
By Judy Zhou, Founder
Key Takeaways
- Google's March 2024 core update folded the Helpful Content System into its core algorithm, explicitly targeting unoriginal, low-quality content.
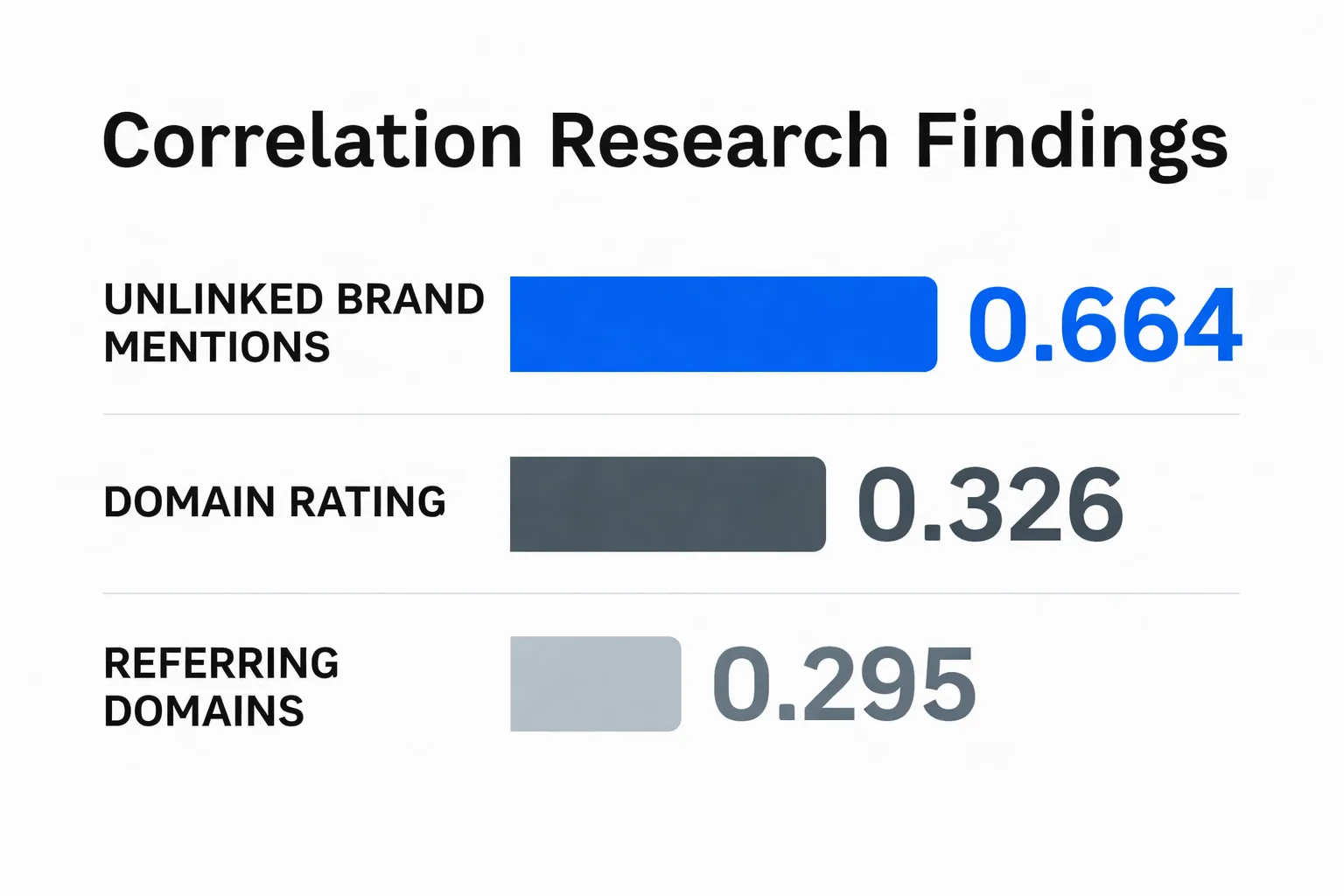
- Brand mentions correlate with AI Overview inclusion at 0.664, versus 0.326 for Domain Rating.
