
By Judy Zhou, Founder
Key Takeaways
- 80% of LLM citations don't rank in Google's top 100 for the original query — traditional SEO rankings don't predict Perplexity citation success.
- Perplexity's citation gate rewards extractable, claim-first answers in the first 50 words of each section — not keyword-dense copy or schema-heavy formatting.
- The fastest path to citation is identifying which publishers Perplexity already trusts for your topic, then contributing attributable data or case studies to those domains.
- Getting cited without a paid search backstop is an incomplete strategy — AI citations create brand awareness that Google monetizes through paid clicks if you don't capture it first.
A solo founder in Austin typed a question about project management software into Perplexity on a Tuesday morning. Three sources appeared beneath the answer. A mid-sized SaaS blog, a niche review site she had never heard of, and a one-person newsletter with fewer than 4,000 subscribers. Her own company, which had spent two years building out a content library, wasn't there. She spent the next hour asking Perplexity variations of every question her customers ask. Her domain never appeared once. That afternoon, she started trying to understand why.
Perplexity SEO isn't a rebranded version of what you already do. Perplexity's citation-driven answer engine, as framed in a Harvard Business School case study, operates on a fundamentally different selection logic than Google's ranking algorithm. The question isn't whether your page ranks. It's whether Perplexity's retrieval layer trusts your page enough to quote it. An Ahrefs study analyzing 17 million citations across major AI platforms found that 80% of LLM citations don't rank in Google's top 100 for the original query. That's the number that should stop you cold. Reddit, which does zero structured SEO optimization, gets cited by major LLMs at roughly 40% frequency. While Wikipedia, equally unoptimized for AI, lands around 26%. The implication is uncomfortable: the format-first, schema-heavy approach most GEO vendors are selling may be solving the wrong problem entirely. Sites with high topical authority gain organic traffic 57% faster than low-authority sites, according to a Graphite study. And that same authority signal appears to drive AI citation patterns too.
The Citation Mechanism Nobody Explains Clearly
Perplexity runs on a Retrieval-Augmented Generation (RAG) architecture. Here's what that actually means for your content strategy: when a user submits a query, Perplexity doesn't consult a static knowledge base. It fires off a live web search, retrieves a set of candidate pages, and then passes those pages to its language model as context. The model synthesizes an answer and attributes the pieces it used. Your content has to clear two separate gates. The retrieval gate (does Perplexity's search layer find your page at all?) and the citation gate (does the model judge your page as the best source for a specific claim?).
The Ahrefs research complicates the conventional wisdom here. If 88% of ChatGPT citations come through the general search index, you might assume that ranking well on Google is sufficient. But 80% of those cited pages don't rank in Google's top 100 for the original query. They surface through what Ahrefs calls "fanout queries" — the secondary and tertiary searches an AI fires to build a complete answer. This means a page that would never earn a click from a human searcher can still get cited as an authoritative source. Traditional perplexity SEO advice ("rank top 10 for the keyword") misses this entirely.

Why Your Rankings Don't Predict Your Citations
I've watched brands with strong Google positions get completely skipped by Perplexity while a scrappier competitor with a third of the domain authority gets cited consistently. The pattern I keep seeing is that Perplexity's retrieval layer rewards specificity over authority scores.
Consider what the Austin founder's problem actually was. Her content library was built for Google's intent-matching logic: broad informational posts, comparison pages, pillar content with internal linking. That architecture works for traditional search. For Perplexity, it's nearly invisible because none of those pages answer a specific question in a way a language model can extract a discrete claim from.
The distinction matters. Google rewards topical coverage and backlink authority. Perplexity's citation gate rewards extractable answers. Paragraphs that begin with a direct response to a specific question, include a verifiable data point or named example, and don't require the reader (or the model) to wade through three paragraphs of context before reaching the actual answer. Reddit threads get cited because someone in the thread wrote "the answer is X, and here's why" in plain language. That's the format Perplexity's model finds easiest to attribute.
This is also why the mention-citation gap is a structural problem, not a pipeline problem. You can be mentioned in AI-adjacent conversations. On forums, in newsletters, in social posts. Without ever appearing as a cited source in an AI answer. The gap between being talked about and being attributed is wide, and closing it requires a different content strategy than most brands currently run.
How Perplexity Source Selection Actually Works
Perplexity's source selection combines three signals that interact in ways most guides don't address together.
The first is crawlability and freshness. The Ahrefs 17-million-citation study found that AI assistants do show a measurable preference for fresher content. Which means a page published or substantially updated in the last 90 days has a structural advantage over an older page with equivalent authority. This isn't about gaming publish dates. It's about maintaining an active publishing cadence so your domain stays in Perplexity's retrieval pool.
