
By Judy Zhou, Founder
Key Takeaways
- AI search visibility is measured by four metrics — mention rate, citation frequency, prompt coverage, and share of model voice — not keyword rankings.
- A June 2026 citation analysis found 40.1% of LLM citations go to Reddit and 26.3% to Wikipedia, meaning brands without a forum or community presence face a structural citation disadvantage.
- The mention-citation gap — being named in an AI response but not attributed as a source — is caused by extractability and entity clarity failures that standard SEO never addresses.
- A weekly monitoring cadence (prompt run, gap flag, one action, delta record) is the minimum viable workflow to turn AI search tracking from a one-off audit into a compounding advantage.
In 2012, Google's introduction of the Knowledge Graph quietly signaled that the search engine no longer wanted to send users elsewhere. It wanted to answer questions itself. A decade later, that ambition exploded into AI Overviews, ChatGPT, and Perplexity, systems that synthesize answers from sources most brands have never deliberately optimized for. The entire discipline of ai search tracker tooling. Monitoring LLM citations, auditing mention-citation gaps, scoring topical authority for generative engines. Has emerged in response to that single, decade-long shift.
If you're still measuring success by keyword rankings alone, you're measuring the wrong thing. AI search tracker adoption is accelerating because the citation layer. Not the ranking layer. Now controls first-contact brand discovery for a growing share of buyers. An Ahrefs study found brand mentions carry a 0.664 correlation with AI Overview inclusion, the highest of any measured factor. Meanwhile, a June 2026 citation analysis found 40.1% of LLM citations point to Reddit and 26.3% to Wikipedia. Editable, gameable platforms, not authoritative brand sites. The gap between where AI engines cite and where your brand lives is the core problem this guide solves.
I lead content strategy at Meev, where we track AI visibility across hundreds of brand accounts, and the pattern I keep seeing is this: brands that build a systematic tracking workflow catch citation opportunities their competitors miss entirely. Here's the six-step methodology I use.
Step 1. Define 'Visibility' in AI Search Terms
Traditional rank tracking gives you a position number. AI search visibility is different in structure, not just degree. You're not asking "where do I rank for this keyword?" You're asking "when a model generates an answer about my category, does it mention me, cite me, or ignore me entirely?"
Four metrics actually matter here:
Mention rate — the percentage of relevant prompts where your brand name appears in the AI response, cited or not. This is your floor metric. If you're not being mentioned, you're invisible.
Citation frequency — of those mentions, how often does the model link to or explicitly attribute a claim to your domain? Perplexity cites sources inline. ChatGPT does so inconsistently. Google AI Overviews cite with visible source cards. Each surface behaves differently, which is why multi-engine tracking matters.
Prompt coverage — what share of your prompt inventory (more on building this in Step 2) triggers any response that includes your brand? A brand with 80% prompt coverage is structurally healthier than one with 20%, even if raw traffic looks identical today.
Share of model voice — across all prompts in a category, what percentage of AI-generated answers cite you versus a named competitor? This is the AI equivalent of share of voice in traditional media, and it's the metric that most clearly reveals competitive positioning.
Understanding what AEO (Answer Engine Optimization) actually means is useful context here. AEO is the practice of structuring content so AI engines can extract and attribute it cleanly. Visibility tracking is how you measure whether that work is paying off.
Step 2. Map the Prompts Your Buyers Actually Use
You can't track what you haven't defined. Before you configure any ai search tracker, you need a prompt inventory: a curated list of the questions, comparisons, and category-level queries your buyers type into ChatGPT, Perplexity, or Gemini.
