単一の H1 タイトル。唯一の必須要素です
ファイルは、サイトやプロジェクトの名前を記した単一の markdown H1 で始まります(例:「# あなたのサイト名」)。慣例のそれ以外の要素はすべて任意です。タイトルがないと、パーサーは誰のファイルを読んでいるのか判断できません。
無料ツール · 登録不要
llms.txt を貼り付けるか、ドメインを入力してください。ファイルを取得し、llms.txt の慣例(タイトル、要約、セクション、リンクの説明、フォーマット、サイズ)に照らしてチェックします。合格・警告・不合格のスコア付きチェックリストと、見つかった各問題の修正方法が手に入ります。
llms.txt バリデーターは、サイトの llms.txt ファイルが提案されている規格に沿っているかどうかをチェックします。規格とは、markdown の H1 タイトル、任意の引用(blockquote)による要約、そして説明付きリンクをまとめた H2 セクションのことです。構造の欠落、markdown ではなく HTML であること、空のセクション、説明のない URL の羅列を検出し、AI エンジンが意図どおりにファイルを読めるようにします。
llms.txt の規格は、意図的に小さく作られています。ウェブのルートに置く markdown ファイルで、タイトル、任意の要約、説明付きリンクのセクションから 成ります。バリデーターはこれらのルールを一つずつチェックします。以下では、 それぞれが何であり、なぜ重要なのかを説明します。
ファイルは、サイトやプロジェクトの名前を記した単一の markdown H1 で始まります(例:「# あなたのサイト名」)。慣例のそれ以外の要素はすべて任意です。タイトルがないと、パーサーは誰のファイルを読んでいるのか判断できません。
「>」で始まる1行で、サイトが何であるかを述べます。任意ですが、AI エンジンがあなたを説明するときに引用する一文です。推測させるのではなく、自分で書きましょう。
「## Docs」「## Products」「## Guides」のようなセクションは、山積みのリンクを見て回れる索引に変えます。「## Optional」セクションは、読み取れる範囲が限られているときにエンジンが飛ばしてよいリンクを示します。
各リンクは「- [ページ名](url): 1行の説明」という形式のリスト項目です。索引を役立てるのは、この説明です。URL をただ羅列しても、どのページが何に答えるのかをエンジンには何も伝えられません。
ファイルは生の markdown テキストとして配信する必要があります。私たちが最もよく目にする失敗は、CMS やシングルページアプリが /llms.txt で HTML のフォールバックページを返すことです。ブラウザでは問題なく見えても、パーサーには読めません。
AI アシスタントは、限られたコンテキストの範囲内で llms.txt を読みます。最も重要なページを絞り込んだ、要点の詰まった短いリストは、網羅的な羅列に勝ります。数百キロバイトを超えると、ファイルの大部分は読まれることがありません。
上記のすべてのルールを、1つの短いファイルにまとめたものです。単一の H1、引用による要約、平易な文章の導入、グループ分けされたセクション、 そしてすべてのリンクに添えた説明。
# Acme Analytics > アーリーステージの SaaS チーム向けのプロダクト分析。イベントトラッキング、ファネル、リテンションレポートを、エンタープライズ価格なしで。 Acme Analytics は、創業者が初日からユーザー行動を理解できるよう支援します。 ## プロダクト - [機能](https://acme.example/features): イベントトラッキング、ファネル、コホート、リテンションレポート - [料金](https://acme.example/pricing): 無料からスケールまでのプラン、月額または年額 ## ガイド - [クイックスタート](https://acme.example/docs/quickstart): スニペットを設置し、5分で最初のイベントを確認 - [ファネル分析](https://acme.example/docs/funnels): コンバージョンファネルをステップごとに作成し、読み解く ## Optional - [変更履歴](https://acme.example/changelog): 毎週のプロダクトアップデート
まだ llms.txt をお持ちでないですか? サイトマップから数秒で生成してから、公開する前にここで検証しましょう。
無料 · チェック無制限 · 登録不要
What Meev is
Meev tracks where your brand appears across ChatGPT, Claude, Gemini, Perplexity, Grok, DeepSeek, Google AI Overviews, and Google AI Mode — then shows what to fix, publish, or pitch next to improve AI visibility.