The second is claim density. Not the GEO-vendor version of "dense claim blocks" — I've tested that approach and seen no meaningful lift. What actually works is writing the way a knowledgeable person talks through a problem: one specific claim per paragraph, backed by a named source or a concrete example, written in language that reads like a real answer rather than a structured data schema with punctuation.
The third is topical depth. A Graphite study found that high topical authority correlates with 57% faster traffic gains. The same principle applies to AI citation: a domain that has published 15 articles on a specific subtopic is more likely to be retrieved for a query in that subtopic than a domain that has covered it once in a broad overview. This is where the AEO vs SEO distinction becomes practically useful. Answer Engine Optimization asks you to build depth around specific questions, not just coverage around broad topics.
Stop Optimizing for Keywords, Start Optimizing for Questions
The single most common mistake I see in perplexity AI seo strategies is treating Perplexity like a slower Google. Teams audit their keyword rankings, identify gaps, and publish more content targeting those gaps. The output looks like SEO content because it is SEO content. It just doesn't get cited.
Perplexity's model isn't matching queries to keywords. It's matching queries to answers. The practical difference: a page titled "Project Management Software for Remote Teams" is optimized for a keyword. A page that opens with "Remote teams using asynchronous workflows need project management software that separates task ownership from real-time communication. Tools like Linear and Height handle this better than Jira for teams under 20 people" is optimized for an answer. The second version is what gets cited.
This reframe has a name in the research community: Answer Engine Optimization, or AEO. The core mechanic is writing content that answers specific questions in the first 50 words of a section, before any context-setting or background. AI models extract from the top of sections, not the middle. If your actual answer is buried in paragraph four after three paragraphs of setup, Perplexity's citation gate will skip your page and cite someone who led with the answer.
Four structural changes that move the needle:
1. Open every H2 section with a direct answer to the implied question in the heading. 40 to 60 words, no preamble. 2. Include at least one named source, specific number, or concrete example per section. Vague claims don't get cited; attributable claims do. 3. Use question-shaped headings for at least half your H2s. Perplexity's fanout queries often match question syntax, and your heading is part of what gets retrieved. 4. Keep paragraphs short enough that a language model can extract a single claim without ambiguity. Three-sentence paragraphs with one idea each outperform dense 150-word blocks.
The Mention-Citation Gap Is a Revenue Problem
Here's the contrarian take nobody in the perplexity SEO space wants to say out loud: getting cited by AI without a paid search backstop isn't a complete strategy. It's an incomplete one.
