如果 AI 爬虫抓取不到你的页面,你就不可能被引用,就这么简单。
ChatGPT、Claude 和 Perplexity 根据爬虫真正能读到的页面来生成回答。robots.txt 里的一条 disallow 规则、一条防火墙规则,或者一个对 GPTBot 返回 403 的反爬中间件,都会悄无声息地把你从这些引擎生成的所有回答中剔除。页面在你的浏览器里看起来一切正常,所以没人会察觉,直到引用被竞争对手拿走。
免费工具 · 无需注册
输入任意网址,我们会分别以 Googlebot、GPTBot、ClaudeBot、PerplexityBot、Bingbot 和普通浏览器的身份抓取六次,然后对比状态码、robots.txt 的访问情况,以及每个爬虫真正能读到多少文字。
AI 爬虫是一种自动化机器人,它抓取网页,让 AI 搜索引擎能够读取、索引并引用这些页面。常见的有 GPTBot、ClaudeBot、PerplexityBot 和 Googlebot。如果爬虫被拦截,或者页面只能通过 JavaScript 渲染,这些内容可能永远无法进入 AI 的回答。
免费 · 无限次检查 · 无需注册
What Meev is
Meev tracks where your brand appears across ChatGPT, Claude, Gemini, Perplexity, Grok, DeepSeek, Google AI Overviews, and Google AI Mode — then shows what to fix, publish, or pitch next to improve AI visibility.
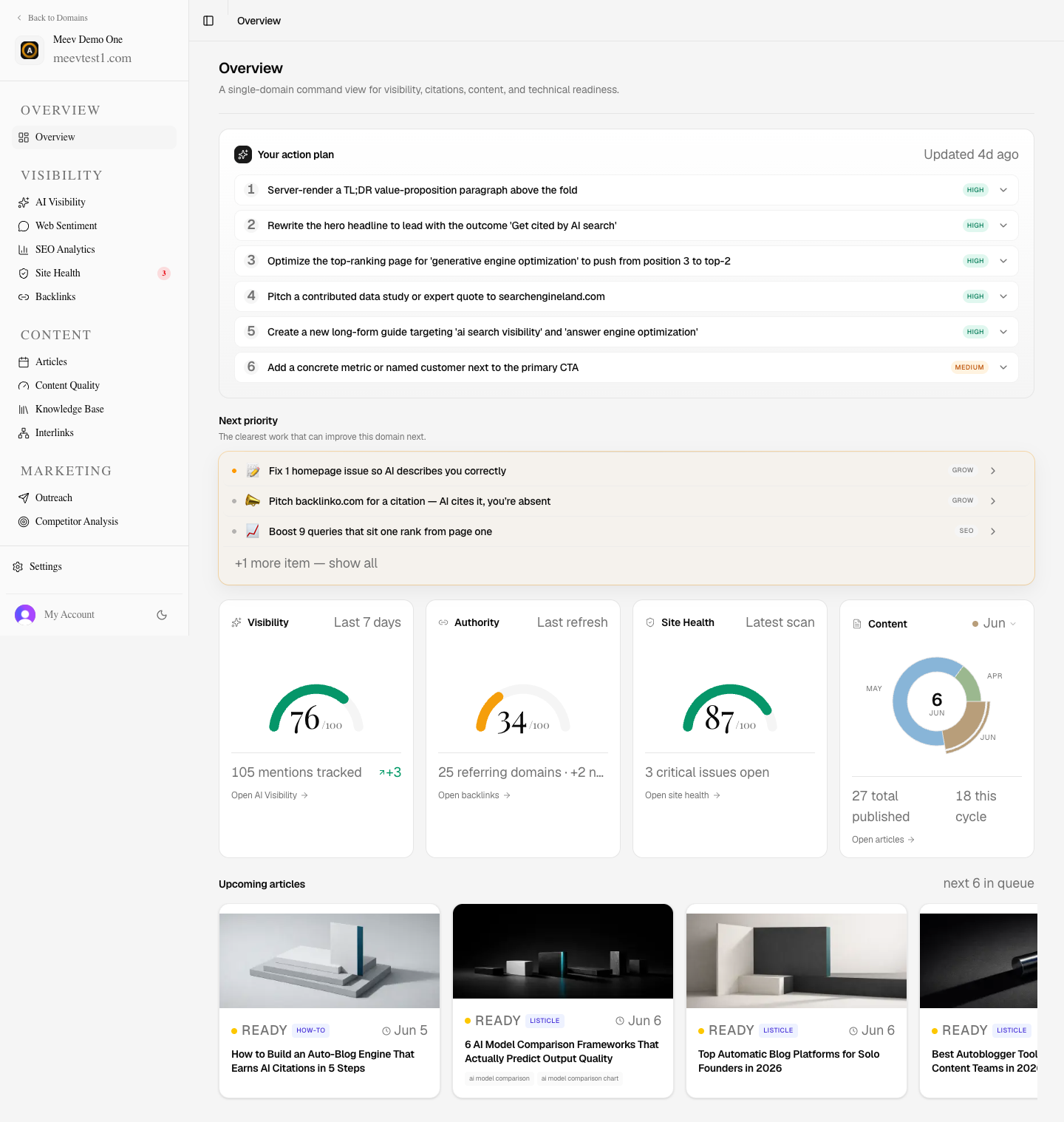











The path to getting cited
01 · Your domain
Meev reads your existing pages, topics, and Google Search Console signals to learn what your site is about and already ranks for: the foundation for every gap, draft, and citation that follows.