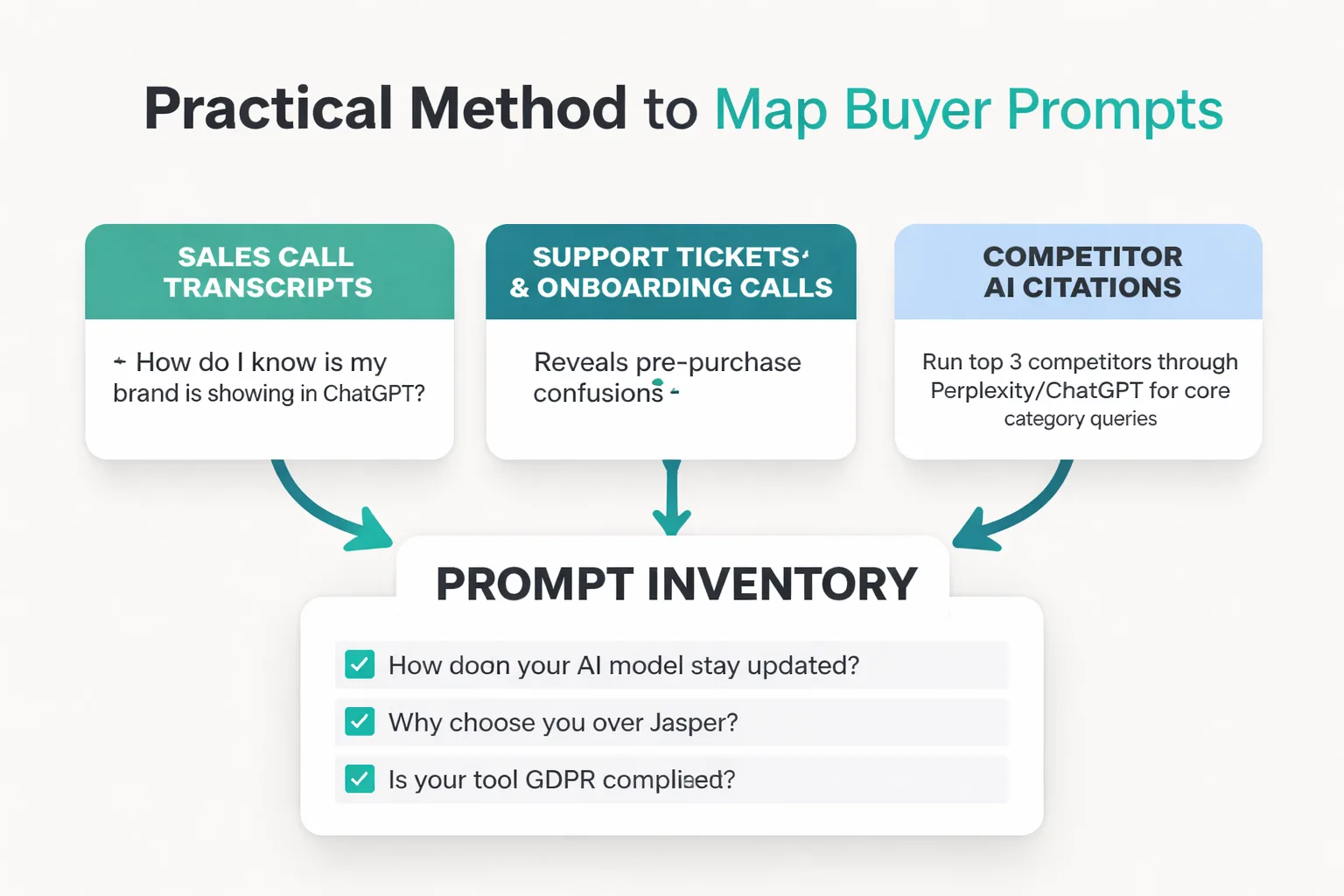
Here's the practical method I use. Pull from three sources:
Sales call transcripts. The exact language prospects use when describing their problem before they know your product exists is gold. "How do I know if my brand is showing up in ChatGPT?" is a real buyer prompt. "AI search tracker" is the keyword. The distinction matters for prompt design.
Support tickets and onboarding calls. Post-purchase questions reveal what buyers were confused about before they bought. Those confusions map directly to awareness-stage AI queries.
Competitor AI citations. Run your top three competitors through Perplexity and ChatGPT for your core category queries. Screenshot every response. The prompts that cite competitors but not you are your highest-priority tracking targets. This is the fastest way to find your mention-citation gap before you've even set up formal tracking.
Organize prompts by buying stage: awareness ("what is generative engine optimization?"), consideration ("best tools for tracking AI search visibility"), and decision ("[your brand] vs [competitor] for LLM citation tracking"). A working prompt inventory has 30 to 50 prompts at minimum. Fewer than that and you're sampling too thin to catch meaningful patterns.
The AEO vs SEO comparison is worth reading before you finalize your prompt list. It clarifies which query types AI engines handle differently from traditional search, which affects how you weight prompts in your inventory.
Step 3. Choose and Configure an AI Search Tracker
Not all ai search tracking tools are built the same, and the differences matter operationally. Here's what to evaluate before committing to any platform.
Multi-engine coverage. Your buyers aren't using one AI surface. They're spread across ChatGPT, Perplexity, Google AI Overviews, Gemini, Claude, Grok, and others. A tracker that only monitors one or two surfaces gives you a partial picture. At Meev, we track across every major AI search surface. ChatGPT, Claude, Gemini, Perplexity, Grok, Google AI Overviews, Google AI Mode, DeepSeek. Because citation patterns differ meaningfully by engine. What gets cited in Perplexity often doesn't get cited in ChatGPT, and vice versa.
Run frequency. AI models update their retrieval behavior. A tracker that runs monthly is too slow to catch the citation shifts that happen after a model update or a competitor's content push. Daily refresh on SERP-driven surfaces (Google AI Overviews) and rolling refresh on LLM-driven surfaces is the right architecture.
