
By Judy Zhou, Head of Content Strategy
Key Takeaways
- AI search engines now answer queries without sending users anywhere, breaking the old "rank well, get found" contract.
- Wikipedia holds a 16.3% mention share in ChatGPT citations while Reuters sits at 4%, showing brands compete against institutional authority.
- Generative Engine Optimization requires dense, self-contained statements that AI engines can lift cleanly, unlike Google's narrative cohesion focus.
- Track the mention-citation gap—the distance between web references and actual AI citations—as the metric that determines visibility in 2026.
Your content is ranking. Your brand is still invisible.
That contradiction is the defining problem of AI Visibility 2026. The old contract between "rank well, get found" has broken down. Users are increasingly bypassing the blue-link SERP entirely, asking ChatGPT a question or typing a prompt into Perplexity instead of reaching for Google. If your brand isn't in the answer, the ranking is irrelevant.
AI search engines now answer queries without sending users anywhere. According to Ahrefs' analysis of 76 million AI Overviews and 950,000 ChatGPT and Perplexity prompts, citation patterns vary dramatically by platform. Wikipedia holds a 16.3% mention share in ChatGPT citations. Reuters sits at 4%. Your brand is competing against institutional authority, not just other blogs. Generative Engine Optimization 2026 is not a renamed version of SEO. It requires a fundamentally different content architecture, a different outreach strategy, and a different measurement framework. The mention-citation gap, the distance between being referenced on the web and being cited by an AI engine, is the metric that actually matters now. And most brands have no idea how large theirs is.
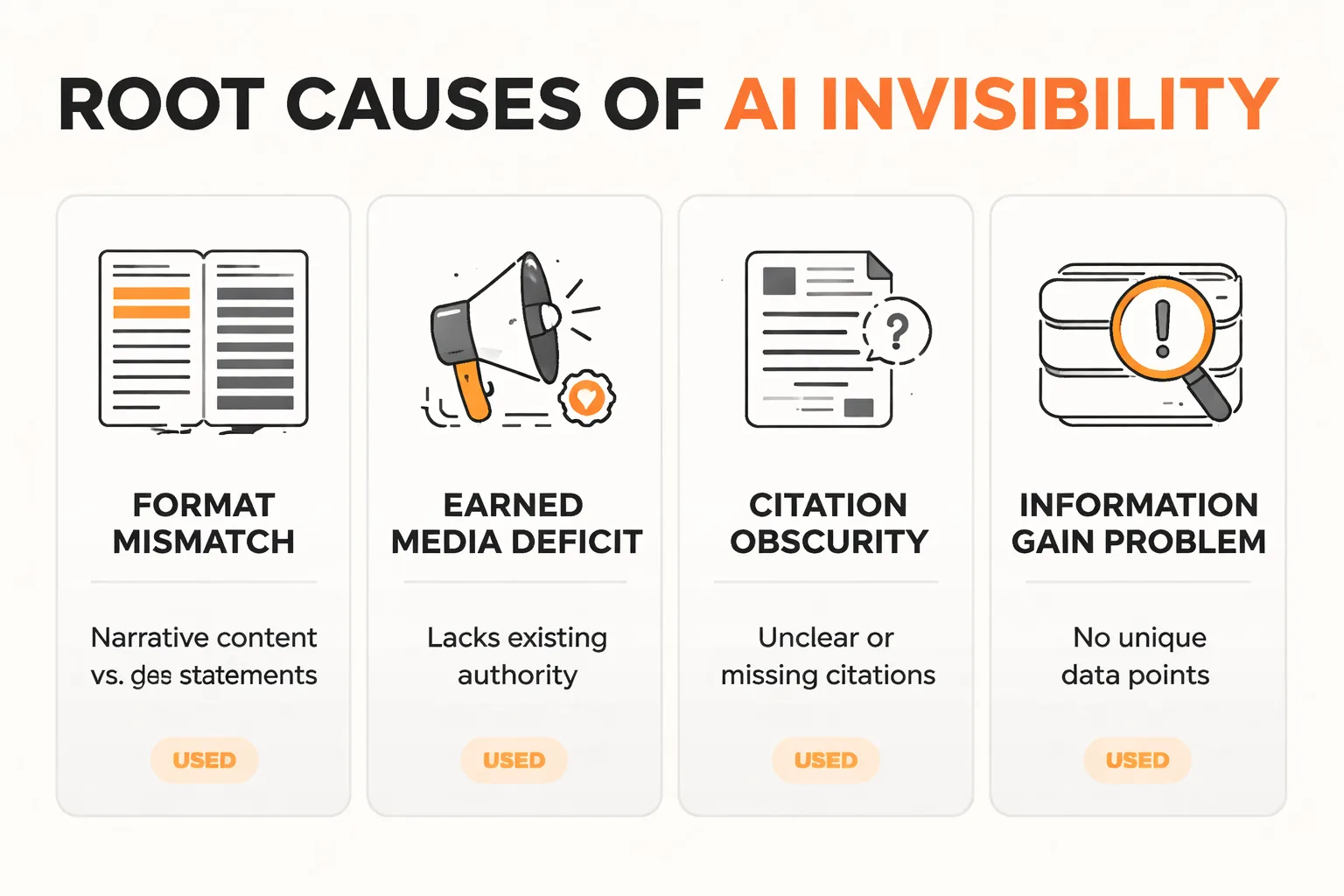
The Four Root Causes of AI Invisibility
Most teams diagnose AI invisibility wrong. They assume it's a content volume problem and publish more. It isn't volume. It's architecture.
