
By Judy Zhou, Head of Content Strategy
Key Takeaways
- Content quality scoring tools grade for keyword coverage and readability — LLMs select sources based on extractable direct answers, inline attribution, and entity specificity, which are entirely different signals.
- BrightEdge found source overlap between AI engines ranges from just 16% to 59%, meaning there is no universal 'AI-optimized' format — Perplexity, ChatGPT, and Google AI Overviews each operate with distinct citation logic that requires platform-specific strategy.
- The single highest-leverage fix is the answer-first paragraph: every major section should open with a 40-60 word direct answer, giving LLMs an extractable passage and improving featured snippet eligibility simultaneously.
- The mention-citation gap — where AI engines use your data without citing your page — is closed through branded data publication and earned media coverage that ties specific claims to your domain by name, not through on-page optimization alone.
When Google introduced its Panda algorithm in February 2011, it drew a formal line between content quality and content manipulation — and the SEO industry responded by building an entire discipline around scoring pages before publication. Tools that grade semantic coverage, readability, and topical completeness became standard infrastructure. For over a decade, a high content quality score reliably correlated with ranking success. Then, between 2022 and 2024, generative AI rewrote the rules of information retrieval — and that correlation quietly collapsed, leaving a generation of well-optimized content invisible to the engines that now answer most queries.
Content quality scoring — the practice of grading pages against readability, keyword density, and topical completeness benchmarks — was built for a world where Google's crawler was the primary audience. A Semrush study of AI Overviews found that 99% of cited domains had strong authority signals, yet authority alone doesn't explain citation selection. BrightEdge research found that source overlap between any two AI engines ranges from just 16% to 59% — meaning a page that earns a citation in one engine has no guarantee of appearing in another. Perplexity draws 46.7% of its top citations from Reddit, a platform most quality-scoring tools would penalize for thin authority. Claude is 30% more likely to cite bullet-pointed pages than prose-heavy equivalents, regardless of their SEO score. These are not edge cases. They are the new citation logic.
The Quality Score Illusion — What Tools Measure vs. What LLMs Reward
Content scoring tools — whether you're using Clearscope, MarketMuse, or a built-in grader — evaluate pages against a specific set of signals: keyword presence, semantic coverage, readability grade, internal linking, and word count relative to competitors. These tools were reverse-engineered from Google's organic ranking algorithm, which itself was designed to approximate human editorial judgment at scale. The problem is that large language models don't rank pages. They retrieve passages.
The distinction matters enormously. When Google's algorithm evaluates a page, it's asking: does this document deserve to rank for this query? When a retrieval-augmented generation system like Google AI Overviews or Perplexity selects a source, it's asking something different: does this passage answer this specific question with enough precision that I can quote it directly? A page can score 94/100 on a content quality tool and still fail the second question entirely — because the tool measured topical breadth while the LLM needed a single extractable, attributable claim.
I've watched this play out repeatedly in my work overseeing content strategy for brands publishing at scale. A client in the B2B SaaS space had pages consistently grading A or A+ across their tool stack. Zero appearances in Perplexity citations for their target queries. When I pulled the actual content, the problem was immediately obvious: every page was structured as a comprehensive overview. Long introductions, smooth transitions, thorough coverage of adjacent topics. Exactly what the scoring tools reward. Exactly what LLMs can't extract from.
The core misalignment: content quality tools optimize for coverage; LLMs reward precision. A score of 90+ on a semantic grading tool tells you that your page mentions all the right concepts. It tells you nothing about whether any single paragraph in that page is citable as a standalone answer.
