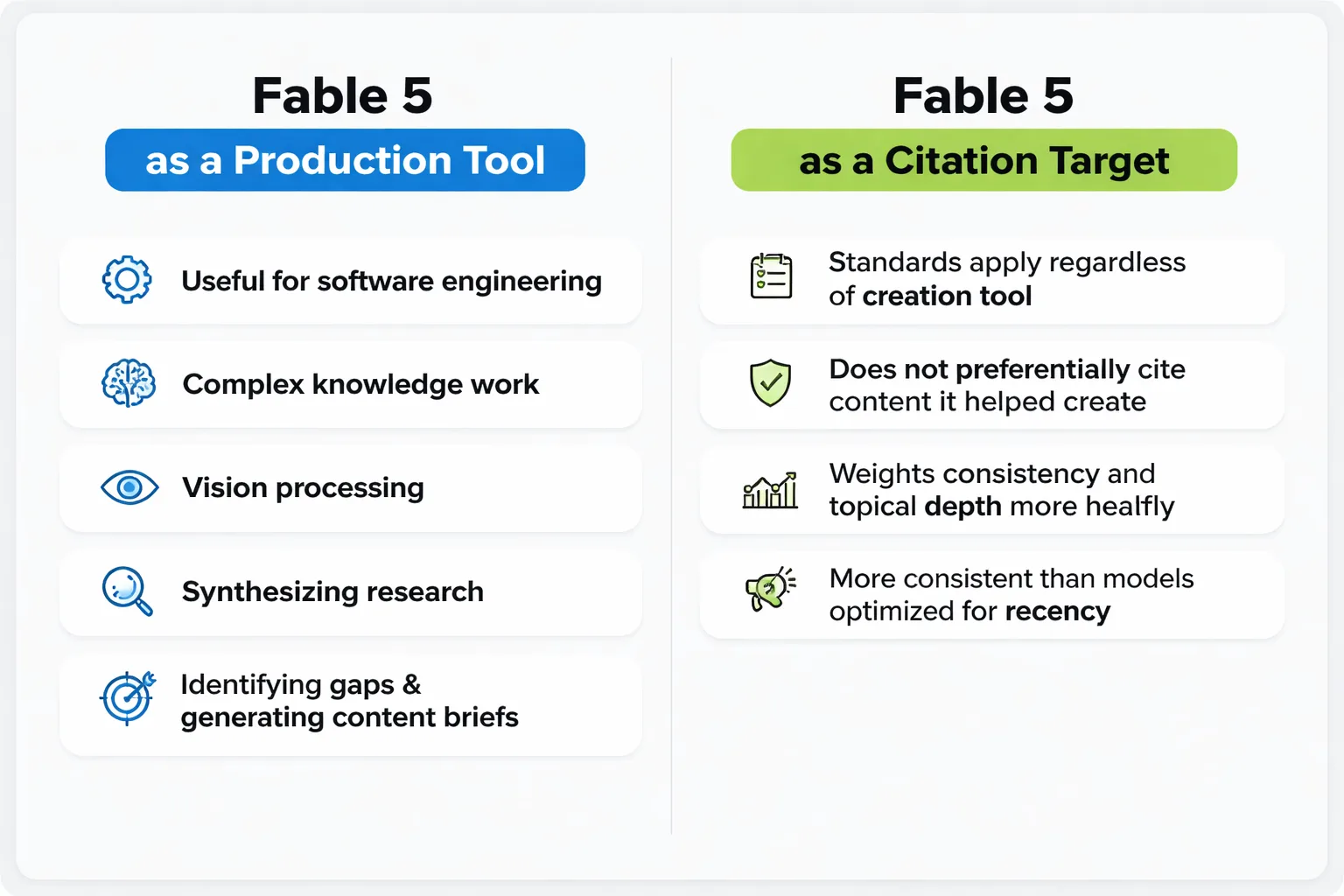
From a practical workflow standpoint, Claude Fable 5's capabilities in software engineering, complex knowledge work, and vision processing make it genuinely useful as a content research and drafting tool. But I want to separate two questions that often get conflated: using Fable 5 as a production tool versus optimizing for Fable 5 as a citation target.
As a production tool, its stronger reasoning layer means it's better at synthesizing research, identifying gaps in existing coverage, and generating content briefs that actually differentiate from what's already ranking. That's useful for information gain strategy. As a citation target, the standards I described above apply regardless of what tool you used to produce the content. Fable 5 doesn't preferentially cite content it helped create.