The first cause is format mismatch. I tried building content specifically to rank in both Google and Perplexity simultaneously, and it didn't work the way I expected. The failure was structural: Google's Helpful Content System rewards narrative cohesion and demonstrated human experience. But when I traced what Perplexity was actually pulling, it consistently favored dense, self-contained statements that could be lifted cleanly without surrounding context. A well-argued 1,200-word section reads well to humans and to Google's quality signals. It's often invisible to an LLM retrieval layer looking for extractable entities. Those two requirements are in direct tension, and most content teams pick one without realizing they've abandoned the other.
The second cause is the earned media deficit. A comprehensive comparative analysis published on arXiv found that AI search systematically favors earned media (third-party, authoritative sources) over brand-owned content and social posts, which contrasts sharply with Google's more balanced source mix. If your content strategy is 90% owned channels, you're building for a system that's being deprecated.
The third cause is topical authority gaps. AI engines don't just ask "does this page cover the topic?" They ask "does this domain consistently cover this topic at depth?" A brand that publishes three strong articles on a subject and then pivots will not accumulate the citation weight that a brand publishing 30 articles on the same subject will. Topical authority for AI search is earned through volume plus coherence, not volume alone.
The fourth cause is the citation accuracy problem. A study published in Nature Communications analyzing over 366,000 LLM-generated citations found that 50 to 90% of those citations don't fully support the claims they're attached to. That means a tool showing you a chart of how often your brand gets "cited" could be surfacing references that are fabricated, misattributed, or contextually wrong. I've seen SEO blogs publish proprietary citation trend data with zero acknowledgment of this accuracy problem. The benchmarks looked meaningful. They weren't. Treat LLM citation counts as directional until the accuracy layer gets solved at the model level.
How Do Different AI Engines Actually Cite Sources?
This is where the ai model comparison question gets genuinely interesting, and where most practitioners are flying blind.
ChatGPT, Perplexity, Google AI Overviews, and Gemini don't share a citation logic. They have different retrieval architectures, different freshness windows, and different authority signals. The Ahrefs study of 75,000 brands across multiple AI search engines makes this concrete: Wikipedia's 16.3% share in ChatGPT citations reflects a model that was trained heavily on encyclopedic, consensus-validated content. That's not how Perplexity works. Perplexity runs live retrieval via its Sonar API, which means it's pulling from current web content rather than training data. A brand that has strong Wikipedia presence but thin recent press coverage will perform very differently across those two surfaces.
Google AI Overviews sits in a third category. It's powered by Gemini but filtered through Google's existing quality signals, which means your traditional domain authority and E-E-A-T signals still matter there in a way they don't for pure LLM citation. If you're optimizing for ChatGPT visibility versus Perplexity citation share, you're solving different problems. The mistake is treating them as one.
Here's the contrarian take most GEO guides won't give you: optimizing for AI citation share before you've closed your earned media gap is backwards. Citation share is a lagging indicator. The inputs are publisher coverage, third-party mentions, and topical authority accumulation. If those inputs are weak, no amount of structured data or FAQ schema will move the needle.
Why E-E-A-T Hits Different for AI Search
Google's E-E-A-T framework (Experience, Expertise, Authoritativeness, Trustworthiness) was designed for human quality raters. But AI engines have operationalized a version of it that works differently from how most SEOs apply it.