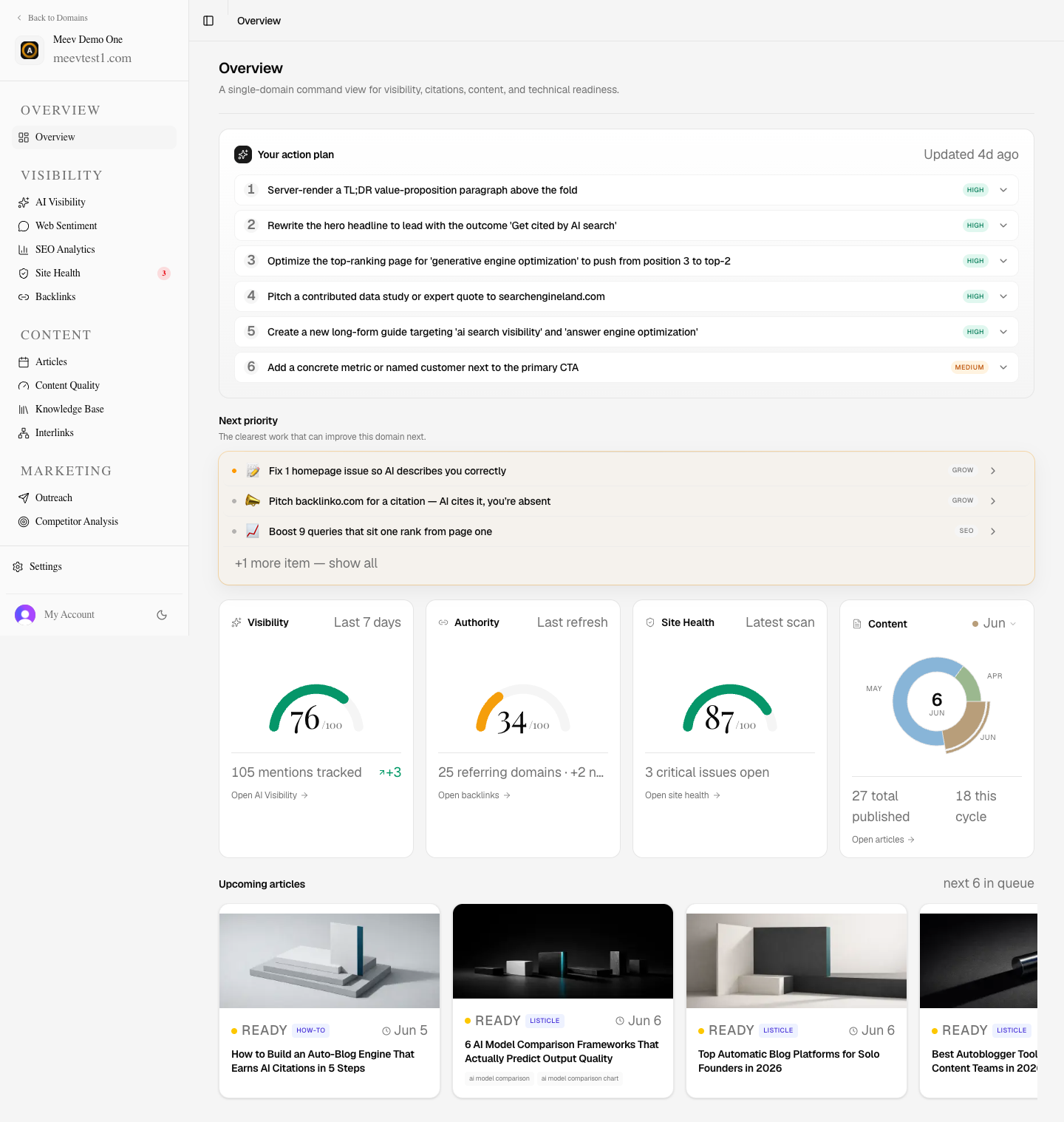











The path to getting cited
01 · Your domain
Meev reads your existing pages, topics, and Google Search Console signals to learn what your site is about and already ranks for: the foundation for every gap, draft, and citation that follows.