5 Reasons High-Scoring Content Gets Ignored by AI Search
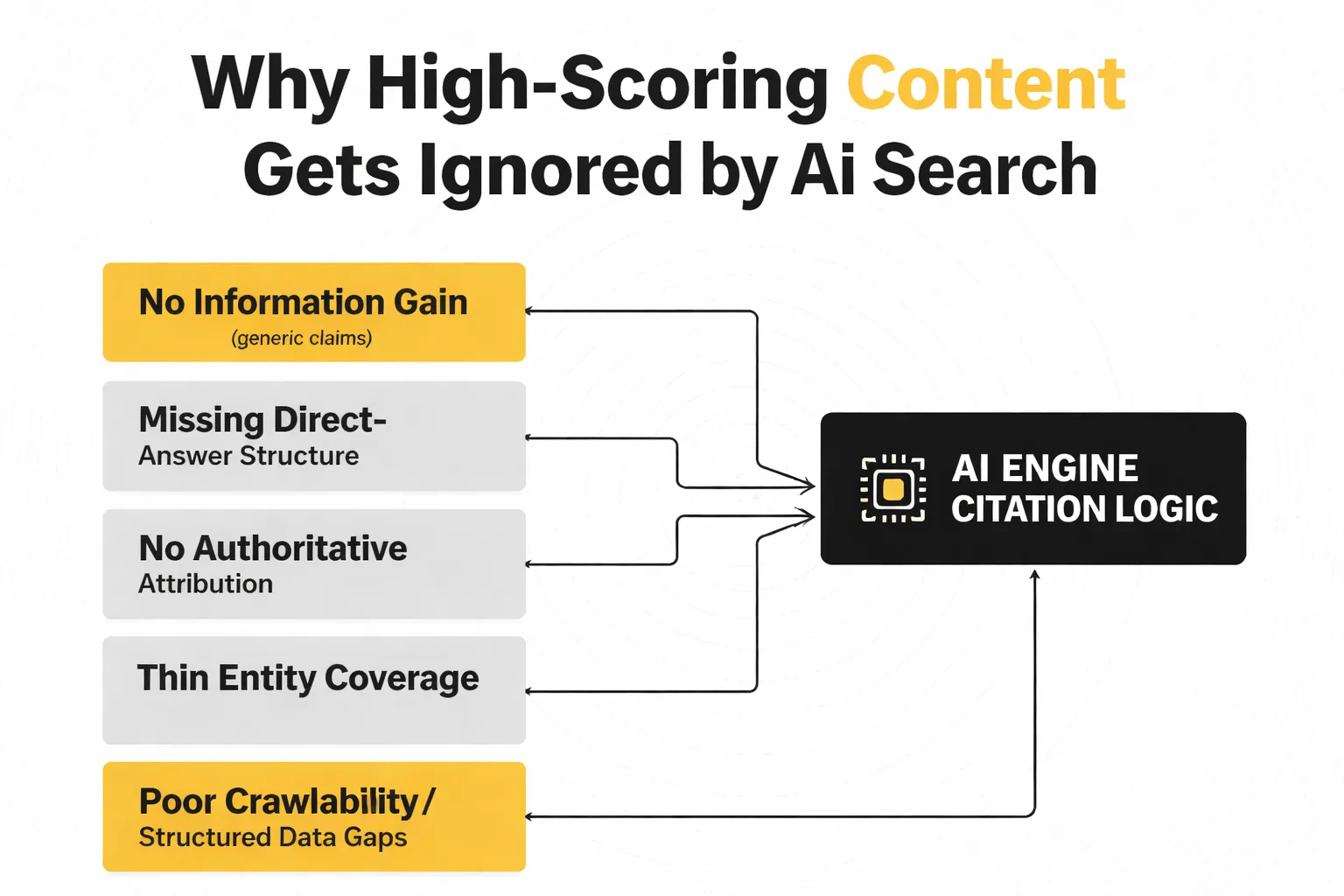
These aren't abstract failure modes. Each one maps to a specific behavior I've seen tank citation rates for content that looked excellent by traditional metrics.
1. No information gain. If your page says what every other page on the topic says, an LLM has no reason to cite you specifically. The model can synthesize the consensus view from a dozen sources — your page adds nothing. Information gain means your content contains a claim, data point, framework, or observation that isn't replicated elsewhere. This is the hardest problem to solve with a content scoring tool, because those tools compare you to existing content. They reward parity. LLMs reward differentiation.
2. Missing direct-answer structure. Seer Interactive's GEO research, which analyzed 231,347+ LLM responses across 7 AI platforms over 52 days, points to structural signals as a consistent citation driver. Claude's 30% citation preference for bullet-pointed content (per BrightEdge) reflects something real: LLMs extract passages, not pages. If your answer is buried in paragraph four of a 1,200-word section, it won't get pulled. The answer needs to be the first sentence of a clearly labeled section.
3. No authoritative attribution. LLMs are citation machines — they want to cite sources that themselves cite sources. A page that makes claims without naming studies, researchers, or data sources is asking an AI engine to take your word for it. They won't. Every factual claim in a page optimized for AI citation should have a named source attached to it.
4. Thin entity coverage. This is subtler than keyword coverage. Entity coverage means your page clearly establishes the who, what, when, and where of every claim — proper nouns, specific organizations, named individuals, dates. A page about email marketing strategy that never names a specific tool, study, or practitioner is entity-thin. LLMs use entity signals to assess specificity and credibility.
5. Poor crawlability and structured data gaps. Perplexity's citation pipeline runs five checkpoints — semantic relevance, freshness, structural quality, authority, and engagement — according to Ziptie's analysis of Perplexity's retrieval system. Structural quality means the page is parseable: clean HTML, logical heading hierarchy, no JavaScript rendering walls. A page that scores well in a content tool but renders key content via client-side JavaScript is invisible to retrieval systems that don't execute JS.
How to Diagnose Which Problem You Actually Have

Diagnosing your citation problem requires treating each AI engine as a separate publication with its own editorial logic — because that's effectively what they are.