For traditional SEO, E-E-A-T is largely a document-level signal. Does this page demonstrate expertise? For AI citation, E-E-A-T functions more like an entity-level signal. Does this author exist as a verifiable entity with a consistent publication history? Does this brand appear in third-party contexts that corroborate its claimed expertise? An author bio on your own site is table stakes. What AI engines are actually pattern-matching on is whether that author's name appears in other credible publications, whether their claims get corroborated by independent sources, and whether the domain has a coherent topical footprint over time.
Concrete example: a solo founder in the cybersecurity space who has published three guest posts on recognized industry outlets, has a LinkedIn profile with verifiable employment history, and whose claims appear in at least two independent news summaries will outperform a brand with a polished "About" page and zero external corroboration. The author entity profile matters. The byline matters. The cross-publication trail matters. These aren't SEO tricks. They're the signals AI models use to distinguish real expertise from self-declared expertise.
Building author entity profiles into your content workflow is one of the highest-leverage moves available right now, and most auto-publishing tools don't support it. It's one reason I think quality-gated publishing infrastructure, the kind that blocks weak drafts before they reach your CMS, is a structural requirement for AI visibility in 2026, not a nice-to-have.
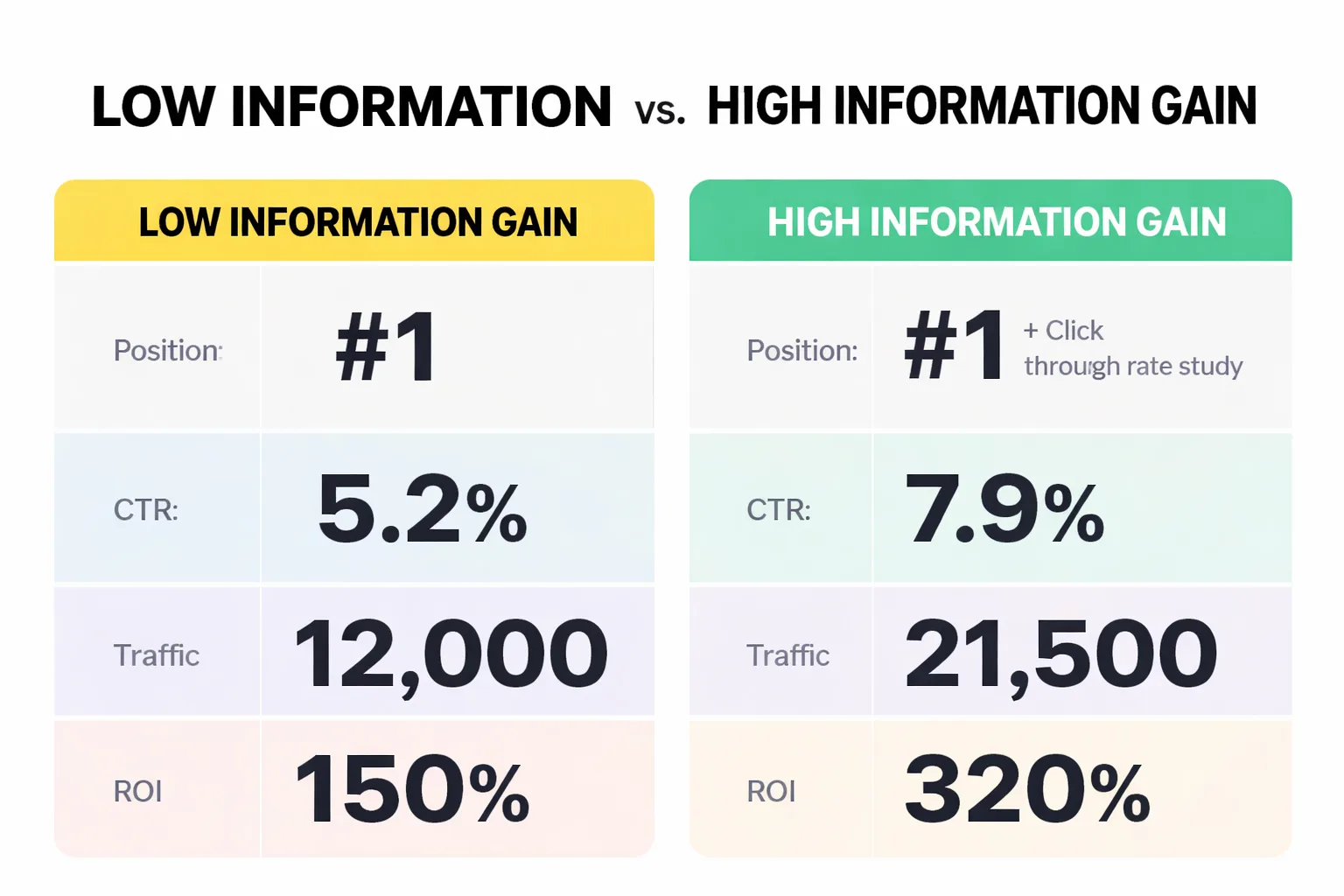
The Information Gain Problem in Generative Answers
Information gain strategy sounds abstract. It isn't.