ステップ1
貼り付ける、または取得する
ファイルを直接貼り付けるか、ドメインを入力すれば /llms.txt を取得します。
ステップ2
構造を解析します
タイトル、要約、セクション、リンク、説明。AI エンジンが解析するのと同じ構造です。
ステップ3
スコア付きチェックリスト
各ルールに、合格・警告・不合格の判定と、わかりやすい説明が付きます。
ステップ4
修正して、もう一度実行
見つかった問題ごとに、何を変えればよいかが正確にわかります。公開し直し、もう一度検証して、きれいな状態で出せます。
llms.txt を読む AI エンジンは、それを構造で解析します。H1 で誰のファイルかを、引用でサイトが何をするかを、セクションでどのページが何に答えるかを判断します。その構造が壊れていると(そのパスで HTML ページが返される、タイトルがない、文脈のないリンクなど)、パーサーはサイトの誤った姿を読み取るか、何も言わずにあきらめてしまいます。エラーは出ません。あなたを誤って表すファイルを、ただ公開しただけになります。
llms.txt は単なる markdown なので、ほとんど何でも一見それらしく見えます。私たちが目にする失敗は、どれもありふれたものです。CMS が /llms.txt で HTML の 404 フォールバックを 200 ステータスとともに返す、サイトマップのエクスポートを数百件の URL の羅列として貼り付ける、セクション見出しの下に何もない、あるいは2つ目の H1 がファイルを2つに分断する、といったものです。どれもブラウザでは問題なく見えても、パーサーには壊れて読めます。だからこそ、目視で確認するよりも、実際の慣例に照らしてチェックする方が確実なのです。
llms.txt の提案が markdown の見出し、引用、リンクのリストを選んだのは、まさにそれらがきれいな解析木に対応するからです。プログラムによるツールは、自然言語を推測することなく、ファイルをタイトル、要約、セクションに分割できます。構造に従えば、llms.txt に対応するあらゆるツールがあなたのファイルを同じように読みます。そこからずれると、ツールごとに違った形で読み取りが劣化します。慣例に準拠すること、それこそが規格を採用する価値のすべてです。
Meev なら
整った llms.txt は、AI エンジンがあなたのページを見つける助けになります。Meev は、見つける価値のあるページをさらに増やします。品質ゲートを通過した記事を計画・執筆し、あなたのブログへ自動で公開したうえで、重要なクエリで AI エンジンが実際にあなたを引用しているかを追跡します。
llms.txt は提案されている規格です。robots.txt のようにドメインのルートに公開する、プレーンな markdown ファイルで、AI エンジンにサイトの厳選された概要を提供します。H1 タイトル、任意の引用による要約、そして最も重要なページを1行の説明とともに列挙した H2 セクションで構成されます。目的は、言語モデルがすべてをクロールしなくても、あなたのサイトを正確に理解し、引用できるようにすることです。
提案されている規格です。公開された仕様を持つ公共の慣例であり、W3C や IETF のような標準化団体によって承認されたものではありません。これは robots.txt がたどったのと同じ道です。robots.txt も、正式に標準化されるまでの数十年間はコミュニティの慣例として運用されていました。AI ツールやクローラーでの採用は広がっており、慣例に正確に従うことが、それを読むあらゆるものとの互換性を最大化します。
普及は広がりつつありますが、まだ全面的ではありません。多くの AI ツール、クローラー、回答エンジンがすでに llms.txt を読んでおり、この規格は現実の問題を解決するため勢いがあります。生の HTML は、言語モデルにとって効率の悪い形式だからです。適切な形式のファイルを公開してもコストはかからず、不利益もありません。ですから実際的な答えはこうです。公開し、有効な状態を保ち、普及が広がるにつれて恩恵を受けましょう。
llms.txt の慣例から導いた構造的なルールです。ファイルが HTML ではなく markdown であること、単一の H1 タイトルで始まること、タイトルの後に引用による要約が続くこと、H2 セクションがリンクを整理していること、空のセクションがないこと、リンクが URL の羅列ではなく markdown のリスト形式であること、リンクに1行の説明が付いていること、そしてファイルが AI アシスタントの読み取れる範囲に収まる簡潔さを保っていること。各ルールは、わかりやすい修正方法とともに合格・警告・不合格を返します。
たいていは完全には無視しません。ほとんどのパーサーは寛容で、読み取れるものは読み取ります。ただし、どれだけ抽出できるかは構造次第です。タイトルの欠落や、markdown ではなく HTML であるという失敗は、ファイル全体を読めなくしかねません。一方、説明の欠落のような警告は、有用性を下げるだけです。まずは不合格から直しましょう。それが、解析できるファイルとできないファイルの分かれ目です。
llms.txt は厳選された索引です。説明付きのリンクをまとめた短いファイルで、エンジンを重要なページへ導きます。llms-full.txt は任意の補完ファイルで、それらのページの全文を1つの大きな markdown ドキュメントに埋め込みます。すべてを一度の取得で得たいツール向けです。このバリデーターは索引ファイルをチェックします。両方を公開する場合、構造的に整っている必要があるのは索引の方です。
Meev は主要な AI 検索サーフェス全体であなたの可視性を追跡し、品質ゲートを通過した、引用されるコンテンツを自動で公開します。
7日間の無料トライアル。いつでもキャンセル可能。
AI Search
LLMs.txt Generator
Generate an llms.txt file so AI engines index your site correctly
AI Search
AI SEO Audit
Audit any page for AI-search readiness in 30 seconds
AI Search
Topical Map Generator
Map any site's content into topic clusters from its sitemap
AI Search
AI Crawler Simulator
See what GPTBot, ClaudeBot, and Googlebot see on your page
AI Search
Query Fan-Out Generator
Turn one query into 25+ AI-search variations, grouped by intent
AI Search
Page Token Inspector
See your page the way an AI engine reads it — token by token