AI 引擎读取的是 token,而不是页面,而 token 是一份有限的预算。
当 AI 引擎在生成答案时考虑你的页面,它会把可提取的文本载入一个以 token 计量、大小固定的上下文窗口。臃肿的页面要和其他所有来源争夺这份预算;精简、结构良好的页面则能低成本、完整地放进去。了解页面的 token 体量,就能知道它在这种约束下的表现。
免费工具 · 无需注册
输入任意网址,像 AI 引擎那样查看这个页面:预估的 token 数量、它占据上下文窗口的比例、最突出的焦点词,以及 AI 引擎真正提取到的精简文本。
token(词元)是 AI 引擎在处理页面时读取和计数的最小文本单位,可以是一个词,也可以是一个词的片段。页面的 token 数量反映了它会占据 AI 助手有限上下文窗口的多少,而这会影响页面能被多充分地读取,以及能否被引用到答案里。
免费 · 无限次检查 · 无需注册
What Meev is
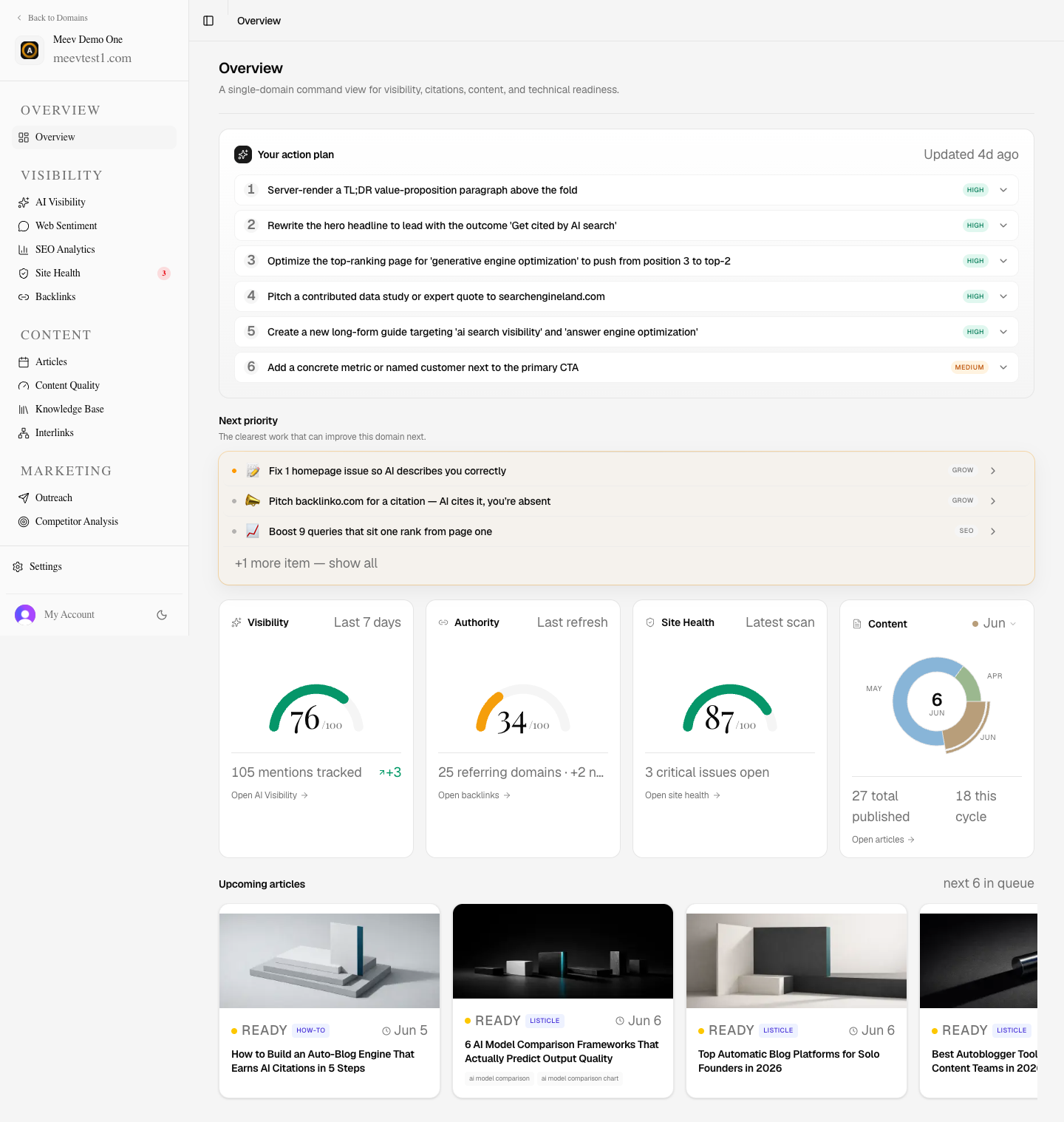
Meev tracks where your brand appears across ChatGPT, Claude, Gemini, Perplexity, Grok, DeepSeek, Google AI Overviews, and Google AI Mode — then shows what to fix, publish, or pitch next to improve AI visibility.