- Add a quality-scoring pipeline before publish to separate modern auto blogging from scaled content abuse.
- Combine LLM generation, CMS integrations, and workflow triggers to automate topic selection through final publish with zero manual drafting.
In 2004, a developer named Kevin Gibbs quietly registered a patent describing software that could harvest RSS feeds and publish them as original-looking blog posts with no human involvement. Most people called it spam. A small group called it the future. Two decades later, the underlying instinct. Automate content production at scale. Has evolved into one of the most sophisticated disciplines in digital marketing, now sitting at the intersection of generative engine optimization, LLM citation tracking, and the race for outranking competitors inside AI-generated answer surfaces.
Auto blogging in 2026 is not what it was in 2004. Modern auto blogging combines large language model generation, CMS integrations, and quality-scoring pipelines to publish at scale without sacrificing the editorial signals Google and AI engines now use to select cited sources. The difference between auto blogging done right and scaled content abuse comes down to one variable: whether a quality gate exists before publish. Google's March 2024 core update explicitly targeted "unoriginal, low-quality content," folding the Helpful Content System into its core algorithm — meaning sites that publish without a quality gate are now playing against a stricter ruleset than existed even two years ago. Brand mentions (unlinked textual references) correlate with AI Overview inclusion at 0.664, versus 0.326 for Domain Rating — which means the content you auto-publish shapes your AI citation footprint more than your link graph does. That's the strategic case for getting auto blogging right, not just fast.
Auto Blogging Defined. What It Actually Means in 2026
Auto blogging is the automated generation and publishing of blog content using AI language models, CMS integrations, and workflow triggers. With minimal or zero manual writing per article. The key word is automated: from topic selection through final publish, the system executes without a human drafting sentences.
That's distinct from AI-assisted writing, where a human uses ChatGPT or Claude to draft sections, then edits, restructures, and publishes manually. AI-assisted writing is still a human-driven process. Auto blogging is a pipeline-driven process. The human's job shifts from writing to system design and quality governance.