When Perplexity or any other AI answer engine cites your brand, the user learns your name but has no click path. These tools don't send traffic. They absorb the query and return a synthesized answer. So what happens next? The user goes to Google and searches your brand name. If you're not running branded paid search, you may not capture that demand at all, especially if a competitor is bidding on your brand terms.
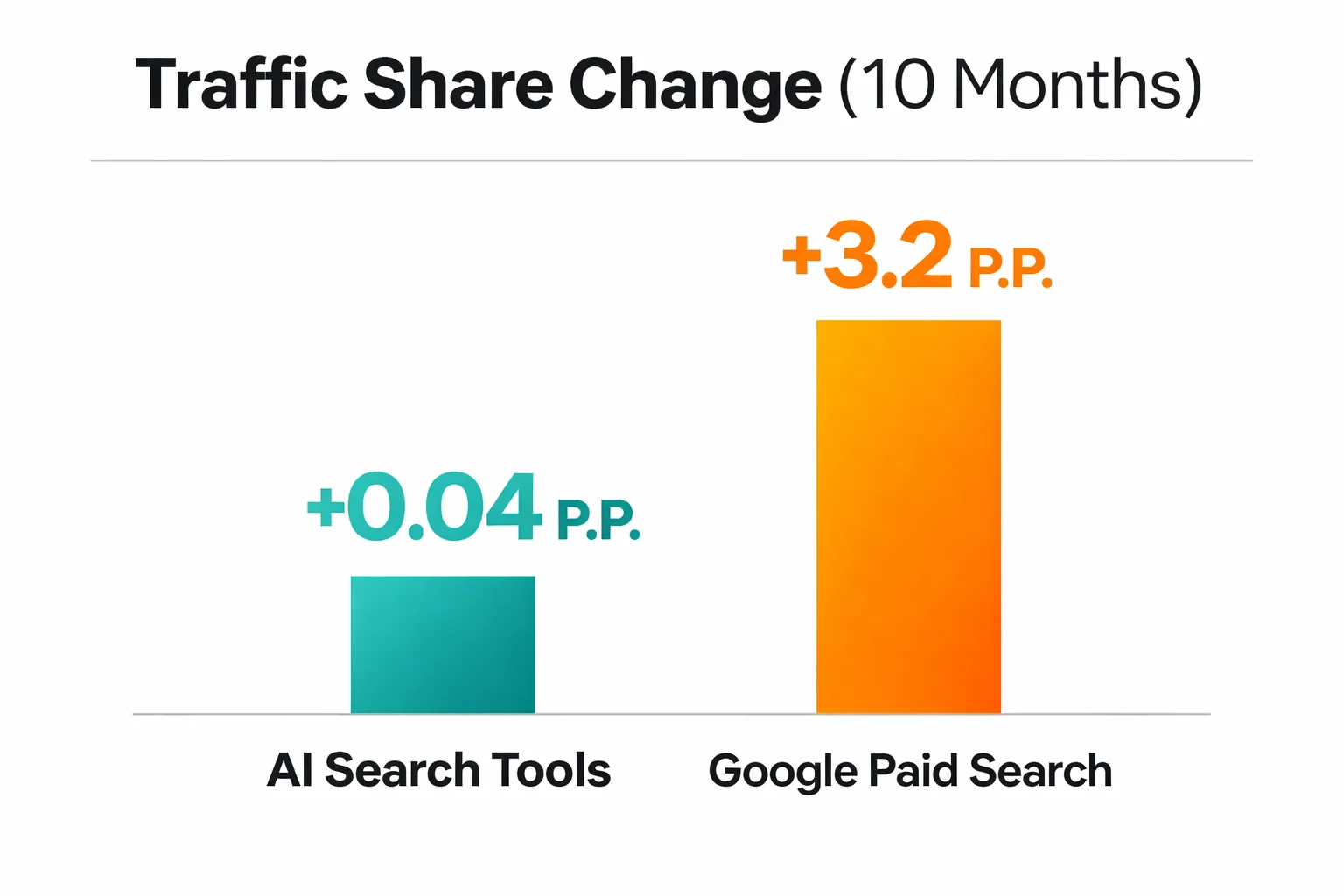
There's data that makes this concrete. An Ahrefs panel of roughly 75,000 websites tracked over 10 months found that AI search tools gained 0.04 percentage points of traffic share while Google's paid search captured 3.2 percentage points over the same period. Google lost organic share and gained it back in paid. The businesses being cited by AI are essentially funding that transfer. Their AI visibility creates brand awareness that Google then monetizes through paid clicks.
I've started telling founders: the citation creates demand you don't automatically capture. Getting cited in Perplexity is a brand signal, not a traffic channel. Treat it like PR. Measure it as share of voice, back it up with paid search, and don't confuse visibility with acquisition.
Want to know which prompts Perplexity is answering without citing your brand?
Building a Citation Path: Publisher Outreach for AI Visibility
Organic citation is slow. The faster path to Perplexity visibility is getting cited by the publishers Perplexity already trusts for your topic area.
This is what I'd call Citation Path strategy, and it has three steps.
First, identify which domains Perplexity cites when answering questions in your topic area. Run 20 to 30 queries that your customers actually ask. The specific, conversational questions, not the head terms. Note which domains appear in citations repeatedly. Those are your target publishers. Tools like Meev's Citation Path feature automate this discovery, surfacing the domains AI engines cite most for your specific topic cluster and flagging verified contacts at each publisher.
Second, audit the gap between mentions and citations. Your brand may already be mentioned on some of those domains. In comments, in roundup posts, in forum threads. Without being cited as a source in an AI answer. That gap is closeable. A direct relationship with the publisher, a contributed piece, or a data asset they can reference converts a passive mention into an attributable citation.
Third, pitch with a knowledge-base-grounded angle. Generic outreach doesn't work here. The pitch needs to give the publisher something their existing content doesn't have: a proprietary data point, a specific case study, a contrarian position backed by evidence. The more specific and attributable your contribution, the more likely it gets cited when that publisher's content is retrieved by Perplexity.
The Reddit v. Perplexity lawsuit filed against scraping companies adds a wrinkle here. Publishers are increasingly aware that their content is being synthesized by AI without direct traffic benefit. Some are restricting access. A relationship-first outreach approach. Where you're offering genuine editorial value, not just seeking citation placement. Is more durable than assuming AI systems will always have unlimited access to publisher content.