Brand mention rate reporting vs. raw citation counts. Raw counts are noisy. What you want is mention rate. Citations per prompt run. So you can compare performance across different prompt sets and time periods without volume distortion.
Competitor benchmarking. Knowing your mention rate is useful. Knowing your mention rate is 12% while your top competitor sits at 34% is actionable. Any tracker worth using should surface share-of-voice data across named competitors.
Mention position tracking. Where in the AI answer your brand appears matters. First mention in a response carries different weight than appearing fifth in a bulleted list. Look for trackers that record position within the response, not just presence.
For a detailed breakdown of what separates strong from weak platforms in this category, the Best AI Visibility Tools guide covers evaluation criteria in depth. If you want to start with a quick manual check before committing to a full platform, the Free Perplexity Brand Visibility Checker is a fast way to see your current baseline on one engine.
Step 4. Establish Your Baseline and Competitor Benchmarks
Your first batch of prompt runs is your baseline. Everything you measure going forward is relative to it, so getting this right matters.

Run your full prompt inventory (all 30 to 50 prompts) through each AI engine you're tracking. For each prompt, record:
1. Whether your brand was mentioned (yes/no) 2. Whether your brand was cited with a source attribution (yes/no) 3. Which competitors were mentioned in the same response 4. Your mention position (first, middle, last, in a list) 5. The actual response text, saved verbatim
Do this for at least three competitors. You're building a snapshot of the current citation landscape for your category, not just a vanity check on your own brand.
The competitor data is where baselines get interesting. I've seen brands with strong Google rankings and solid backlink profiles getting completely ignored by Perplexity while a thinner competitor with heavy Reddit and forum presence gets cited consistently. That June 2026 citation analysis explains part of why: 40.1% of LLM citations go to Reddit. If your competitor is active on Reddit and you're not, that's a structural citation disadvantage that no amount of on-page optimization will fix.
Record everything in a spreadsheet with a timestamp. This baseline becomes your control group. In four to six weeks, you'll run the same prompts again and measure delta. Without the baseline, you're guessing at whether anything changed.
One note on the Ahrefs finding: brand mentions correlate with AI Overview inclusion at 0.664, the highest correlation of any measured factor. But as Chris Long noted when analyzing that data, correlation isn't causation. A strong baseline tells you where you stand. It doesn't automatically tell you what to do next. That's what Step 5 is for.
Want to see where your brand stands across every major AI search surface right now?
Step 5. Diagnose Your Mention-Citation Gap
The mention-citation gap is the most important concept in AI search tracking, and most practitioners don't have a name for it yet.
Here's what it means: your brand might appear in an AI-generated response without being cited as a source. The model mentions your name in passing but doesn't attribute a claim to your content. That's a mention without a citation. The gap between your mention rate and your citation rate is your mention-citation gap, and it tells you something specific about your content's structural problems.
Why does this gap exist? I've watched pages with strong backlink profiles and solid keyword density get retrieved by Perplexity and then dropped before the final citation list. The culprit is almost always what technical breakdowns from the AI search community call the "extractability" and "entity clarity" gates. Perplexity's pipeline pulls five to ten candidate sources per query but only cites three or four. That cut happens at a stage standard SEO never touches. Keyword density gets you into the room. But if your content isn't structured so a model can cleanly lift a discrete, attributable answer from it, you get cut at the last step.
To diagnose the gap, look at the response text you saved in Step 4. For each prompt where you were mentioned but not cited, ask:
- Is there a competitor cited in the same response? If yes, pull that competitor's page and compare it to yours. What's structurally different? - Does your content contain a direct, extractable answer to the prompt's implied question? Not context-building prose, but a clean sentence a model could lift and attribute. - Is your brand entity clearly defined on the page? Models drop ambiguous attributions. If your content doesn't clearly state what your company does, in plain language, early in the page, entity clarity is your problem.
The AEO vs GEO framework is useful here for understanding which optimization lever addresses which gap. AEO fixes extractability. GEO (Generative Engine Optimization) addresses topical authority and entity signals at a broader content-graph level.
For brands tracking Claude specifically, Claude's citation behavior differs from Perplexity's in ways that affect how you diagnose gaps on that surface. Claude tends to favor longer-form, clearly structured content with explicit entity definitions. Perplexity favors brevity and direct answer structure. The same mention-citation gap can have different root causes depending on which engine you're diagnosing.
Step 6. Build a Weekly Monitoring Cadence
A one-off audit tells you where you stood on the day you ran it. A weekly cadence tells you whether your content and outreach work is actually moving the needle.