In practice, a modern auto-blog engine workflow has five components: a topic sourcing layer that pulls from keyword tools, RSS feeds, Reddit, or Search Console data; a generation layer that produces a draft using an LLM; a scoring layer that evaluates the draft against quality criteria; an editorial gate that blocks or approves the draft for publish; and a CMS publishing layer that pushes approved content to WordPress, Ghost, Shopify, or wherever the site lives. Each layer can fail independently. That's what makes auto blogging hard to do well and easy to do badly.
The version that earns rankings and AI citations looks nothing like the version that earns penalties.
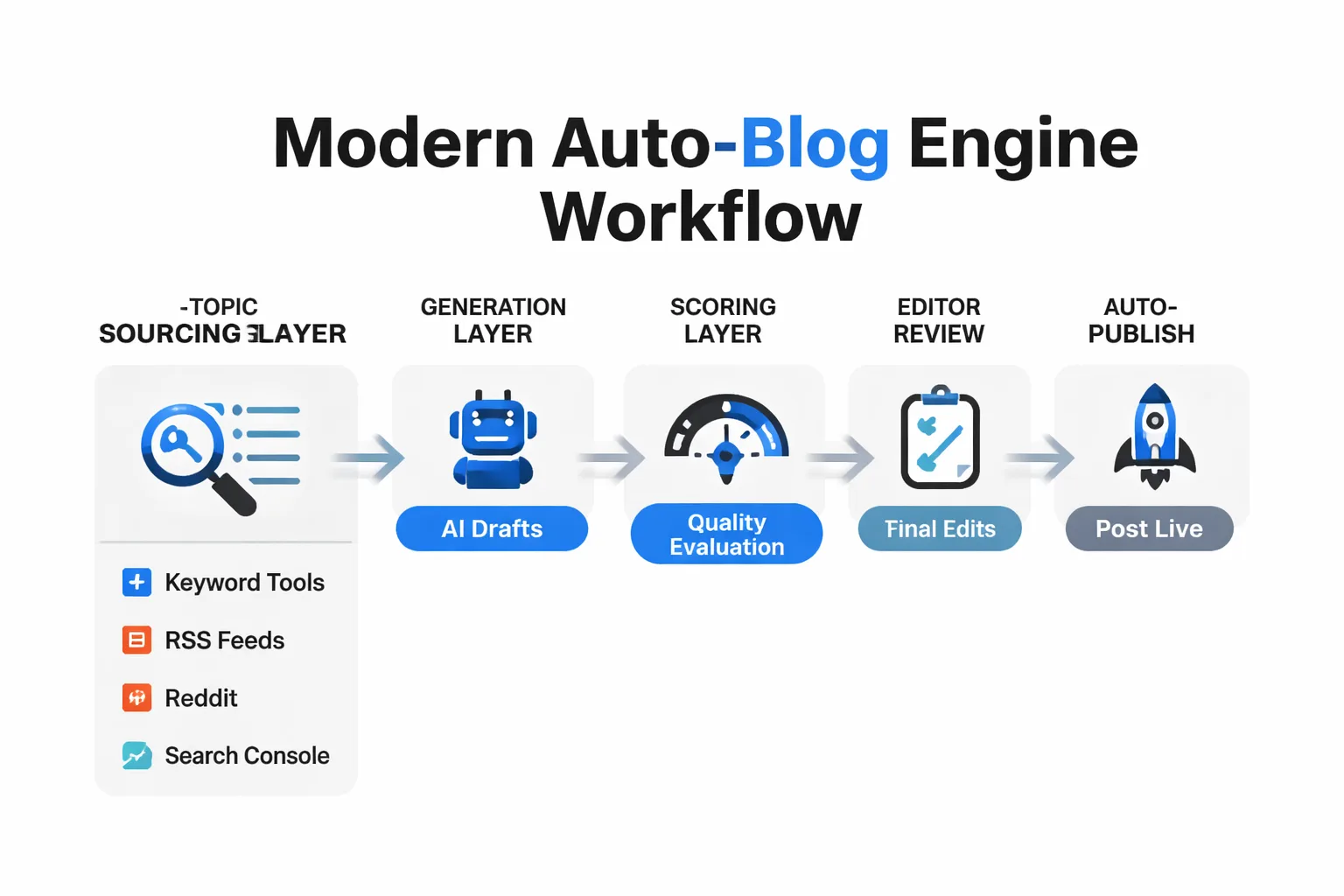
How Auto Blogging Works. The Core Workflow
Start with topic sourcing. The best auto-blog systems don't generate articles about whatever topic feels relevant. They pull from structured signals: Google Trends, Search Console queries with impressions but no clicks, Reddit threads gaining velocity, and competitor keyword gaps. This is where outranking begins. If your topic selection is reactive or random, the articles you generate will cluster around the same territory everyone else is covering. Systematic sourcing finds the gaps.
Generation is where most teams over-invest attention and under-invest architecture. The LLM produces a draft, but the draft's quality is determined upstream by the prompt design, the knowledge base the model retrieves from, and the archetype-specific instructions it receives. A listicle article needs different structure and citation density than an explainer. Treating every topic the same produces uniformly mediocre output. Recognizable to both Google's quality classifiers and AI citation systems.
Quality scoring is the step most auto-blog setups skip entirely, and it's the step that separates legitimate publishing from scaled content abuse. A serious quality gate evaluates multiple dimensions: factual accuracy, source citation, topical depth, E-E-A-T signals, duplicate content risk, and cannibalization against existing articles. According to Google's spam policies, sites that produce content at scale without demonstrating originality and effort risk ranking lower or disappearing from results entirely. A quality gate is not a nice-to-have. It's the mechanism that keeps your auto-blog engine on the right side of that line.
The editorial gate is a binary decision point: publish or block. In a well-designed system, articles scoring below a threshold are held for human review or regenerated, not published. This is where human judgment re-enters the pipeline. Not at the writing stage, but at the approval stage. That's a meaningful distinction. The human isn't writing; the human is governing.
