
By Judy Zhou, Head of Content Strategy
Key Takeaways
- Brand citations dropped 55% after ChatGPT's May 2026 model shift, with Reddit emerging as the top-cited source by a 3x margin.
- Heavily cited LLM content shows 20.6% entity density versus 5-8% in standard text, requiring dense, structured answer capsules.
- 44.2% of all LLM citations come from the first 30% of a page, so front-load direct answers and entity mentions in content architecture.
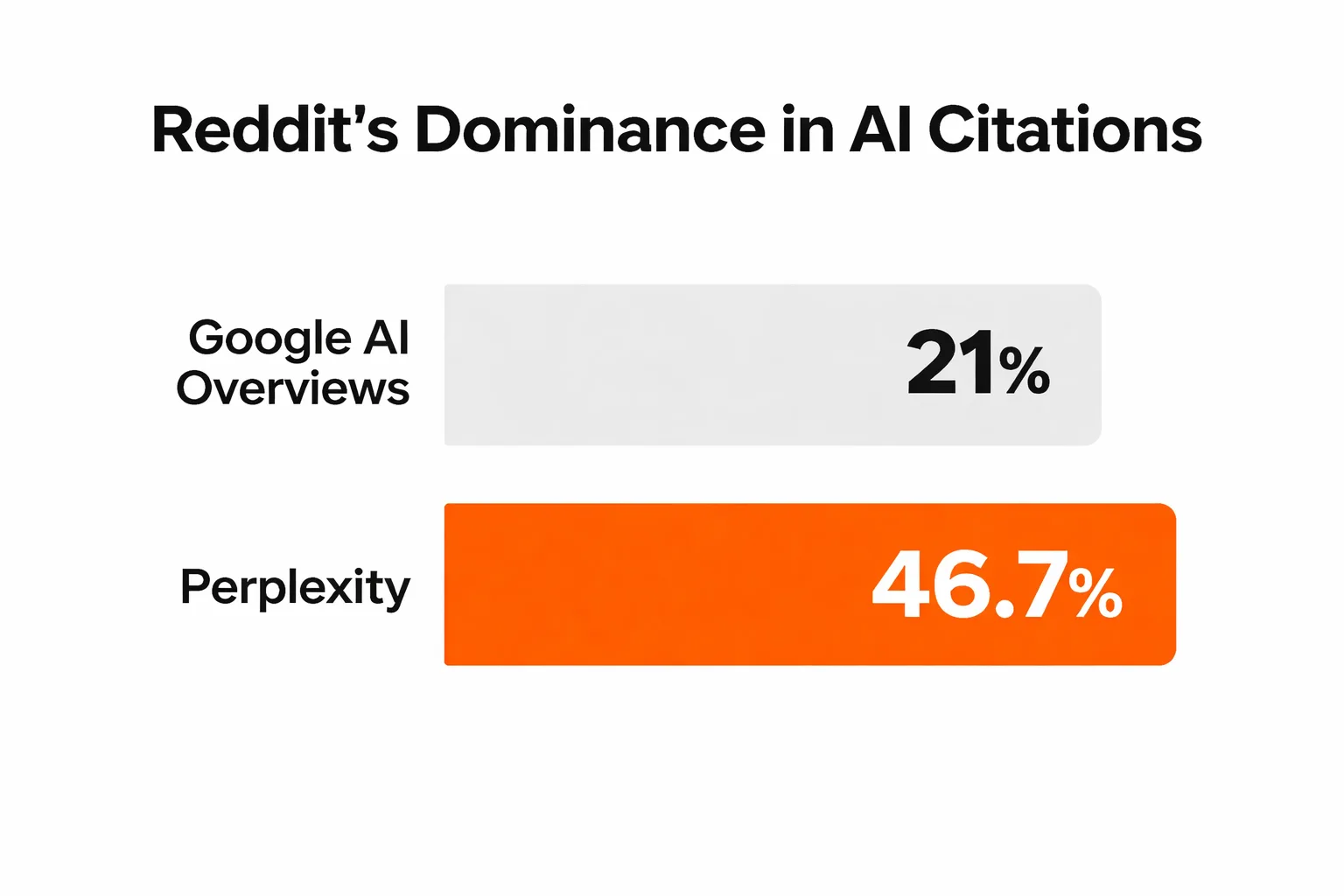
- Reddit drives 46.7% of Perplexity's top-10 citations and 21% of Google AI Overviews, making targeted off-site forum presence a core visibility lever.
