唯一的 H1 标题:唯一必需的元素
文件以单个 markdown H1 开头,写明你的网站或项目名称:“# 你的网站名称”。这套约定中的其他一切都是可选的;没有这个标题,解析器就无法判断自己读的是谁的文件。
免费工具 · 无需注册
粘贴你的 llms.txt 或输入你的域名:我们会抓取该文件,并对照 llms.txt 约定进行检查(标题、摘要、章节、链接说明、格式和大小)。你会得到一份带通过/警告/失败评分的清单,并附上每一处遗漏的修复方法。
llms.txt 校验工具会检查一个网站的 llms.txt 文件是否遵循拟议标准:一个 markdown H1 标题、一个可选的引用块摘要,以及若干列有带说明链接的 H2 章节。它会标记出缺失的结构、用 HTML 代替 markdown、空章节以及无说明的 URL 堆砌,让 AI 引擎能够按预期读取该文件。
llms.txt 标准刻意保持精简:一个位于网站根目录的 markdown 文件,包含一个标题、一个可选摘要,以及若干列有带说明链接的章节。校验工具会逐条检查这些规则。以下是这些规则的内容,以及每一条为何重要。
文件以单个 markdown H1 开头,写明你的网站或项目名称:“# 你的网站名称”。这套约定中的其他一切都是可选的;没有这个标题,解析器就无法判断自己读的是谁的文件。
一行以“>”开头、说明网站是做什么的文字。它是可选的,但正是 AI 引擎在描述你时会摘取的那句话,所以自己写好它,而不要让它们去猜。
像“## 文档”“## 产品”或“## 指南”这样的章节,能把一堆链接变成可导航的索引。一个“## 可选”章节则标出当引擎阅读预算紧张时可以跳过的链接。
每个链接都是一个列表项,形式为“- [页面名称](url): 一行说明”。说明正是让索引变得有用的地方;一堆没有上下文的裸 URL,无法告诉引擎哪个页面回答了什么。
文件必须以纯 markdown 文本形式提供。我们见到最常见的失败,是 CMS 或单页应用在 /llms.txt 处返回它的 HTML 兜底页面:它在浏览器里看起来没问题,对解析器却无法读取。
AI 助手在有限的上下文预算内阅读 llms.txt。一份简短、高信噪比、列出你最重要页面的清单,胜过一次穷尽式的堆砌;超过几百 KB 之后,文件的大部分内容永远不会被读到。
上面的每一条规则,浓缩在一个简短文件里:单个 H1、一个引用块摘要、一段朴素散文式的介绍、分组的章节,以及每个链接上的说明。
# Acme Analytics > 面向早期 SaaS 团队的产品分析:事件跟踪、漏斗和留存报告,没有企业级的高昂价格。 Acme Analytics 帮助创始人从第一天起就理解用户行为。 ## 产品 - [功能](https://acme.example/features): 事件跟踪、漏斗、群组和留存报告 - [价格](https://acme.example/pricing): 从免费到规模化的各种套餐,可按月或按年计费 ## 指南 - [快速上手](https://acme.example/docs/quickstart): 安装代码片段,五分钟内看到你的首批事件 - [漏斗分析](https://acme.example/docs/funnels): 一步步构建和解读转化漏斗 ## 可选 - [更新日志](https://acme.example/changelog): 每周产品更新
还没有 llms.txt? 几秒内从你的站点地图生成一个,然后在发布前在这里校验它。
免费 · 无限次检查 · 无需注册
What Meev is
Meev tracks where your brand appears across ChatGPT, Claude, Gemini, Perplexity, Grok, DeepSeek, Google AI Overviews, and Google AI Mode — then shows what to fix, publish, or pitch next to improve AI visibility.