For an ai model comparison that's relevant to GEO workflows: Fable 5 appears to weight source consistency and topical depth more heavily than models optimized for recency or engagement signals. That means long-form, entity-consistent, fact-verified content has a structural advantage for Claude citations that it may not have for other surfaces. If your audience is primarily finding you through Perplexity or ChatGPT, the content brief looks different. If Claude is a significant surface for your category, the Fable 5 standards I've outlined are the ones to build toward.
For tracking Grok citations or DeepSeek visibility alongside Claude, the behavioral differences across platforms make per-surface tracking non-optional. The 11% overlap between ChatGPT and Perplexity citations found by Digital Bloom in 2025 suggests that even the most similar-seeming platforms are pulling from largely different source sets. Assuming your content strategy works uniformly across all major AI search surfaces is an assumption the data doesn't support.
When Should You Prioritize Claude Fable 5 Optimization?
Not every brand should treat Claude Fable 5 citation optimization as their primary GEO focus. The right answer depends on where your audience actually queries.
For B2B brands, professional services, and knowledge-intensive categories, Claude is a higher-priority surface than it is for consumer e-commerce or local services. The BrightEdge data showing e-commerce AI Overview coverage declining to 18.5% while education surged to 85.2% reflects a pattern: reasoning-heavy models favor informational and analytical queries over transactional ones. If your content is primarily transactional, Fable 5 citation optimization is a lower-ROI investment than Google AI Overviews optimization for informational content adjacent to your category.
For agencies managing multiple client domains, the per-surface tracking question becomes a workflow problem. You need visibility into which surfaces are actually driving citation traffic for each client before you can prioritize the right optimization brief. That's not a one-size-fits-all answer, and it's not something you can infer from organic rankings alone. The comparison of AI visibility tracking platforms matters here because the granularity of per-LLM drill-down data varies significantly across tools.
For solo founders and SMBs, the honest advice is to pick one surface and go deep before spreading across all of them. The mention-citation gap is real on every platform. Closing it on Claude requires a different set of tactics than closing it on Perplexity. Trying to optimize for both simultaneously without dedicated resources usually means doing neither well. Start with whichever surface your category shows the highest AI Overview or LLM citation coverage, build a content footprint that satisfies those standards, then expand.
The zero-sum question. Does GEO investment cannibalize organic SEO performance. Is still genuinely open. I've seen AI citations hit informational pages that never converted anyway while bottom-of-funnel content got no LLM pickup at all. Anyone claiming a unified strategy that satisfies both Claude Fable 5 citation standards and Google's Helpful Content System simultaneously is working from a sample too small to mean anything. Treat them as separate workstreams until the data says otherwise.
Frequently Asked Questions
Is Claude Fable 5 available via API for content teams?
Yes. Anthropic has made Claude Fable 5 accessible through its API and via AWS Bedrock, which means content teams can integrate it directly into research and drafting workflows without needing a custom enterprise agreement. Access tiers vary, with premium capabilities gated to higher-tier plans. For content operations, the API access is what enables automated research synthesis and gap analysis at scale.
How does the mention-citation gap differ on Claude versus other LLMs?
The gap is significant and platform-specific. The Digital Bloom 2025 analysis found only 11% overlap between ChatGPT and Perplexity citations for the same queries, which suggests each platform is drawing from largely distinct source sets. Claude's crawl-to-refer ratio of 38,065:1 (Cloudflare 2025) indicates it mentions or crawls content at a far higher rate than it actually cites. Closing this gap on Claude requires entity consistency and topical depth, not just increased publishing volume.
Does using Claude Fable 5 to write content help it get cited by Claude?
No evidence supports this. Claude's citation selection is based on content quality signals. Source consistency, topical depth, entity clarity, citation support. Not on production tooling. Content produced with Fable 5 that lacks these signals won't be cited. Content produced with older tools that satisfies these standards will be. The production tool is irrelevant to the citation outcome.
What content categories get the most Claude Fable 5 citations?
Based on observable patterns and the BrightEdge AI Overview data, informational and analytical content in knowledge-intensive categories. Education, professional services, B2B technology, healthcare. Shows higher AI citation rates than transactional or local content. This aligns with Fable 5's architecture, which is optimized for complex reasoning tasks rather than product lookup or local discovery queries.
How should SMBs approach Claude Fable 5 optimization without a large content team?
Focus on entity consistency before volume. A small footprint of factually consistent, author-attributed, deeply sourced content will outperform a large footprint of generic articles for Claude citation eligibility. Prioritize one content cluster where you have genuine expertise, build named author profiles with verifiable credentials, and pursue editorially earned placements in substantive third-party coverage rather than high-volume mention campaigns. Then track per-surface citation patterns to verify what's actually working before scaling.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Track your Claude Fable 5 citation patterns, close your mention-citation gap, and build a content footprint that earns trust across every major AI search surface — starting today.