ChatGPT is recommending your competitors right now, and you are not on the list.
If you want to get cited by ChatGPT, the path is not a single content tweak. It is a structured visibility system built across content architecture, off-site presence, and measurable citation tracking. According to a Writesonic study on GPT-5.5 Instant, brand citations dropped 55% when ChatGPT's default model shifted in May 2026, with Reddit becoming the top-cited source by a 3x margin. That is not a content quality story. That is a distribution story. A Profound Research analysis of 30 million citations found Reddit accounts for 46.7% of Perplexity's top 10 citations and 21% of Google AI Overviews' top 10 citations. Meanwhile, Redot Global reports that 44.2% of all LLM citations come from the first 30% of a page's content. The mechanics of chatgpt brand citation are real and measurable. Here is how to build a system around them.
The Citation Architecture Most Brands Skip
Before you pitch journalists or optimize schema, you need to understand how LLMs actually pull content. They do not crawl your site in real time. They work from training data and retrieval layers that favor content with high entity density, direct-answer structure, and broad off-site corroboration.
The entity density finding from Redot Global stopped me cold when I first read it. Heavily cited content carries an entity density of 20.6%, compared to 5-8% in standard text. That is not a marginal difference. It means the content LLMs prefer is genuinely packed with named concepts, tools, people, and organizations, not just keyword-optimized prose. If your blog posts read like they were written to rank for one phrase, they are probably not the content ChatGPT reaches for when answering a nuanced question.
The structural finding is equally important: 78.4% of citations containing questions come from headings. That is a direct argument for writing question-shaped H2s that mirror how your audience actually asks things in ChatGPT. Not "Content Strategy Tips" but "How Do You Build Topical Authority for AI Search?" The heading itself becomes the extractable answer frame.
For optimize for chatgpt seo to mean anything in practice, your content architecture has to start here. Named entities, question-shaped headings, and answer-dense openings are the foundation. Everything else is amplification.
How Does Information Gain Actually Move Citations?
Information gain is the single most actionable lever I have found for improving LLM citation likelihood, and it is also the most misunderstood. It does not mean "write more words." It means publishing something a language model cannot synthesize from existing sources.
Searchbloom's CEO describes Information Gain as "the single highest-leverage content move we've measured" and reports a 400% average lift in blended traditional and AI search visibility from optimizing for it. I cannot independently verify their methodology, and I want to be honest about that. But the directional logic holds: LLMs cite sources that contain facts, frameworks, or data points that do not appear elsewhere in their training distribution. Original research, primary surveys, proprietary benchmarks, and documented case studies all qualify. A post that synthesizes existing advice does not.
Google's February 2026 core update explicitly increased the weighting of information gain as a ranking signal, which means the traditional search and AI search incentives are now pointing in the same direction. That alignment is new and worth taking seriously.
The practical test I run before publishing anything now: can a reasonably capable AI model generate this content from its existing training data? If yes, the piece has low information gain and low citation potential. If no, because it contains original data, a named expert's specific opinion, or a documented outcome from a real experiment, it has something worth citing.
Why Topical Authority for AI Search Is Different
Topical authority in traditional SEO means covering a subject broadly enough that Google recognizes you as a domain expert. Topical authority for AI search means something more specific: your brand name is associated with a defined set of claims in the sources LLMs were trained on or retrieve from.
This is a subtle but important distinction. If your brand has published ten articles on content strategy but none of them have been cited by industry publications, mentioned on Reddit, or referenced in YouTube transcripts, your topical authority is essentially invisible to the retrieval layer. The LLM has no corroborating signal that you are the authority. It defaults to whoever has the most corroborated presence across the sources it trusts.
The pattern I keep seeing is that brands with strong LLM citation rates have two things in common: they publish genuinely differentiated content, and that content gets picked up and referenced by third-party sources. Neither alone is sufficient. A brilliant original study that nobody links to will not get cited. A heavily linked page with no original insight will get cited once and then fade as better sources emerge.
For agencies and SMBs trying to build AI search visibility from scratch, the practical implication is to pick two or three specific claims you want to own, build the best documented case for each, and then actively work to get those specific pages referenced in the places LLMs trust.