第 1 步
输入网址
任意公开页面,你自己的或竞争对手的都行。
第 2 步
并行发起六次抓取
我们以每个爬虫的身份请求页面,使用它真实的 user-agent 字符串,同时抓取你的 robots.txt。
第 3 步
并排对比
状态码、robots.txt 判定结果、可提取的文字和标题,每个爬虫一行。
第 4 步
查看判定结果
用通俗易懂的提示标出被拦截的机器人,以及依赖 JavaScript 渲染导致的内容缺口。
ChatGPT、Claude 和 Perplexity 根据爬虫真正能读到的页面来生成回答。robots.txt 里的一条 disallow 规则、一条防火墙规则,或者一个对 GPTBot 返回 403 的反爬中间件,都会悄无声息地把你从这些引擎生成的所有回答中剔除。页面在你的浏览器里看起来一切正常,所以没人会察觉,直到引用被竞争对手拿走。
大多数 AI 爬虫不会执行 JavaScript。如果你的内容是在客户端渲染的,爬虫可能只收到一个几乎空白的外壳,而你的浏览器却显示出完整的文章。对比每个 user-agent 收到的文字量,是发现这种差距最快的方法:当机器人拿到的内容不足浏览器的 60% 时,你的内容对 AI 引擎来说几乎是隐形的。
有些网站会刻意拦截 AI 训练爬虫,这是合理的选择。问题在于意外拦截:CDN 的反爬模式、一条过于激进的 WAF 规则,或者从模板里复制来的一行 robots.txt。运行这个模拟只需几秒,就能准确告诉你哪些爬虫被拦截,以及被拦在哪一层:是 robots.txt,还是服务器本身。
搭配 Meev
抓取访问只是第一步。Meev 会自动向你的域名发布针对 AI 提取优化的文章,然后监控各大 AI 搜索平台(ChatGPT、Claude、Gemini、Perplexity、Google AI 概览),向你展示你的品牌在真实回答中出现在哪里。
共六个:Googlebot(Google 搜索)、GPTBot(ChatGPT 背后的爬虫)、ClaudeBot(Claude)、PerplexityBot(Perplexity)、Bingbot(Bing),以及一个普通桌面浏览器作为对照。每次抓取都使用该爬虫真实的 user-agent 字符串,因此服务器端的反爬规则会像在生产环境中一样做出响应。
你的 robots.txt 文件里有一条规则,禁止该爬虫抓取该页面的路径。像 GPTBot 和 ClaudeBot 这样守规矩的爬虫会遵守这些规则,所以一条 disallow 规则实际上会把你的内容从这些 AI 引擎中移除。我们会同时检查针对特定爬虫的分组和通配符(*)分组。
大多数 AI 爬虫不运行 JavaScript。如果你的页面是在浏览器里构建内容的(单页应用框架很常见),爬虫只会收到最初的 HTML 外壳。服务器端渲染或静态生成可以解决这个问题:完整内容会在第一次响应中就发送出去,这样每个爬虫读到的都和你的访客一样。
你的服务器、CDN 或反爬防护层正在按 user-agent 或机器人指纹进行过滤。常见的元凶包括 CDN 的反爬模式、WAF 规则,以及默认拒绝机器人列表的安全插件。如果你希望 AI 引擎引用你,请为你信任的爬虫添加明确的放行规则。
这取决于你的目标。拦截 GPTBot 或 ClaudeBot 能让你的内容不进入训练数据和 AI 回答,这保护了独家性,但也放弃了引用,以及 AI 引擎越来越多带来的引荐流量。大多数争夺可见度的企业都希望放行 AI 爬虫;而销售独家内容的出版商有时则不希望。
不是。Search Console 只测试 Googlebot。这个工具补上了 Search Console 覆盖不到的 AI 爬虫:GPTBot、ClaudeBot 和 PerplexityBot。一个页面可以在 Google 里被完美索引,却对 ChatGPT 和 Perplexity 完全隐形,只有多爬虫对比才能揭示这一点。
Meev 跟踪你在各大 AI 搜索平台上的可见度,并自动发布通过质量把关、能够赢得引用的内容。
7 天免费试用,随时可取消。
AI Search
LLMs.txt Generator
Generate an llms.txt file so AI engines index your site correctly
AI Search
LLMs.txt Validator
Check your llms.txt against the standard — scored pass/warn/fail
AI Search
AI SEO Audit
Audit any page for AI-search readiness in 30 seconds
AI Search
Topical Map Generator
Map any site's content into topic clusters from its sitemap
AI Search
Query Fan-Out Generator
Turn one query into 25+ AI-search variations, grouped by intent
AI Search
Page Token Inspector
See your page the way an AI engine reads it — token by token