Start with a manual query audit. Take your five most important target topics and run them through ChatGPT, Perplexity, and Google AI Overviews. Don't just note whether you appear — note who does appear, and in what format those cited pages are structured. This takes about 20 minutes and will tell you more about your citation problem than any tool audit.
For ChatGPT: pay attention to Wikipedia appearances (ChatGPT draws 7.8% of citations from Wikipedia per BrightEdge), consensus-oriented sources, and pages with clear authorship signals. If you're consistently absent while Wikipedia and major publications dominate, your problem is likely authority and entity coverage, not structure.
For Perplexity: the Reddit dominance (46.7% of top citations) is the tell. If Perplexity is citing Reddit threads over your well-researched pages, you have an information gain problem. The Reddit thread is getting cited because it contains a specific, unfiltered practitioner perspective that your polished page doesn't. The fix isn't to write worse — it's to write more specifically.
For Google AI Overviews: Seer Interactive's Search Console analysis covering 3,119 queries and 400,000+ monthly impressions found that AIO citation patterns overlap roughly 54% with traditional organic rankings. That means if you rank well organically, you have a fighting chance at AIO citations — but 46% of AIO sources come from outside the top organic results. Check your Search Console for queries where you rank in positions 1-5 but aren't appearing in the AIO. That gap is almost always a structure problem: the page ranks but doesn't contain an extractable direct answer.
The mention-citation gap is its own diagnostic category. Search for your brand name or key claims across AI responses. If AI engines mention your brand or reference your data without linking to you as a source, you have a citation attribution problem — the information is in the training or retrieval pool, but the source signal isn't strong enough to trigger a formal citation. This gap is more common than most content teams realize, and it requires different fixes than complete invisibility.
Once you've identified which engine is your priority gap, you can match the failure mode to the fix. Absent from Perplexity but ranking on Google? Information gain and freshness. Absent from ChatGPT but present on Perplexity? Authority and consensus signals. Present in AI Overviews but not cited? Extractable answer structure.
For teams managing content quality scoring at scale, platforms that track AI citation patterns across engines — rather than just SEO metrics — give you the feedback loop you actually need. The best AI visibility tools in 2026 increasingly include citation tracking alongside traditional rank monitoring, precisely because these are now different metrics.
Why Platform-Specific Citation Logic Breaks Generic Strategies
Here's the contrarian take most GEO advice gets wrong: there is no universal "AI-optimized" content format. The engines are not converging on a single citation standard. They are diverging.
BrightEdge's research puts the lowest source overlap between any two AI engines at 16%. That means for some query categories, two AI engines share fewer than one in five sources. Optimizing for "AI search" as a monolithic channel is like optimizing for "social media" without specifying the platform. The strategies are not interchangeable.
Perplexity's citation logic operates closer to a domain whitelist informed by real-time retrieval than a pure content quality signal. I spent the better part of Q1 running experiments for a client — longer-form authority pieces, tighter structured data, improved topical clustering. Almost none of it moved Perplexity citation rates. What actually worked was getting the client mentioned in two Tier-1 trade publications. Citations followed within weeks. Perplexity processed 780 million queries in May 2025, growing at 20% month-over-month. At that scale, a Perplexity citation slot is functionally equivalent in reach to a feature placement in a major trade publication — and the path to earning it runs through PR, not your CMS.
Google AI Overviews is a different story. The 54% overlap with organic rankings means traditional SEO authority still matters here — but the Guardian's January 2026 investigation into health-query AIOs revealed something uncomfortable: Google was citing demonstrably false sources, including Reddit threads and Wikipedia entries, at scale. Google subsequently pulled health-related AI Overviews. The implication for content teams is that Google's Helpful Content System and AIO source selection were running on separate tracks. Your authority signals may not be protecting you from competing against low-quality sources in the AIO pool.
ChatGPT's citation behavior skews toward consensus. The 7.8% Wikipedia citation rate reflects a preference for sources that aggregate established knowledge rather than sources that challenge it. If your content quality for AI search strategy involves staking out contrarian positions without heavy sourcing, ChatGPT is the hardest engine to win. The fix is layering your contrarian claim on top of cited consensus — not replacing the consensus.
For teams evaluating which tools actually track these platform-specific citation patterns, the Meev vs. Profound comparison breaks down how different AI visibility platforms handle multi-engine citation tracking — worth reviewing before committing to an LLM citation tracking stack.
Want to know which of your pages are citation-ready for AI engines — and which ones are being ignored despite strong SEO scores?
The Fix — Rewriting for Citation Likelihood Without Tanking Your SEO Score
The good news: improving AI citation signals and maintaining strong content quality scoring are not in conflict. The rewrite patterns that increase citation likelihood also tend to improve E-E-A-T signals, which Google's organic algorithm rewards. This is a both/and problem, not a trade-off.