Want to know if ChatGPT is already mentioning your brand — and whether those mentions are turning into citations?
Build Off-Site Presence Where LLMs Actually Look
This is where most brand teams lose the plot. They spend 90% of their effort on their own site and 10% on distribution. The citation data says that ratio should be closer to inverted.
Reddit's dominance in AI citation data is not a fluke. The Profound Research findings covering 30 million citations show Reddit at 21% of Google AI Overviews' top 10 citations and 46.7% of Perplexity's top 10 citations. Those are not numbers you can ignore. Reddit threads contain direct-answer, conversational content with high entity density and genuine human experience signals, which is exactly what LLMs are trained to prefer for factual questions.
But here is the contrarian take I want to make clearly: Reddit presence is not a substitute for brand credibility. It is a distribution layer. Posting your brand's talking points in r/marketing threads is not the same as a genuine community member referencing your research in a discussion. LLMs are increasingly good at detecting promotional intent in text. The Reddit presence that generates citations is authentic participation, documented case studies shared in relevant threads, and honest answers to specific questions where your brand's experience is genuinely relevant.
Beyond Reddit, the off-site channels that matter for chatgpt brand citation are: YouTube (transcripts are indexed and cited), industry newsletters with high domain authority, podcast show notes, and editorial mentions in trade publications. Each of these creates a corroboration signal that tells the LLM's retrieval layer your brand is a credible source on a specific topic.
Publisher Pitching for AI Citations
This is the gap nobody in the GEO space is addressing directly. Most citation building advice stops at "create great content." The step that actually moves the needle is getting that content referenced by the publishers LLMs trust.
Publisher pitching for AI citations is not the same as traditional PR or link building, though it overlaps with both. The goal is not just a backlink. The goal is a named reference to your brand's specific claim or data point in a context where an LLM can extract and attribute it. That means the pitch has to include something genuinely citable: a proprietary statistic, a documented outcome, a named expert making a specific claim.
The outreach process I use has three components. First, identify the publications whose content appears most frequently in AI citations for your target queries. You can do this manually by running your key questions through ChatGPT and Perplexity and noting which domains appear in responses, or you can use a dedicated LLM citation tracking tool to systematize it. Second, map your brand's original claims to the specific topics those publications cover. Third, pitch a data point or case study, not a general story idea. Editors at high-authority publications get flooded with "we have a thought leader" pitches. They respond to "we have unpublished data on X that contradicts the conventional wisdom."
The mention-citation gap is real and worth measuring. Your brand may already be mentioned across dozens of sources that LLMs have access to, but those mentions may not be structured in a way that generates citations. A mention buried in paragraph eight of a 3,000-word article is less likely to be extracted than a mention in a direct-answer section near the top of the page. Part of the outreach work is ensuring that when publications do reference your brand, the reference is positioned where LLMs can find it.
E-E-A-T Signals That Actually Matter for LLM Citation
I used to think E-E-A-T guidance was vague enough that teams could get away with surface-level signals. A byline, a credentials line, a quote from a subject matter expert dropped in at the end. The June 2025 manual actions changed how seriously I take this. The documented pattern was not ambiguous: absence of demonstrable E-E-A-T combined with publishing velocity was the actual trigger for enforcement, not AI authorship itself.
For LLM citation specifically, E-E-A-T signals matter in a different way than they do for traditional search. Google's quality raters can read a page and assess expertise. LLMs infer expertise from the presence of specific, verifiable claims, named credentials, and cross-source corroboration. A page that says "our team of experts recommends" with no named author is a weaker citation candidate than a page that says "according to [Name], Head of X at [Company], who documented this in a 2026 study."
The practical E-E-A-T checklist for AI citation readiness looks like this: named author with verifiable credentials linked to a bio or profile, specific claims attributed to named sources, original data or documented experience that could not be generated from a generic prompt, and cross-references from at least two independent external sources. That last point is where most SMB content fails. It is not enough to be credible on your own site. LLMs need to see the corroboration.
I want to be direct about one thing here. The claim that E-E-A-T is "the foundation of how LLMs choose who to cite" is asserted frequently but not quantitatively proven. The Reddit citation data suggests platform presence may be as strong a predictor as E-E-A-T signals. My honest read is that both matter, and they work together: E-E-A-T makes your content worth citing, and platform presence makes it findable by the retrieval layer.
