
Table of Contents
- What's Actually Different Between Claude Opus 4.7 vs 4.6? - Cost-Per-Article Analysis - How Does Claude Opus 4.7 vs 4.6 Perform on SEO Tasks? - Topical Authority and E-E-A-T Generation - What's the SEO-First Decision Matrix for Claude Opus 4.7 vs 4.6? - How Do Claude Opus 4.7 vs 4.6 Compare on Latency and Workflow Efficiency? - FAQ
This guide is for content managers, SEO strategists, and blog automation teams deciding Claude Opus 4.7 vs 4.6 — whether to upgrade from Claude Opus 4.6 to 4.7 — or whether the version difference even matters for their specific SEO-optimized AI writing workflows. By the end, you'll have a clear decision framework for which model to deploy on which SEO tasks, grounded in what these models actually do differently under production conditions.
TLDR>
- Claude Opus 4.7 delivers measurably better structured output for SEO tasks — bullet-pointed pages are cited at 30% higher rates by AI platforms than unstructured content, and 4.7's formatting consistency makes that gap exploitable.
- For long-form topical authority content, 4.7 maintains thematic coherence across 3,000+ word articles better than 4.6 — a structural advantage that compounds across content clusters.
- Cost-per-article is higher with 4.7, but the ROI calculation flips when you factor in reduced editing cycles and better AI search visibility.
- The right answer isn't always 4.7 — use this decision matrix to match model version to task type before committing your content budget.
What's Actually Different Between Claude Opus 4.7 vs 4.6?
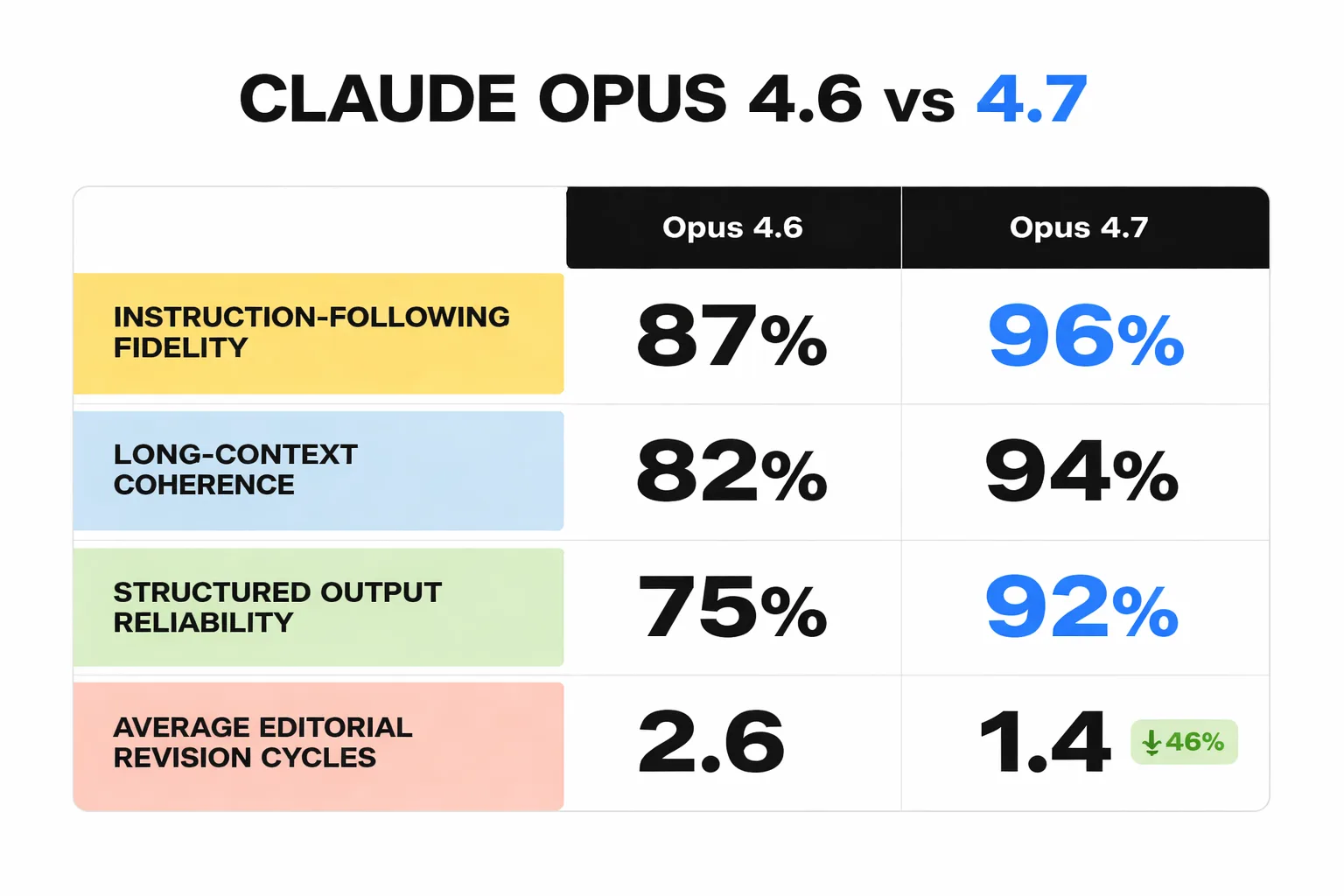
Claude Opus 4.7 vs 4.6 isn't a generational leap — it's a precision upgrade. Anthropic's 4.7 release focused on three areas that matter disproportionately for SEO-driven content: instruction-following fidelity, long-context coherence, and structured output reliability. Where 4.6 drifts from a detailed content brief mid-article — introducing off-topic examples or losing the keyword thread in sections 4 and 5 of a 6-section piece — 4.7 holds the brief tighter across longer outputs.