Here's the workflow structure I recommend:
Monday: Run your core prompt set. Use your tracker to run the 15 to 20 highest-priority prompts from your inventory (the full 50-prompt set is for quarterly deep reviews). Record mention rates and citation frequencies by engine.
Tuesday: Flag anomalies. Set alert thresholds: if your mention rate drops more than 10 percentage points week-over-week on any single engine, that's a flag. If a competitor's citation frequency spikes on a prompt cluster, that's a flag. Don't investigate everything. Triage.
Wednesday: One action. Based on Tuesday's flags, pick one content or outreach action. Update a page to improve extractability. Pitch a publisher that AI engines cite for your topic. Add an FAQ block to a high-priority page that's getting mentions but no citations. One action, documented.
Friday: Record delta. Update your tracking spreadsheet with this week's numbers. Note what action you took and when. In four weeks, you'll have enough data to see whether the action moved the needle.
The reporting template matters as much as the data. I use a simple format: prompt cluster, mention rate this week, mention rate last week, delta, engine breakdown, top competitor cited, action taken. That's it. Anything more complex and the cadence breaks down because it takes too long to fill in.
For teams managing multiple domains, Meev's weekly digest email surfaces AI visibility changes, new competitor citation spikes, and content opportunities automatically. Which compresses the Monday-Tuesday steps significantly. The LLMs.txt Validator is also worth running monthly to confirm your site's AI crawlability signals are current, since that affects whether trackers can accurately attribute responses to your domain.
Where This Process Actually Breaks Down
I want to be honest about the failure modes here, because most how-to guides skip them.
The prompt inventory goes stale. Buyer language shifts. New competitors enter. AI models start handling a query type differently. A prompt inventory built in January 2026 may be measuring the wrong questions by June. Build a quarterly review into your cadence or your tracking will drift out of alignment with actual buyer behavior.
Citation patterns are genuinely noisy. The Tow Center's research found over 60% of AI-generated citations are misattributed or fabricated. I've seen well-structured, authoritative content get ignored by Perplexity while a thinner competitor piece gets cited, with no discernible pattern. This means week-over-week deltas below 5 percentage points are often noise, not signal. Don't over-optimize for single-week fluctuations.
Tracking doesn't fix the underlying content problem. If your content isn't structured for extractability. Clean direct answers, explicit entity definitions, minimal context-building prose around key claims. No monitoring cadence will change your citation rate. Tracking tells you the score. It doesn't throw the passes. Pair this workflow with actual content audits and publisher outreach for AI citations or the data you collect will sit unused.
Frequently Asked Questions
How many prompts should I track per week to get statistically meaningful data?
For a small to mid-sized brand, 15 to 20 core prompts run weekly is enough to spot trends. The key is consistency. Running the same prompts each week. Rather than volume. A 50-prompt inventory run quarterly gives you depth. A 20-prompt set run weekly gives you momentum tracking. You need both, but start with the weekly set.
Does Google AI Overviews tracking work differently from ChatGPT or Perplexity tracking?
Yes, structurally. Google AI Overviews is a SERP-driven surface, so it refreshes on a daily cadence tied to index updates. ChatGPT and Perplexity are LLM-driven surfaces with rolling refresh tied to model updates and retrieval pipeline changes. This means your mention rate on AI Overviews can shift faster in response to on-page content changes, while LLM surfaces may take weeks to reflect the same update.
What's the difference between a brand mention and a citation in AI responses?
A mention is when the AI response includes your brand name in text without attributing a specific claim or source to you. A citation is when the model explicitly attributes a claim to your domain, usually with a linked source card (Perplexity) or a bracketed reference. Citations carry more weight for brand authority and are harder to earn. Tracking both separately is what reveals your mention-citation gap.
Can a small business or solo founder run this process without a paid tool?
Yes, manually, for a small prompt set. Run 10 to 15 prompts by hand through Perplexity and ChatGPT, record responses in a spreadsheet, and repeat weekly. It's time-intensive but viable for 30 to 60 minutes per week. The limitation is that manual runs can't cover multiple engines at scale or catch real-time citation shifts. A dedicated ai search tracker becomes worth the cost when your prompt inventory exceeds 20 prompts or you're managing more than one brand.
How long before I see movement in my citation rates after making content changes?
On Google AI Overviews, you might see changes in two to four weeks following a significant page update, since it's index-driven. On LLM surfaces like ChatGPT and Claude, the lag can be six to twelve weeks, depending on when those models next update their retrieval indices. Perplexity tends to be faster because it retrieves live web results. Set your expectation at eight weeks before drawing conclusions from any single content change.
About the Author
Judy Zhou, Founder
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Stop guessing at your AI search visibility. Meev tracks your brand across every major AI surface, surfaces your mention-citation gap, and helps you close it — starting today.