How to Track ChatGPT Citation Patterns Over Time
Most brands have no idea whether ChatGPT is citing them, mentioning them without attribution, or ignoring them entirely. That is a problem you can fix with a structured tracking approach.
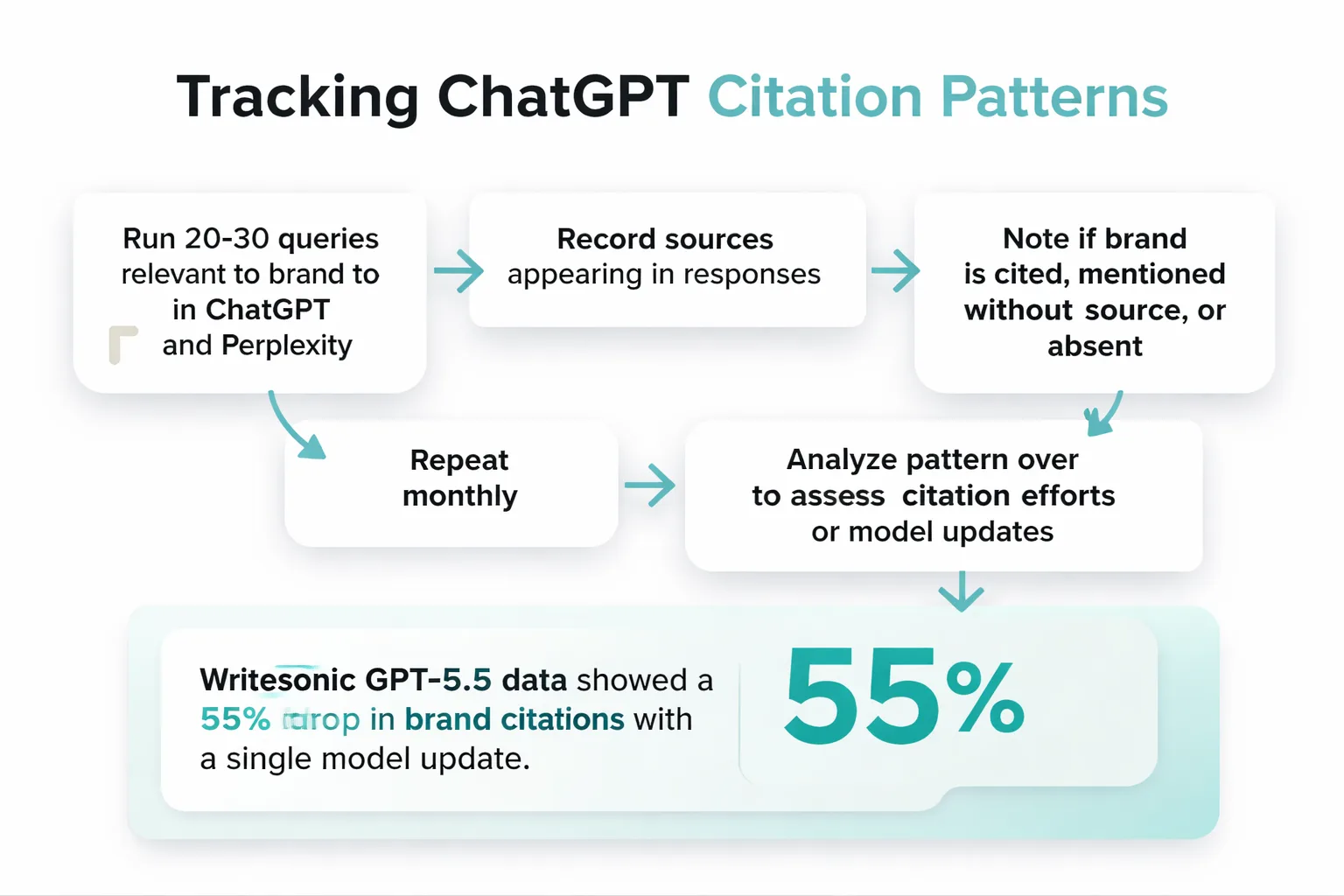
The basic manual method: run 20-30 queries in ChatGPT and Perplexity that are directly relevant to your brand's core topics. Record which sources appear in responses. Note whether your brand is cited, mentioned without a source link, or absent. Do this monthly. The pattern over time tells you whether your citation building efforts are working or whether a model update has changed the retrieval dynamics.