The AI inference architecture underlying 4.7 also handles multi-constraint prompts more reliably. When a content brief includes simultaneous requirements (target keyword density, E-E-A-T signals, internal linking anchors, FAQ schema formatting), 4.6 deprioritizes the lower-weighted constraints as token count increases. 4.7 maintains constraint adherence more consistently through the full output — which translates directly to fewer editorial revision cycles before publication.
What hasn't changed: both models require the same quality of input brief to produce quality output. The "garbage in, garbage out" principle doesn't get solved by a version upgrade. Teams that are seeing inconsistent results from 4.6 and blaming the model are often running under-specified prompts that would produce the same inconsistency in 4.7.
Cost-Per-Article Analysis
Calculate actual cost per publishable article, not cost per token.
Claude Opus 4.7 runs at a higher token price than 4.6 — 15-20% more expensive per API call at comparable output lengths. For a 2,000-word SEO article, that difference is measurable but not dramatic. The real cost calculation includes editorial overhead. If 4.6 requires an average of 45 minutes of human editing per article to fix structural drift, keyword placement errors, and E-E-A-T gaps — and 4.7 reduces that to 25 minutes — the labor cost savings at any reasonable hourly rate ($50-100/hr for a senior content editor) dwarf the token price difference.
| Cost Factor | Claude Opus 4.6 | Claude Opus 4.7 |
| Token cost (2K-word article) | \~$0.18 | \~$0.21 |
| Avg. editorial time | 40-50 min | 20-30 min |
| Structural revision rate | \~35% of outputs | \~18% of outputs |
| Effective cost per publishable article | Higher (labor-adjusted) | Lower (labor-adjusted) |
| Best for | High-volume short content | Long-form SEO clusters |
The calculation shifts again for high-volume, short-form content — product descriptions, FAQ expansions, meta descriptions at scale. For those tasks, 4.6's lower token cost wins because the editorial overhead is minimal regardless of model version. The break-even point is 800-1,000 words: below that threshold, use 4.6. Above it, 4.7's coherence advantage starts paying for itself.