The path to getting cited
01 · Your domain
Meev reads your existing pages, topics, and Google Search Console signals to learn what your site is about and already ranks for: the foundation for every gap, draft, and citation that follows.
第 1 步
输入网址
任何公开页面:一篇文章、一个落地页或一份文档。
第 2 步
我们把它精简为文本
去除标记、导航、脚本和样式,只留下 AI 引擎实际处理的可提取文本。
第 3 步
Token 与窗口计算
预估 token 数、字词与字符数,以及在 128K、200K 和 1M 上下文窗口下的占用百分比。
第 4 步
读懂这些信号
排名靠前的焦点词显示在引擎眼中这个页面到底“讲的是什么”,不足 300 词时还会标记内容单薄。
当 AI 引擎在生成答案时考虑你的页面,它会把可提取的文本载入一个以 token 计量、大小固定的上下文窗口。臃肿的页面要和其他所有来源争夺这份预算;精简、结构良好的页面则能低成本、完整地放进去。了解页面的 token 体量,就能知道它在这种约束下的表现。
引擎看不到你的设计、你的 JavaScript 组件,也看不到你精心设计样式的首屏区块,它们看到的是去除标记后可见的文本。如果精简后的版本大多是导航标签和页脚链接,那这就是你的页面对 AI 引擎“说”的话。本工具的预览展示的正是这个版本,这往往会让人警醒。
可提取文本不足约 300 词的页面,很少含有足够的实质内容供 AI 引擎引述或引用,因为根本没有足够的素材可供提取出答案。如果你的重要页面显示为内容单薄,解决办法就是真正的正文:定义、解释、常见问题解答,以及引擎可以直接搬进答案的数据。
搭配 Meev
Token 高效的结构、答案优先的正文,以及足以被引用的实质内容:Meev 发布到你域名上的每一篇文章,都是按照 AI 引擎实际的阅读方式来打造的。随后,可见度追踪会告诉你这些页面是否在各大 AI 搜索平台上赢得了引用。
这是基于英文文本“大约每 4 个字符算 1 个 token”这一标准经验法则得出的估算,通常与 AI 引擎分词器给出的结果相差在约 ±10% 以内。对于本工具支持的决策来说,这已经足够准确:比较页面、发现臃肿,以及判断是否适配上下文窗口。
上下文窗口是 AI 模型一次能够处理的最大文本量,以 token 计量。如今常见的规格是 128K、200K 和 1M token。模型用来生成答案的一切内容(包括你的页面)都必须放进这个窗口,因此占用窗口更少的页面,引擎更容易低成本地完整使用。
因为 AI 引擎在阅读之前正是这么做的。HTML 标记、脚本、样式和隐藏元素都会被去除,剩下的就是引擎据以推理的可提取文本。预览展示给你的正是这个版本:如果关键内容在其中缺失了,引擎也同样看不到那些内容。
焦点词是过滤掉“的”“和”这类常见词之后,页面上出现频率最高的有意义词汇。它们可以快速反映在引擎看来这个页面主题“讲的是什么”。如果你的目标主题没有出现在排名靠前的焦点词里,那这个页面读起来很可能是在讲别的东西。
可提取文本很少的页面很少被引用,因为没有足够的实质内容可供提取出答案。大约 300 词是一个实用的底线:低于这个数,页面通常是一个内容残缺的桩页、一个跳转外壳,或是一个内容从未进入 HTML 的 JavaScript 应用。无论哪种情况,它作为来源都是隐形的。
并非如此,目标是每个 token 的实质含量,而不是一味追求极简。用套话堆砌的 50,000 token 页面是浪费,但只有 200 token 的页面又没有任何可供引用的内容。最适合 AI 搜索的页面,会把真实、呈答案形态的信息高密度地组织起来:既有足够深度成为可信来源,又不会因臃肿而被埋没。
Meev 跟踪你在各大 AI 搜索平台上的可见度,并自动发布通过质量把关、能够赢得引用的内容。
7 天免费试用,随时可取消。
AI Search
LLMs.txt Generator
Generate an llms.txt file so AI engines index your site correctly
AI Search
LLMs.txt Validator
Check your llms.txt against the standard — scored pass/warn/fail
AI Search
AI SEO Audit
Audit any page for AI-search readiness in 30 seconds
AI Search
Topical Map Generator
Map any site's content into topic clusters from its sitemap
AI Search
AI Crawler Simulator
See what GPTBot, ClaudeBot, and Googlebot see on your page
AI Search
Query Fan-Out Generator
Turn one query into 25+ AI-search variations, grouped by intent