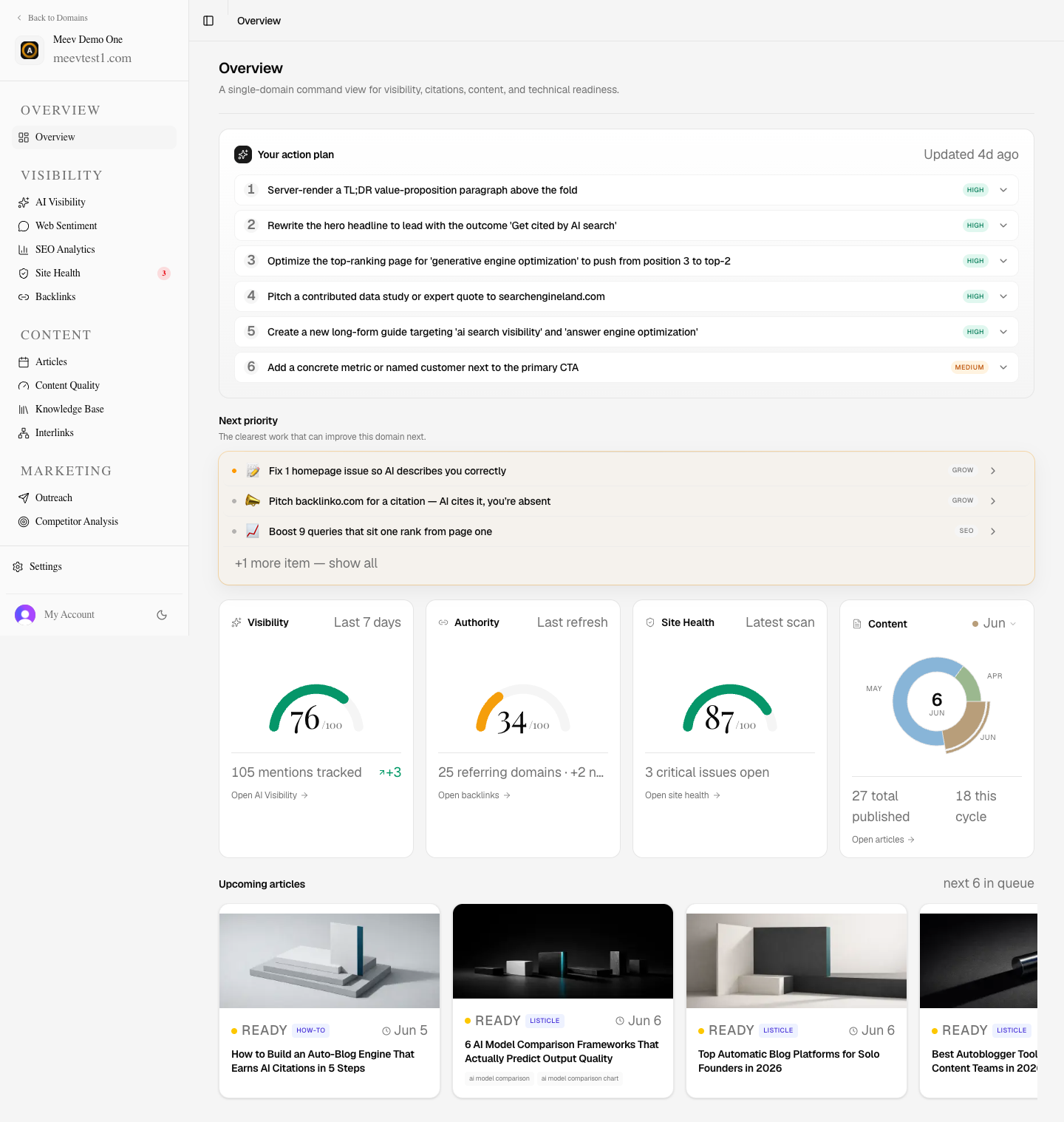











The path to getting cited
01 · Your domain
Meev reads your existing pages, topics, and Google Search Console signals to learn what your site is about and already ranks for: the foundation for every gap, draft, and citation that follows.