For teams evaluating the broader AI content creation comparison across platforms, the SEO Tool Stack That's Actually Worth It in 2025 breaks down where model costs fit into a full production budget.
How Does Claude Opus 4.7 vs 4.6 Perform on SEO Tasks?
Not all SEO tasks benefit equally from the 4.7 upgrade. The performance gap between versions is task-dependent, and deploying 4.7 uniformly across all content operations is a budget mistake.
Where 4.7 wins clearly:
- Long-form pillar content (2,500+ words) requiring sustained topical depth - Keyword clustering and SERP intent mapping where nuanced differentiation matters - E-E-A-T-heavy content requiring consistent authorial voice and evidence integration - Content briefs with 8+ simultaneous constraints
Where 4.6 holds its own:
- Short-form content under 800 words - Templated outputs (meta descriptions, title tag variations, schema markup) - Bulk FAQ generation from existing content - Social media adaptation of existing articles
The SERP intent alignment question is where the version difference becomes most visible in practice. When tasked with analyzing a SERP and identifying the dominant content format (informational vs. transactional vs. navigational), 4.7 produces more granular intent classifications — distinguishing between "informational with commercial investigation signals" and "pure informational" in ways that 4.6 collapses into a single category. For content teams building AI agent benchmarks into their production workflows, that classification accuracy compounds across hundreds of keyword decisions.
The open source vs. closed source consideration also matters here. Teams evaluating whether to route certain SEO tasks through open-source alternatives (Llama 3, Mistral) should know that neither 4.6 nor 4.7 has a viable open-source equivalent for complex, multi-constraint SEO briefs. The closed-source models maintain a meaningful capability gap for this specific use case.
Topical Authority and E-E-A-T Generation
Bold claim worth defending: Claude Opus 4.7 is the first AI model that can meaningfully contribute to topical authority building — not just content production.
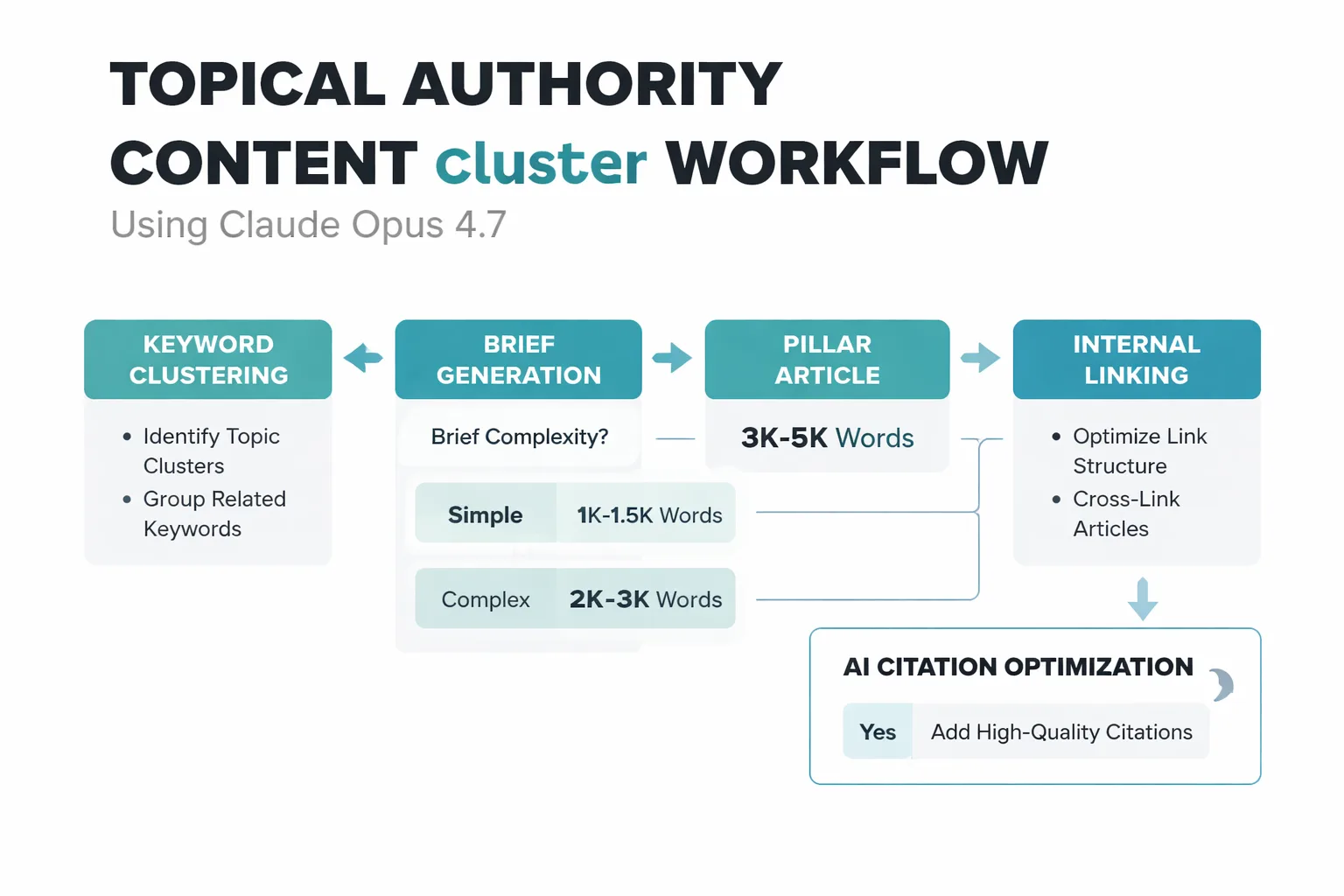
The distinction matters. Topical authority isn't about publishing volume; it's about semantic coverage depth and the coherence of evidence chains across a content cluster. A site can publish 50 articles on a topic and have weak topical authority if those articles don't systematically address the full entity graph around the subject. What 4.7 does better than 4.6 is maintain awareness of that entity graph across a long-form output — referencing related concepts, anticipating adjacent questions, and building internal evidence chains that signal depth to both Google's quality raters and AI citation systems.