AI engines are synthesizing answers from multiple sources. When they pull from your content, they're asking one implicit question: does this source add something the other sources don't? A page that restates consensus information has low information gain. A page that adds a specific data point, a named example, a concrete mechanism, or a documented exception has high information gain. The AI engine extracts it because it fills a gap in the composite answer.
This reframes the entire content quality conversation. The question isn't "is this article well-written?" It's "does this article contain at least one claim that no other cited source contains?" That could be original research, a proprietary framework, a specific client example, or a named data point from a primary source. It has to be something the synthesis layer can't get elsewhere.
What I've started doing is treating content as two separate layers within the same piece: narrative sections built for organic search and Google's quality signals, plus structured callouts and definition blocks built for AI retrievability. Dense, self-contained statements that can be lifted without surrounding context. It's more production overhead. It's also the only honest response to what the citation data is actually showing.
This is exactly the kind of quality dimension that a 16-dimension quality firewall needs to evaluate. It's not enough to check readability or keyword density. The question is whether the article contains extractable, attributable claims that add information gain to a generative answer.
How Does Citation Building Actually Work in 2026?
This is the question every agency and solo founder is asking, and the honest answer is: we're still in the early experimental phase.
I've been watching the brand-mention-for-LLM-citation space closely, and something is missing that I'd expect to see in any mature tactic: failure cases. I went looking for documented examples of aggressive brand mention outreach backfiring and found nothing. Not from any of the practitioner guides circulating right now. Every source frames brand mentions as a net positive, full stop. That absence should make any content strategist nervous. In SEO, we have years of post-mortems on link schemes that stopped working. Brand mention outreach for AI visibility has none of that yet. It reads like a hype cycle with no accountability infrastructure.
That said, here's what the structural logic does support. AI engines preferentially cite sources that appear in high-authority third-party contexts. Publisher pitching, getting your brand's claims and data cited in outlets that AI engines already trust, is the highest-confidence path to closing the mention-citation gap. The workflow has three stages.
First, identify which publishers AI engines are actually citing for your topic category. This isn't guesswork. Tools that track LLM Citation Tracking 2026 can surface a cited-source leaderboard showing which domains appear most frequently in AI answers for your target prompts. That's your outreach target list.
Second, find verified contacts at those publishers. Generic contact forms don't work at the volume needed. You need verified email addresses with deliverability filtering.
Third, draft pitches that are grounded in your actual knowledge base, not generic "we'd love to contribute" templates. The pitch needs to lead with the specific data point or claim you're offering, explain why it fills a gap in the publisher's existing coverage, and connect it to a topic the publisher is already covering. Personalization at this level requires knowing the publisher's recent content, which means the outreach workflow has to be integrated with content intelligence, not siloed from it.
For agencies managing multiple clients, this workflow needs to be systematized across domains. The Citation Path feature in platforms like Meev attempts to close this loop: find the publisher, resolve the verified contact, draft the KB-grounded pitch in one workflow. Most tools offer tracking-only or content-gen-only. The closed loop is what makes the difference at scale.
Wondering where your brand actually appears across ChatGPT, Perplexity, and Google AI Overviews right now?