The Scaled Content Trap in Perplexity SEO
I need to address the temptation directly. When you understand that Perplexity rewards freshness and topical depth, the obvious move is to scale content production. Publish more, cover more questions, maintain a higher cadence. That logic is correct in theory and dangerous in practice.
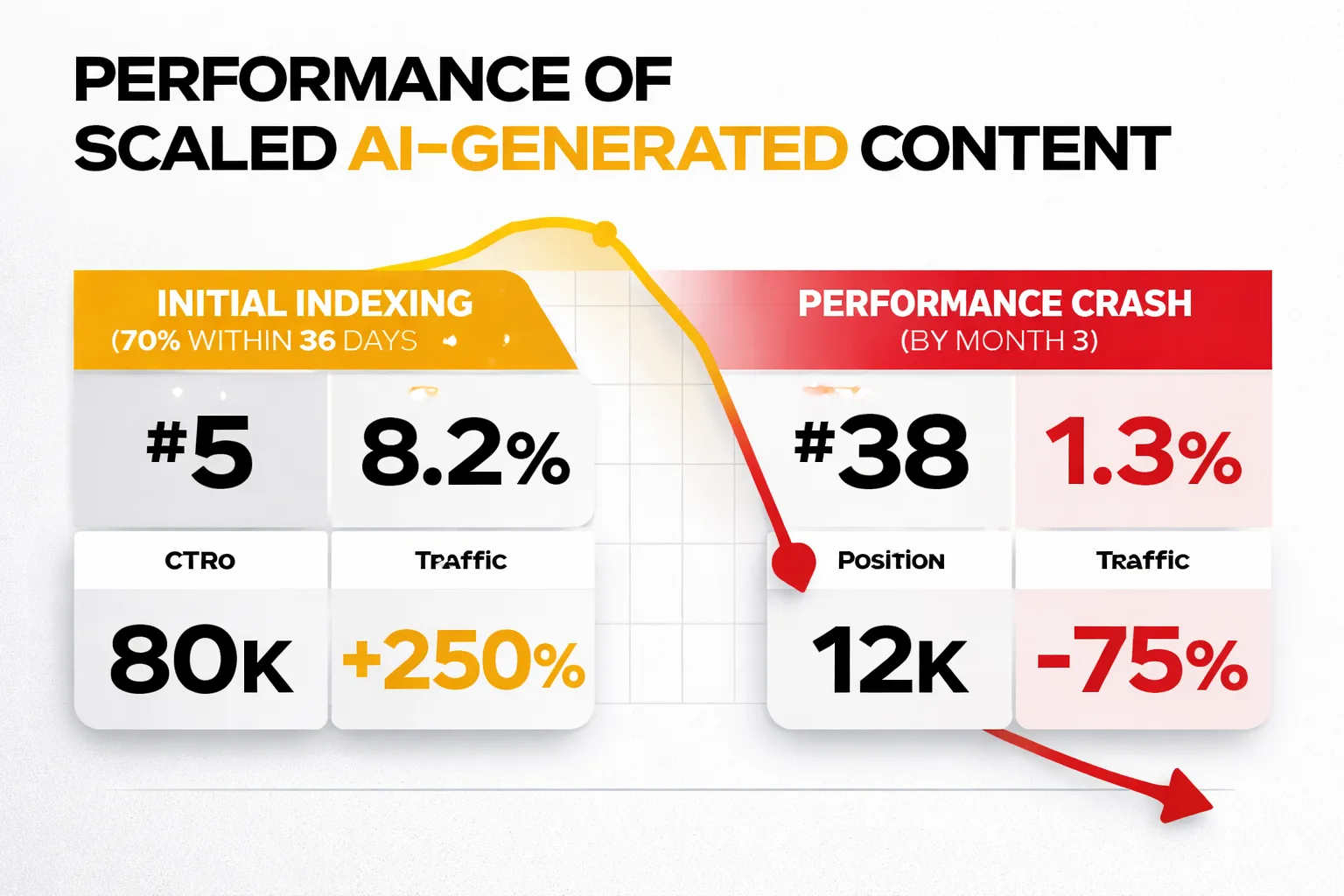
A study of 20-plus sites that each published 100 AI-generated articles (2,000 total articles across the panel) showed strong initial indexing. 70% of content indexed within 36 days. Followed by a performance crash by month three. The sites that scaled fast burned out fast. The initial indexing signal looked like success. The month-three drop looked like a penalty, and recovery from scaled content issues is slow and unforgiving.