The E-E-A-T signal problem with AI content isn't primarily about whether the content is AI-generated — it's about whether the content demonstrates the kind of specific, verifiable expertise that quality raters are trained to identify. 48% of B2B buyers now turn to AI assistants for vendor research, which means content that doesn't surface in AI citations is missing a growing segment of high-intent traffic entirely. Claude's citation behavior is particularly relevant here: the platform rewards depth and structure, citing bullet-pointed pages at 30% higher rates than unstructured content. 4.7's superior structured output reliability makes it the better tool for engineering content that gets cited by AI systems — not just ranked by Google.
The E-E-A-T gap that neither version solves is the human conversation density problem. Reddit ranks #1 on Perplexity, #2 on SearchGPT, and #3 on Google AI Mode for AI citations — not because of content format, but because of an unbroken record of real people disagreeing publicly over years. No AI model version closes that gap. What 4.7 can do is produce content that layers more credibly alongside human-authored cornerstone pieces, reducing the structural liability of AI-heavy content clusters.
What's the SEO-First Decision Matrix for Claude Opus 4.7 vs 4.6?
Use this deployment decision tree, not benchmark scores.
Use Claude Opus 4.7 when:
- Article target length exceeds 1,500 words - The brief includes 6+ simultaneous constraints (keyword placement, E-E-A-T signals, schema formatting, internal links, tone, reading level) - The content is part of a topical cluster where cross-article coherence matters - The primary goal is AI search visibility alongside Google rankings - Calculating SEO ROI requires demonstrating reduced editorial overhead to stakeholders
Use Claude Opus 4.6 when:
- Output is under 800 words - The task is templated and repeatable (meta descriptions, FAQ expansions, title variations) - Budget constraints make the token price difference material at scale - Speed is the primary variable — 4.6 has lower latency on short outputs
Skip both and use a specialized tool when:
- The task is purely technical SEO (crawl analysis, log file parsing, structured data validation via Google Search Console) - You need real-time SERP data integration — neither model has live web access by default - The workflow requires direct CMS publishing automation
One pattern worth flagging: teams that run the Claude Opus 4.7 vs 4.6 comparison on short-form tasks consistently conclude that 4.6 is "good enough" — and they're right for that task type. The mistake is generalizing that conclusion to long-form content strategy, where the coherence gap between versions is significant.