The more scalable approach is a dedicated platform. Meev's ChatGPT visibility tracking automates this across multiple LLMs simultaneously, which matters because citation patterns differ significantly between models. The Writesonic GPT-5.5 data showed a 55% drop in brand citations with a single model update. If you are only tracking one model, you will miss shifts happening in others. For a full picture, you also want to track Google AI Overviews, Perplexity, Claude, and Gemini separately, since each has distinct source selection patterns.
The metric I care most about is the mention-citation gap: the difference between how often your brand appears in AI responses and how often it appears with a source attribution. A high mention rate with low citation rate means LLMs know your brand exists but do not have a citable source to point to. That is a publisher pitching problem, not a content quality problem.
Where This Strategy Breaks Down
I want to be honest about the failure cases, because most how-to guides on AI citation skip them entirely.
First, model updates can wipe out months of citation gains overnight. The 55% drop in brand citations documented in the GPT-5.5 Instant transition is not an edge case. It is a preview of what happens every time a major model update changes the retrieval architecture. No citation building strategy is immune to this. You are building presence in a system you do not control.
Second, the "Mt. AI" content curve is real. Scaled AI content often spikes in traditional search for two to three months before collapsing as Google's quality threshold enforcement catches up. Teams that interpret that initial spike as validation of their citation strategy are setting themselves up for a painful correction. The content that survives long-term is the content that would have been worth publishing before AI generation existed.
Third, this entire strategy assumes your brand has something genuinely citable to offer. If your core content is synthesized from existing sources with no original data, no named expert, and no documented outcome, publisher pitching will not save you. Editors will not reference it, Reddit communities will not share it, and LLMs will not cite it. The strategy works when the content is real. It does not manufacture authority from thin air.
Frequently Asked Questions
Does having a Wikipedia page help you get cited by ChatGPT?
Wikipedia is one of the highest-weighted sources in most LLM training data, so a Wikipedia presence does correlate with higher citation rates. But creating a Wikipedia page for a brand that does not meet notability standards will not work and may be removed. The more reliable path is building the editorial mentions and third-party references that would justify a Wikipedia page, which also happen to be the same signals that drive LLM citations directly.
How long does it take to see results from a citation building strategy?
In my experience, meaningful movement in citation frequency takes three to six months from when you start active publisher pitching and off-site presence building. Content changes alone tend to show slower results because LLM retrieval layers update on their own schedules. The fastest results come from getting cited by a high-authority publication that LLMs already trust and retrieve from frequently.
Is Perplexity or ChatGPT more important to optimize for?
They serve different use cases and have different source selection patterns. Perplexity is more citation-heavy by design and retrieves more actively from the live web, making it more responsive to recent publisher mentions. ChatGPT's behavior varies more significantly by model version, as the GPT-5.5 citation drop illustrates. If you have limited resources, start with the platform your target audience uses most, then expand. Tracking both with a tool like Meev's Perplexity citation tracking alongside ChatGPT monitoring gives you the comparative data to prioritize intelligently.
Can small brands realistically compete with large publishers for AI citations?
Yes, but only on specific, narrow claims. A solo founder who publishes the only documented case study on a niche topic has a genuine citation advantage over a large publisher who covers that topic generically. The strategy for SMBs is not to compete broadly. It is to own two or three specific, verifiable claims so thoroughly that any LLM answering a question on that topic has no better source to cite.
Does schema markup help with LLM citations?
The honest answer is we do not have controlled evidence that schema markup directly increases LLM citation rates. What schema does is help search engines parse your content structure, which may improve the likelihood that structured content gets indexed and retrieved. I would not prioritize schema over content quality, off-site presence, or publisher pitching. Treat it as a hygiene factor, not a citation driver.
How do I know if my brand has a mention-citation gap?
Run 15-20 queries in ChatGPT and Perplexity that are relevant to your brand's core topics. Count how many responses mention your brand by name versus how many cite a specific page from your domain. If your brand is mentioned but rarely linked or attributed, you have a mention-citation gap. The fix is almost always more publisher pitching to get your specific claims documented in sources LLMs trust enough to cite by URL.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Track your brand's citation rate across ChatGPT, Perplexity, and Google AI Overviews in one place. See your mention-citation gap before your next competitor does.