The failure mode in auto-blog pipelines isn't gradual drift. It's discrete and fast. A quality-gate misconfiguration, a batch of thin content that trips a spam signal, and Google's response can move you from page one to page seven in days. That matters for perplexity SEO because Perplexity's retrieval layer uses Google's index as a primary source. If your domain takes a Google penalty, your Perplexity citations disappear with it.
The right approach to content at scale is quality-gated publishing: a system that generates content at volume but blocks weak drafts before they reach your CMS. At Meev, I've seen this modeled as a 16-dimension quality firewall that scores every article across content quality signals and Google penalty risk factors before auto-publishing. Articles below a threshold score don't ship. The cadence stays high; the quality floor stays intact. That's the architecture that compounds without crashing.
For generative engine optimization at scale, the goal is a sustainable publishing rate. Three to five well-structured, claim-dense articles per week. Rather than a burst-and-crash cycle.
Tracking Perplexity Citations. What to Actually Measure
Most teams have no idea whether Perplexity is citing them. They check Google Search Console, maybe Semrush, and assume that covers AI visibility. It doesn't.
Perplexity citations don't show up in GSC referral data the way a standard backlink does. The measurement problem is real: you need to run systematic prompt testing. Submitting the questions your customers actually ask and recording which sources Perplexity cites in response. Do this manually across 20 to 30 prompts and you get a snapshot. Automate it with a tool that tracks citation patterns across AI surfaces and you get a trend.
The metrics worth tracking: citation frequency (what percentage of relevant prompts cite your domain), mention position (are you cited first, in a list, or last. Position correlates with how prominently the model weighted your content), and share of voice against competitors (what percentage of answers cite you versus each competitor for your topic cluster).
For AI search visibility tracking specifically, Meev's free Perplexity Brand Visibility Checker is a starting point for understanding where you stand before investing in a full monitoring workflow. The paid tier adds daily refresh, competitor share-of-voice, and the actual response text behind every citation so you can see exactly which claim Perplexity extracted from your content.
One thing I track that most guides skip: the cited-source leaderboard for your topic. Knowing which domains Perplexity cites most often for your specific queries tells you exactly which publishers to target in your Citation Path outreach. That's not a vanity metric. It's a prospecting list.
FAQ
Does ranking on Google's first page guarantee Perplexity will cite me?
No. The Ahrefs study of 17 million citations found that 80% of LLM citations don't rank in Google's top 100 for the original query. Perplexity retrieves pages through secondary "fanout queries" that operate on different ranking dynamics than the primary SERP. A page that never earns a human click can still be cited as an authoritative source if it answers a specific sub-question clearly.
How is Perplexity SEO different from traditional SEO?
Traditional SEO optimizes for keyword ranking and click-through from a results page. Perplexity SEO optimizes for citation. Being selected as a source the model quotes in a synthesized answer. The content architecture is different: you need extractable, claim-first paragraphs rather than keyword-dense copy, and topical depth over broad coverage. You can explore the full distinction at AEO vs SEO: What's the Difference.
How often should I publish to stay in Perplexity's retrieval pool?
Freshness is a confirmed citation signal in the Ahrefs research. A sustainable cadence of three to five quality articles per week appears to maintain retrieval eligibility without triggering the scaled-content penalties that hit sites publishing at much higher volumes. The key word is quality-gated. Volume without a quality floor causes more harm than a slower cadence.
Can I track whether Perplexity is citing my brand?
Yes, but not through standard analytics. You need systematic prompt testing. Running the questions your customers ask and recording Perplexity's cited sources. Meev's free Perplexity Brand Visibility Checker automates this for a snapshot view. For ongoing monitoring with competitor share-of-voice and daily refresh, a dedicated AI search visibility platform is necessary.
What's the fastest way to start getting cited by Perplexity?
The Citation Path approach: identify which publishers Perplexity already cites for your topic, build a relationship with those publishers, and contribute a piece that contains a specific, attributable data point or case study they don't already have. Getting cited by a domain Perplexity trusts is faster than building that trust from scratch on your own domain.
Does E-E-A-T matter for Perplexity citations the same way it does for Google?
The signals overlap more than they diverge. Perplexity's retrieval layer favors content with named authors, verifiable credentials, specific data points, and first-person experience signals. Which are exactly the E-E-A-T signals Google's Helpful Content System rewards. Optimizing for both simultaneously isn't a contradiction. The supposed tension between writing for AI citation and writing for Google's HCS is mostly a false dilemma. Write like a knowledgeable person explaining something to a peer, cite your sources, and both systems reward you.
About the Author
Judy Zhou, Founder
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Run a free Perplexity brand visibility check and see exactly where your domain stands — before your competitors close the gap.