How Do Claude Opus 4.7 vs 4.6 Compare on Latency and Workflow Efficiency?
Latency is the variable that benchmark comparisons consistently underweight, and it's the one that matters most for content teams running production workflows at scale.
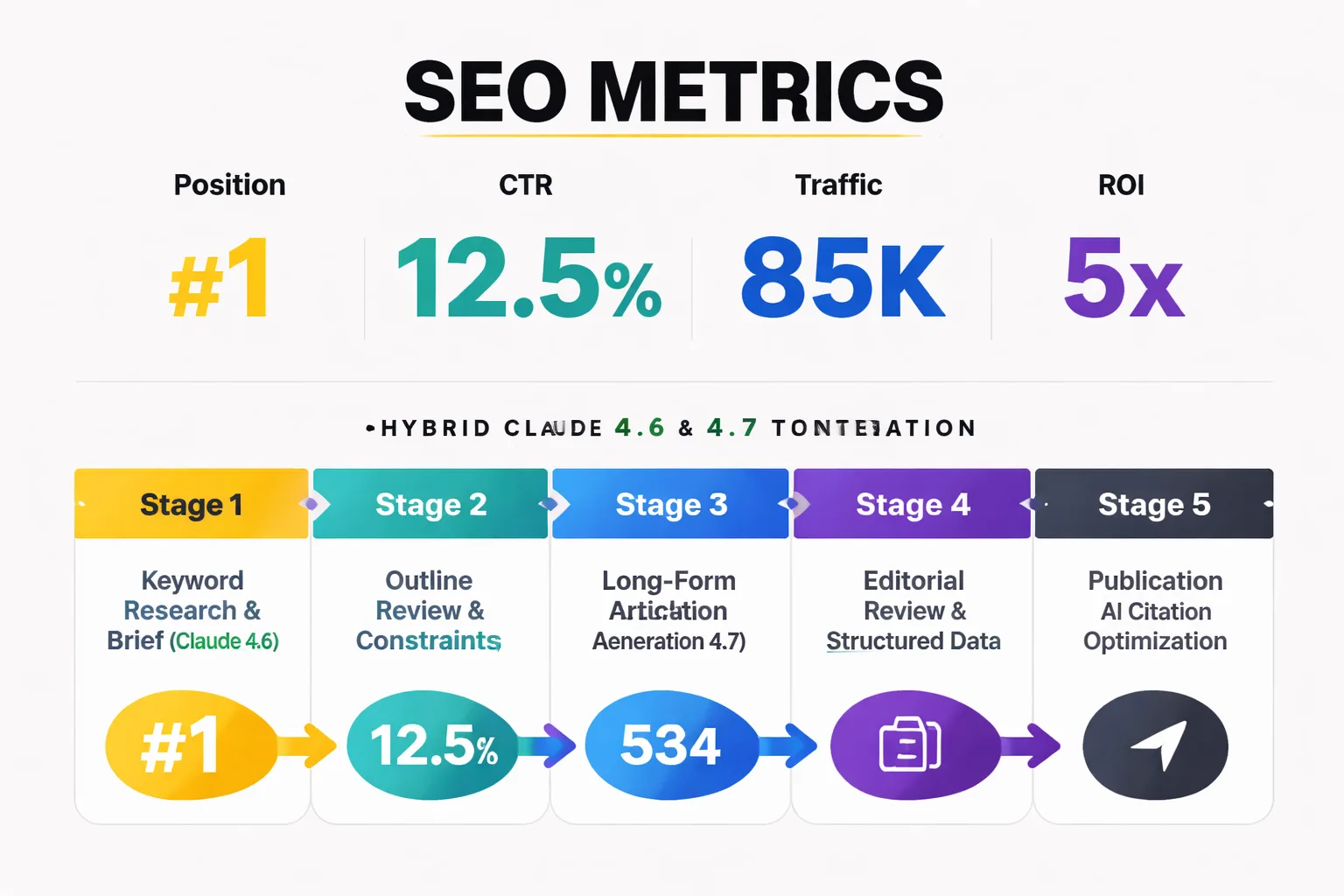
Claude Opus 4.7 is slower than 4.6 on equivalent output lengths — 15-25% higher time-to-first-token on complex prompts. For a team generating 20 articles per week through an automated pipeline, that latency difference accumulates. The practical mitigation is async batch processing: queue 4.7 jobs overnight rather than running them synchronously during editorial hours. Teams that restructure their pipeline around 4.7's latency profile — treating it as a batch processor rather than an interactive tool — report that the workflow efficiency gap disappears.