The single highest-leverage rewrite pattern is what I call the answer-first paragraph. Every major section of a page should open with a 40-60 word paragraph that directly answers the implied question of that section's heading. Not a transition sentence. Not context-setting. The answer, stated plainly, in the first sentence. This serves two purposes: it gives LLMs an extractable passage at the top of every section, and it improves the page's featured snippet eligibility in traditional search — which feeds back into AIO citation probability given the 54% organic overlap.
The second pattern is claim attribution density. Every factual claim should have a named source within the same sentence or the sentence immediately following. Not a footnote. Not a "sources" section at the bottom. Inline attribution, consistently applied. This signals to retrieval systems that your page is a reliable intermediary — it doesn't just assert things, it connects claims to verifiable origins.
The third pattern is entity specificity replacement. Audit your pages for generic nouns and replace them with proper nouns wherever accurate. "A recent study" becomes "Seer Interactive's 52-day GEO Olympics study." "Many marketers" becomes "practitioners tracking Perplexity's ML reranking system." This isn't just good writing practice — it directly improves the entity coverage signals that LLMs use to assess credibility.
For structured data: add FAQ schema to any page where you've implemented the answer-first paragraph pattern. This creates a second extraction pathway for AI engines that process structured data separately from body content. It's not a silver bullet, but it's a low-effort amplifier for pages that are already well-structured.
On the question of AI content at scale and quality-gated publishing: the teams I've seen maintain citation rates while publishing at volume are the ones who apply these rewrite patterns as a pre-publication gate, not a post-publication retrofit. Building answer-first structure and claim attribution into the content brief stage is dramatically more efficient than auditing published pages. If you're evaluating workflow tools for this, the Meev vs. Surfer SEO comparison covers how different platforms handle quality gates in scaled publishing workflows — the differences in citation-readiness checks are significant.
One more pattern worth implementing: freshness signals in evergreen content. Perplexity's retrieval pipeline weights freshness as one of its five checkpoints. A page published in 2022 and never touched since is at a structural disadvantage against a page updated last month, even if the 2022 page is more authoritative. Adding a "last updated" timestamp, refreshing data points with current figures, and adding a "what changed" section to cornerstone pages can meaningfully improve retrieval probability without requiring a full rewrite.
For teams tracking whether these changes are actually producing citation results — not just better SEO scores — the Meev vs. Peec AI comparison covers how AI visibility tracking platforms differ in their citation monitoring capabilities. The gap between "your score improved" and "you got cited" is exactly the gap this article is about, and your measurement stack should be able to distinguish between them.
Frequently Asked Questions
Does a high E-E-A-T score guarantee AI citations? No — and this is one of the most expensive misconceptions in content strategy right now. E-E-A-T signals influence Google's organic ranking algorithm and may factor into AI Overviews source selection, but Perplexity and ChatGPT operate with different citation logic entirely. BrightEdge found only 16-59% source overlap between AI engines, which means strong E-E-A-T can earn you Google AIO citations while leaving you completely absent from Perplexity. Authority is necessary but not sufficient across all platforms.
How often should I audit my content for AI citation performance? Monthly at minimum for your highest-priority pages, quarterly for the broader content library. AI citation patterns shift faster than organic rankings because retrieval systems update continuously — Perplexity's index is effectively rolling. A page that wasn't being cited in January may be eligible in March after a content refresh, and a page that was cited in Q4 may drop out after a competitor publishes something more specific. Static audits miss these dynamics.
Is Reddit actually a viable content channel for AI citations? For Perplexity, yes — 46.7% of its top citations come from Reddit. The catch is that Reddit citations require genuine community participation, not brand-account promotion. The posts that surface in AI Overviews and Perplexity are substantive, specific, and written in a practitioner voice. Thin promotional posts get filtered out. If your brand can contribute genuinely useful, experience-based answers in relevant subreddits, the 2-6 week feedback loop into AI responses is real and worth the investment.
What's the difference between a mention and a citation in AI search? A mention means an AI engine references your brand, data, or claim in its response without formally attributing it to your page. A citation means your page is linked or named as the source. The mention-citation gap exists because LLMs often synthesize information from training data without surfacing the original source — the information is present but the attribution isn't. Closing this gap requires strengthening the connection between your specific claims and your domain identity, typically through consistent branded data publication and earned media coverage that ties claims to your organization by name.
Can structured data alone fix my AI citation problem? Structured data helps, but it's not a standalone fix. FAQ schema and HowTo schema create additional extraction pathways for AI engines that process structured markup, and they can amplify citation rates for pages that are already well-structured. But structured data on a page with generic information and no direct-answer paragraphs doesn't solve the underlying problem — it just makes the generic content easier to extract. Fix the content first, then add structured data as an amplifier.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Meev's quality-gated publishing workflow flags citation gaps before your content goes live — so you're not retrofitting pages after the fact. See how it works for your content operation.