CMS publishing handles formatting, schema markup, internal linking, image generation, and indexing. IndexNow pings and Search Console sitemap submissions at publish time accelerate crawl. Most basic auto-blog setups miss this entirely, publishing content that sits unindexed for weeks.
The final layer. AI visibility monitoring. Closes the loop. Which published articles are getting cited by Perplexity, ChatGPT, or Google AI Overviews? Which topics are competitors getting cited for that you're not? Without this feedback, the pipeline runs blind. You can check your AI visibility tool to see where your brand surfaces across major AI search engines, which turns the auto-blog system from a content factory into a citation-building machine.
Auto Blogging vs. Scaled Content Abuse. Where the Line Is
This is the question that actually matters, and I want to be direct about it: the line is real, it's meaningful, and most teams drawing it are drawing it in the wrong place.
Google's March 2024 core update explicitly targeted "spammy, low-quality content" and "unoriginal" material. The Helpful Content System, now baked into Google's core algorithm, classifies sites along two axes: SEO-first content (negative factor) versus people-first content (positive factor). Cyrus Shepard has noted publicly that "Google never clearly defines" what constitutes SEO-first content. Which creates real ambiguity. But the practical criteria are cleaner than the policy language suggests.
Scaled content abuse is characterized by three things: no information gain over existing results, no E-E-A-T signals (no named author, no demonstrated expertise, no verifiable experience), and no human review checkpoint anywhere in the pipeline. Agencies that ran auto-blog engines at high volume without editorial gates documented SEO ranking failures after Google's updated Quality Rater Guidelines explicitly flagged AI-generated scaled content as problematic when produced with minimal originality. The volume wasn't the problem. The absence of quality governance was.
Legitimate auto blogging clears those three bars. Information gain means the article says something the top-ranking results don't. A different angle, a more recent data point, a more specific use case. E-E-A-T signals mean there's a named author entity with verifiable credentials, outbound citations to primary sources, and a brand voice that reflects genuine positioning. Human review means a person approved the article before it published, even if they didn't write it.
The contrarian take most teams get wrong: volume is not the problem. Unreviewed volume is the problem. A site publishing 150 quality-gated articles per month will outperform a site publishing 10 manually written articles per month if the quality gate is doing its job. The math on topical authority favors the higher-volume operation, provided the quality floor is real.
For Answer Engine Optimization, this matters even more than for traditional SEO. AI engines select cited sources based on topical authority signals. How completely does a domain cover a subject area? A site with 10 articles on a topic loses the citation competition to a site with 80 articles on the same topic, assuming comparable quality. Auto blogging is the mechanism that builds topical authority at a pace that manual publishing can't match.

Who Should Use Auto Blogging (and Who Shouldn't)
The honest answer is that auto blogging fits some operations cleanly and others badly, and the determining factor is not company size. It's content governance maturity.
Solo founders are the trickiest case. The appeal is obvious: one person can't write 30 articles a month, but a well-configured auto-blog engine can. The risk is that solo founders often lack the editorial infrastructure to run a quality gate properly. If you're the only person in the operation, you're also the quality reviewer. And that role tends to get deprioritized when you're also doing sales, product, and support. The pattern I keep seeing is founders who set up auto blogging, let it run unsupervised for 60 days, and then wonder why their rankings dropped. The system worked fine. The governance didn't. For solo founders, auto blogging works best when the quality threshold is set high enough that the editorial gate rarely needs human intervention. Meaning the system self-filters aggressively.
SMBs with a content marketing function but no dedicated editorial team are probably the best fit for auto blogging. They have enough domain expertise to build a knowledge base that makes AI generation meaningfully differentiated, they have a business case for topical authority (outranking competitors in a defined category), and they have enough operational structure to maintain a review process. The use case that consistently works: an SMB in a defined vertical. Say, HR software or commercial real estate. Using auto blogging to cover every sub-topic in their category systematically, building the kind of topical coverage that earns AI citations for category-level queries.