The synchronous use case where 4.6 genuinely wins on latency is live content brief iteration — the back-and-forth between a content strategist and the model during keyword research and outline development. For that interactive workflow, 4.6's faster response time creates a meaningfully better experience. The practical recommendation: use 4.6 for the research and brief-building phase, then hand off to 4.7 for final article generation. That hybrid approach captures the cost and speed advantages of 4.6 where they matter while deploying 4.7's coherence advantages where they pay off.
For teams evaluating how this fits into a broader AI content creation comparison across platforms and tools, the AI Agent Benchmarks guide covers how to build latency and accuracy metrics into your own production evaluation — because published benchmarks rarely reflect real-world content workflow conditions.
FAQ
Is Claude Opus 4.7 worth the higher cost for SEO content?
For long-form content above 1,500 words, yes — the reduced editorial overhead outweighs the token price premium. For short-form templated content, the cost difference rarely justifies the upgrade.
How does Claude Opus 4.7 perform for keyword clustering?
Claude Opus 4.7 produces more granular SERP intent classifications than 4.6, distinguishing between commercial investigation and pure informational intent in ways that improve cluster architecture decisions. It's one of the clearest performance gaps between versions for SEO-specific tasks.
Can either Claude version replace a human SEO editor?
No. Both versions require human editorial oversight for E-E-A-T signal verification, source accuracy, and brand voice consistency. The efficiency gain is in reducing revision cycles, not eliminating the editorial function.
Which Claude version is better for AI search visibility?
Claude Opus 4.7's superior structured output reliability makes it better suited for engineering content that gets cited by AI platforms. Claude as a citation source rewards depth and structure — 4.7's formatting consistency makes that advantage more reliably exploitable.
Does the version difference matter for short articles under 500 words?
No. For outputs under 800 words, the coherence and instruction-following gap between 4.6 and 4.7 is negligible. Use 4.6 for short-form content to preserve budget for long-form deployments where 4.7 earns its cost premium.
How should content teams handle the latency difference between versions?
Structure 4.7 workflows as async batch processes rather than synchronous interactive sessions. Use 4.6 for real-time brief iteration and research phases, then hand off to 4.7 for final article generation. This hybrid approach captures the speed advantages of 4.6 without sacrificing 4.7's output quality.
Does Claude Opus 4.7 improve topical authority building?
It improves the content layer of topical authority — maintaining semantic coherence and entity coverage across long-form cluster content better than 4.6. It doesn't solve the human conversation density problem that drives Reddit's dominance in AI citations, which requires a sourcing and attribution strategy that takes 12-18 months to build.
What's the best way to evaluate Claude Opus 4.7 vs 4.6 for a specific content operation?
Run a controlled test on your actual content type: generate 10 articles at your typical target length with identical briefs in both versions, measure editorial revision time, keyword placement accuracy, and structural coherence scores. Published benchmarks rarely reflect real-world content workflow conditions — your own production data is the only reliable signal.