第 1 步
粘贴或抓取
直接粘贴文件,或输入你的域名,我们会替你抓取 /llms.txt。
第 2 步
我们解析结构
标题、摘要、章节、链接和说明:与 AI 引擎解析的结构完全相同。
第 3 步
评分清单
每条规则都会得到通过、警告或失败的判定,并附上通俗易懂的解释。
第 4 步
修复并重新运行
每一处遗漏都会告诉你到底该改什么。重新发布、再次校验,干净地上线。
读取 llms.txt 的 AI 引擎按结构来解析它:H1 告诉它们这是谁的文件,引用块告诉它们网站是做什么的,章节告诉它们哪些页面回答了什么。当这套结构被破坏时(在该路径上提供了一个 HTML 页面、缺少标题、链接没有上下文),解析器要么提取出关于你网站的错误画面,要么悄无声息地放弃。什么都不会报错;你只是发布了一个歪曲自己的文件。
因为 llms.txt 只是 markdown,几乎什么内容看起来都像模像样。我们见到的失败都很平常:CMS 在 /llms.txt 处以 200 状态返回它的 HTML 404 兜底页、把站点地图导出的成百上千条裸 URL 直接粘进来、有标题却下面什么都没有的章节,或者一个把文件拦腰截成两段的第二个 H1。每一种在浏览器里都看似正常,对解析器却是坏的,这正是为什么对照真正的约定来检查,胜过用肉眼去审视。
llms.txt 提案之所以选择 markdown 标题、引用块和链接列表,正是因为它们对应一棵干净的解析树:程序化工具无需任何自然语言的猜测,就能把文件拆成标题、摘要和章节。遵循这套结构,每一个支持 llms.txt 的工具都会以相同的方式读取你的文件;偏离它,每个工具都会以不同的方式劣化。遵守约定,正是采用一个标准的全部价值所在。
搭配 Meev
一个干净的 llms.txt 帮助 AI 引擎找到你的页面;Meev 则给它们更多值得被找到的页面。它会自动规划、撰写并向你的博客发布通过质量把关的文章,然后跟踪 AI 引擎是否真的在那些重要的查询上引用了你。
llms.txt 是一个拟议标准:一个发布在你域名根目录(类似 robots.txt)的纯 markdown 文件,为 AI 引擎提供你网站的精选概览。它包含一个 H1 标题、一个可选的引用块摘要,以及列出你最重要页面并附一行说明的 H2 章节。目的是帮助语言模型在不抓取全部内容的情况下,准确地理解并引用你的网站。
它是一个拟议标准:一套有公开规范的公共约定,而非由 W3C 或 IETF 这类标准机构正式批准的东西。这与 robots.txt 走过的路相同:它靠社区约定运行了几十年,之后才被正式标准化。AI 工具和爬虫对它的采用正在增长,而严格遵循这套约定,正是让兼容性最大化的方式,适用于一切读取它的工具。
采用在增长,但尚未普及。已有不少 AI 工具、爬虫和答案引擎会读取 llms.txt,而这个标准之所以有势头,是因为它解决了一个真实的问题:原始 HTML 对语言模型来说是一种低效的格式。发布一个格式良好的文件不花任何成本,也没有任何坏处,所以务实的答案是:把它发布出去,保持它有效,并随着采用范围扩大而受益。
取自 llms.txt 约定的结构性规则:文件是 markdown 而非 HTML、由单个 H1 标题开头、标题之后跟一个引用块摘要、由 H2 章节组织链接、没有空章节、链接使用 markdown 列表格式而非裸 URL 堆砌、链接带有一行说明,以及文件保持足够简洁以契合 AI 助手的阅读预算。每条规则都会返回通过、警告或失败,并附上通俗易懂的修复方法。
通常不会完全忽略:大多数解析器都很宽容,会尽可能提取它能提取的内容。但结构决定了它们能提取多少:缺少标题,或用 HTML 代替 markdown 的失败,可能让整个文件无法读取,而像缺少说明这样的警告,只会降低它的有用程度。先修复失败项;它们决定了文件是能被解析,还是无法被解析。
llms.txt 是那份精选索引:一个简短的、由带说明链接组成的文件,把引擎引向你的重要页面。llms-full.txt 是一个可选的配套文件,它把那些页面的完整内容内联进一个大的 markdown 文档,供想要一次性获取全部内容的工具使用。这个校验工具检查的是索引文件;如果两者你都发布,那么索引才是需要在结构上保持干净的那一个。
Meev 跟踪你在各大 AI 搜索平台上的可见度,并自动发布通过质量把关、能够赢得引用的内容。
7 天免费试用,随时可取消。
AI Search
LLMs.txt Generator
Generate an llms.txt file so AI engines index your site correctly
AI Search
AI SEO Audit
Audit any page for AI-search readiness in 30 seconds
AI Search
Topical Map Generator
Map any site's content into topic clusters from its sitemap
AI Search
AI Crawler Simulator
See what GPTBot, ClaudeBot, and Googlebot see on your page
AI Search
Query Fan-Out Generator
Turn one query into 25+ AI-search variations, grouped by intent
AI Search
Page Token Inspector
See your page the way an AI engine reads it — token by token