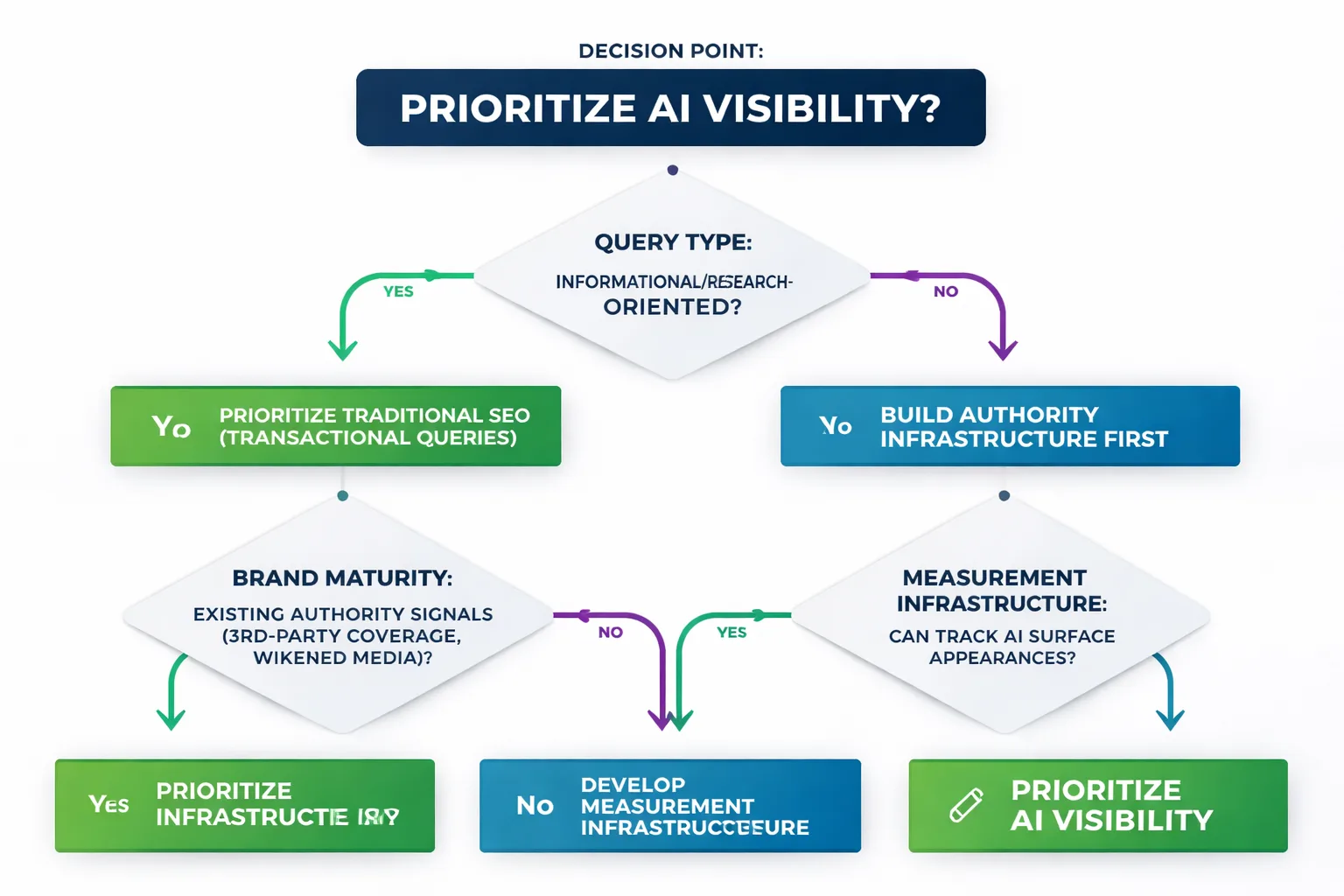
When Should You Prioritize AI Visibility Over Traditional SEO?
Not every brand should be redirecting budget from SEO to GEO right now. The decision depends on three variables.
First, query type. Informational and research-oriented queries are being captured by AI engines at a much higher rate than transactional queries. If your traffic is primarily transactional (product pages, pricing pages, comparison pages), traditional SEO still dominates the conversion path. If your traffic is primarily informational (how-to, what-is, comparison research), AI engines are already intercepting a significant share of it.
Second, brand maturity. AI engines cite brands that already have authority signals. A brand with zero third-party coverage, no Wikipedia presence, and no earned media trail is not ready for a citation-building campaign. The prerequisite work is building the authority infrastructure first.
Third, measurement infrastructure. If you can't track where your brand appears across AI surfaces, you can't allocate budget intelligently. An ai search visibility tool that tracks mention position (first, in a list, last), per-LLM drill-down, and share-of-voice against competitors is the baseline measurement requirement before any optimization spend makes sense.
For SMBs and solo founders specifically, I'd argue the highest-leverage move in 2026 is not a GEO campaign. It's closing the content quality gap first. Publish fewer articles with higher information gain. Build author entity signals. Get one or two high-authority placements. Then layer in citation tracking and outreach once the foundation is solid.