Agencies running content operations for multiple clients have the most to gain and the most to lose. The gain is obvious: auto blogging scales output across a client portfolio without proportionally scaling headcount. The risk is that quality governance breaks down at scale. An agency running 15 client domains with a single quality standard will find that standard fits some clients well and others poorly. The solution is per-domain quality configuration, not a one-size threshold. For agencies evaluating platforms, the AEO vs SEO distinction matters: clients who need AI citation visibility require different quality criteria than clients optimizing purely for traditional rankings.
Who shouldn't use auto blogging? Organizations in highly regulated industries where factual errors carry legal or compliance risk. Healthcare, legal, financial services. Should not run auto-published content without a human expert reviewing every article before publish. The quality gate catches many errors, but not all, and the cost of a published error in those verticals exceeds the efficiency gain. Also: brands in the early trust-building phase, where every published piece is a direct brand signal to a skeptical audience, should prioritize quality over volume until the brand has enough authority to absorb the occasional imperfect article.
For everyone else, the question isn't whether to use auto blogging. It's whether your quality gate is real.
Wondering whether your auto-published content is being cited by AI engines — or ignored entirely?
Does Outranking Competitors Require More Content or Better Content?
Both, and the sequencing matters. This is where I see the most strategic confusion.
The teams that win on outranking competitors in AI-era search are doing two things simultaneously: publishing at high enough volume to build topical authority across a subject area, and maintaining quality high enough that each article earns genuine engagement signals and citation potential. Neither alone is sufficient.
Here's the data point that reframed how I think about this: the Ahrefs correlation research found that unlinked brand mentions correlate with AI Overview inclusion at 0.664, while Domain Rating correlates at only 0.326. Referring domains came in at 0.295. That gap is not marginal. It means the content you publish shapes your AI citation footprint through brand mention density. How often your brand gets named in relevant conversations across the web. More than through your link graph. Auto blogging, done right, creates the raw material for those mentions: articles that get shared, cited, and referenced in community discussions.
The AEO vs GEO distinction matters here too. Traditional SEO optimizes for ranking position. AEO optimizes for being the answer. GEO optimizes for being cited by AI systems. An auto-blog engine that's calibrated only for traditional ranking signals will underperform on AI citation metrics. The quality criteria need to include AEO signals: explicit Q&A structure, named entity definitions, self-contained quotable claims, and outbound citations to primary sources.
I've watched teams pour budget into link-building campaigns because they believed backlink equity would drive LLM visibility. The logic made sense. It worked for Google rankings. But the correlation data tells a different story. What I've started telling clients is that you can earn a mention without earning a link, and for LLM visibility purposes, that mention may be doing more work. Auto blogging accelerates the surface area for those mentions. More articles, covering more angles, in more specific sub-topics, means more opportunities to get named.
Tracking where those citations actually land requires a Perplexity AI visibility checker and equivalent monitoring across other AI surfaces. Without that feedback loop, you're publishing into a black box.
The Quality Gate Is the Whole Strategy
I want to be blunt about something the auto-blogging industry consistently undersells: the quality gate is not a feature. It's the strategy.
Every auto-blog platform will tell you their generation quality is excellent. Some of it is. But generation quality and publication quality are different things. Generation quality is how good the draft is when it comes out of the model. Publication quality is how good the article is after it's been scored, filtered, and approved. The gap between those two things is where most auto-blog operations fail.
A serious quality gate evaluates articles against multiple dimensions before they reach the CMS. At Meev, we built a 16-dimension Portfolio Quality Metric that blocks articles scoring below 70/100 from auto-publishing. Those dimensions include factual accuracy, source citation density, topical depth relative to competing articles, E-E-A-T signals, duplicate content risk, cannibalization against existing articles, and a Google Penalty Risk Matrix. Articles that fail go back for regeneration or human review. They don't publish.
The hidden costs of skipping this gate are real. As noted in research on auto-blogging AI systems, teams consistently underestimate the downstream costs of thin content: re-crawl budgets wasted on low-quality pages, ranking dilution across the domain, and the manual cleanup effort required when Google flags a site for scaled content issues. The quality gate is cheaper than the cleanup.