Agencies are in a different position. They're being asked by clients to demonstrate AI visibility ROI, which means they need the measurement infrastructure regardless of whether the optimization work is mature. Tracking Claude visibility alongside ChatGPT and Perplexity isn't optional for agency reporting in 2026. It's what clients are asking for.
Stop Treating Scaled Content as a Volume Problem
The most common mistake I see in auto-blog workflows is treating content quality as a binary: published or not published. The actual quality distribution matters enormously for AI visibility.
Here's why. AI engines don't just evaluate individual pages. They evaluate domain-level signals. A domain that publishes 150 articles per month, 40% of which are thin, low-information-gain content, is actively degrading its own citation probability. The weak articles don't just fail to help. They dilute the topical authority signals that the strong articles are building. This is the scaled content abuse problem that Google's Helpful Content System was designed to penalize, and AI engines have internalized a version of the same logic.
The solution is quality-gated publishing. Every article that goes out should clear a minimum threshold across multiple quality dimensions: information gain, E-E-A-T signals, extractable claim density, source citation quality, and duplicate content risk. A quality firewall that evaluates 16 dimensions and blocks articles below a threshold score is the structural answer to this problem. It's not a content strategy. It's a publishing infrastructure requirement.
For context on what that looks like in practice: Meev's quality firewall scores articles across 11 article-quality signals plus a 5-dimension Google Penalty Risk Matrix. Articles below 70 out of 100 are blocked from auto-publishing. That's not a soft recommendation. It's a hard gate. No competitor in the auto-blog space has an equivalent mechanism. The industry default is still to ship whatever the model produces, which is how you end up with a domain full of content that ranks for nothing and gets cited by no one.
If you're evaluating auto-blogging platforms, the comparison between Meev and Outranking is worth reading for exactly this quality-gate distinction. The difference isn't features. It's whether weak content can reach your CMS at all.
Frequently Asked Questions
How is Generative Engine Optimization different from traditional SEO?
SEO optimizes for ranking signals that determine page position in a blue-link SERP. GEO optimizes for citation probability in AI-generated answers. The inputs overlap (domain authority, content quality, backlinks) but the outputs diverge: SEO measures ranking position and organic traffic, while GEO measures mention share, citation position within an answer, and share-of-voice across AI platforms. The content architecture requirements also differ. SEO rewards narrative depth; AI retrieval rewards extractable, self-contained claim density.
What is the mention-citation gap and why does it matter?
The mention-citation gap is the distance between being referenced on the open web and being actively cited by an AI engine in a generated answer. A brand can have thousands of web mentions and near-zero AI citations if those mentions appear on low-authority domains that AI engines don't pull from. Closing the gap requires publisher pitching to earn placements on the specific domains AI engines are already citing for your topic category.
How do I know which AI engines are citing my competitors but not me?
You need a platform that tracks share-of-voice across AI surfaces and surfaces content opportunity gaps: prompts where competitors are cited but you aren't. Running this manually across ChatGPT, Perplexity, Google AI Overviews, Claude, and Gemini is not feasible at any meaningful scale. Automated tracking with per-LLM drill-down is the only practical approach.
Is brand mention outreach safe for AI visibility?
The honest answer is that we don't have failure case documentation yet. Every practitioner source frames brand mention outreach as net positive, but the absence of documented downside cases reflects a data gap, not a clean bill of health. The structural logic is sound: AI engines cite brands that appear in high-authority third-party contexts. But the edges of when outreach velocity becomes a negative signal are unknown. Treat it as an experimental tactic with a conservative initial approach.
How should solo founders approach AI visibility with limited resources?
Prioritize in this order: close the content quality gap first (fewer articles with higher information gain), build author entity signals (verifiable byline, cross-publication trail), earn one or two high-authority third-party placements, then add citation tracking. Trying to run a full GEO campaign before the authority infrastructure is in place is resource waste. The measurement tools are only useful once you have something worth measuring.
Does multi-CMS publishing affect AI citation patterns?
Publishing the same content to multiple CMS platforms (WordPress, Ghost, Shopify) doesn't directly increase citation probability. What matters is whether the published content reaches high-authority domains that AI engines already trust. Multi-CMS capability matters for operational efficiency and brand consistency, but it's not an AI visibility lever on its own. The citation signal comes from the domain authority of where you publish, not from the number of platforms you publish to.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Track your AI citation share across every major LLM surface, find the publishers citing your competitors, and close the mention-citation gap before your next content cycle.