For teams evaluating platforms, the LLMs.txt validator is a useful starting point for understanding how AI engines read your site's content signals. Which feeds directly into whether your auto-published articles are eligible for citation in the first place.
The practical minimum for quality-gated content publishing to be safe: named author entity, outbound citations to primary sources in every article, a scoring threshold that blocks the bottom 30% of drafts, and a human approval step for any article that scores in the 70-80 range. That's not a high bar. It's a real bar, which is more than most operations have.
Outranking competitors in 2026 is not a content volume problem. It's a content governance problem. The teams that solve governance first, then scale volume, are the ones building durable topical authority. The kind that earns AI citations, survives algorithm updates, and compounds over time.
FAQ
Does auto blogging hurt SEO?
Auto blogging hurts SEO when it publishes without a quality gate. Google's Helpful Content System, now part of the core algorithm, evaluates whether content demonstrates genuine expertise and serves readers rather than search engines. Sites that publish unreviewed AI-generated content at scale risk ranking suppression or de-indexing. Auto blogging with a real quality gate. Factual verification, E-E-A-T signals, human approval checkpoints. Does not inherently hurt SEO. The mechanism is neutral. The governance determines the outcome.
Can auto-published content earn AI citations?
Yes, and this is where the opportunity is clearest. AI engines like Perplexity, ChatGPT, and Google AI Overviews select cited sources based on topical authority signals, brand mention density, and content quality. Not on whether a human typed the article. The Ahrefs correlation research found unlinked brand mentions correlate with AI Overview inclusion at 0.664. Auto blogging builds the surface area for those mentions by covering more sub-topics systematically. Quality-gated auto-published content that includes explicit Q&A structure, named entity definitions, and primary source citations is well-positioned for AI citation selection.
What's the minimum quality gate for auto blogging to be safe?
Four components are non-negotiable: a named author entity with verifiable credentials attached to every article; outbound citations to primary sources (not just named references. Actual hyperlinks); a scoring threshold that blocks the weakest drafts from publishing automatically; and a human review step for borderline articles. The specific threshold matters less than the existence of the gate. A system that publishes every generated draft without review is not quality-gated, regardless of how good the generation model is.
How does auto blogging relate to topical authority for AI search?
Topical authority is the degree to which a domain comprehensively covers a subject area. AI engines weight it heavily in citation selection because comprehensive coverage signals genuine expertise. Manual publishing can rarely build topical authority fast enough to outrank established competitors. Auto blogging is the mechanism that makes systematic topical coverage achievable. Publishing across every sub-topic in a category, filling keyword gaps competitors haven't addressed, and building the citation footprint that AI engines use to identify authoritative sources. The constraint is quality: every article in the topical cluster needs to clear the quality gate, or the cluster's authority signal degrades.
What's the difference between auto blogging and AI-assisted writing?
AI-assisted writing is human-driven: a person uses an AI tool to draft sections, then edits, restructures, and publishes manually. The human is the author; the AI is a tool. Auto blogging is pipeline-driven: from topic selection through CMS publishing, the system executes without a human drafting sentences. The human's role shifts from writer to system designer and quality governor. Both approaches can produce high-quality content. Auto blogging produces it at a volume and consistency that AI-assisted writing can't match. Which is why the quality gate matters more, not less, as volume increases.
How do I know if my auto-published content is being cited by AI engines?
You need AI visibility monitoring that tracks brand mentions across major AI search surfaces. ChatGPT, Claude, Gemini, Perplexity, Google AI Overviews, and others. With enough frequency to detect trends. Weekly monitoring is the minimum useful cadence; daily refresh on SERP-driven surfaces is better. Without this feedback, you can't tell which auto-published articles are earning citations, which topics are being won by competitors, or whether your quality gate is producing content that meets AI citation thresholds. The monitoring layer closes the loop from publish to performance.
About the Author
Judy Zhou, Founder
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
See exactly where your brand appears across every major AI search surface, and find the citation gaps your competitors are filling without you.