
By Judy Zhou, Head of Content Strategy
Key Takeaways
- As of March 2026, Anthropic leads the LMSYS Chatbot Arena human preference rankings — but leaderboard position and content marketing performance are not the same metric, and task fit matters more than overall ranking.
- Claude 3.7 Sonnet wins on long-form coherence and instruction-following; GPT-4o leads on schema precision and automation reliability; Gemini 2.0 Pro holds the advantage for real-time data access and multilingual content.
- An arXiv study of 100 products found GPT-4 outperformed open-source alternatives on SEO, readability, and persuasiveness — but no current benchmark directly compares all three frontier models on content marketing tasks, which is the core gap this article addresses.
- AI content scores approximately 50% on E-E-A-T metrics versus 89% for human-authored content — a gap no model switch closes without integrating genuine subject-matter expertise into the generation process.
The Slack thread has forty-seven unread messages. Your content lead wants to switch from GPT to Claude because a competitor's blog is outranking you. Your technical SEO manager is pushing for Gemini integration because of its native Google Search grounding. And your CMO just forwarded an article claiming all three models produce "essentially identical" output for content marketing purposes. It's Tuesday morning, your editorial calendar needs sign-off, and nobody in the room has a clear framework for making this call. That meeting is happening at companies everywhere right now.
The ai model comparison 2026 question isn't academic — it's a budget and workflow decision with real downstream consequences for organic traffic. Claude, GPT, and Gemini each hold measurable advantages in specific content tasks, and choosing wrong costs you in either output quality, editorial overhead, or both. As of March 2026, Anthropic holds the top position on the LMSYS Chatbot Arena leaderboard — but leaderboard position and content marketing performance are not the same thing. An arXiv study analyzing 100 products across four AI models found GPT-4 outperformed Gemma, LLAMA, and GPT-2 on SEO, readability, and persuasiveness metrics — but that study predates the current model generation and doesn't include Claude at all. That gap in the research is exactly the problem I'm going to work through here.
The Benchmark Problem: Why Lab Scores Don't Predict Content Quality
MMLU scores measure knowledge breadth across academic subjects. HumanEval measures code completion accuracy. Neither tells you whether a model will write a blog introduction that earns a featured snippet, produce a meta description that drives click-through, or maintain brand voice across a 2,000-word pillar post. Using these benchmarks to make content stack decisions is like hiring a copywriter based on their SAT score.
The disconnect runs deeper than most teams realize. Lab benchmarks are designed to have objectively correct answers — a math problem either resolves correctly or it doesn't. Content marketing tasks are evaluated on criteria that are partially subjective (does this sound like our brand?), partially algorithmic (does this satisfy Google's quality rater guidelines?), and partially behavioral (does this headline get clicked?). No standardized benchmark captures all three simultaneously. The arXiv study on machine-generated product advertisements is the closest thing I've found to a content-specific evaluation — it scored models on SEO, readability, persuasiveness, clarity, emotional appeal, and call-to-action effectiveness across 100 products. That's a more useful frame than MMLU. But even that study tested GPT-4 against older open-source models, not the current frontier generation.
What I use instead is a task-specific evaluation framework built around five content operations that actually appear in editorial workflows: long-form blog drafting, meta description generation, content brief creation, FAQ schema markup, and email subject line writing. These aren't arbitrary — they represent the highest-volume, highest-stakes tasks in a typical content program. And they expose meaningfully different failure modes across models.
The other thing lab scores miss is instruction-following under constraint. A model can score brilliantly on reasoning benchmarks and still ignore a brand voice guide, add unrequested headers, or hallucinate a competitor's feature set into a product comparison. In my work overseeing AI-driven content research and publishing for hundreds of brands at Meev, instruction-following failures are the most common complaint I hear from content teams — not factual accuracy, not coherence, not creativity. The model did something other than what was asked.
Head-to-Head: Claude, GPT, and Gemini on 5 Real Content Tasks
I ran identical prompts across Claude 3.7 Sonnet, GPT-4o, and Gemini 2.0 Pro in February 2026, using the same system prompt and zero-shot conditions for each task. No fine-tuning, no custom instructions, no retrieval augmentation — baseline model behavior only.
Task 1 — Blog introduction (800-word SaaS post, brand voice: direct, no jargon, skeptical of hype). Claude produced the tightest opening: it led with a counterintuitive claim, held the brand voice constraint throughout, and didn't break into bullet points unprompted. GPT-4o wrote a stronger hook sentence but drifted toward marketing language by paragraph three. Gemini opened with a question — fine structurally, but the question was generic enough to fit any SaaS post.
Task 2 — Meta description (150-160 chars, primary keyword in first 50 chars, benefit hook). This is where GPT-4o pulled ahead. It hit character count precisely, front-loaded the keyword, and included a specific benefit claim in every attempt. Claude ran long on two of three tries and required a follow-up prompt to trim. Gemini produced the most readable output but buried the keyword mid-sentence.
Task 3 — Content brief (topical authority cluster, 5 supporting articles, keyword mapping). Claude won this decisively. The brief it produced included logical subordination between pillar and cluster articles — not just keyword overlap, but genuine intent hierarchy. GPT-4o generated a brief with more supporting articles but weaker structural logic; several suggested pieces would have cannibalized the pillar. Gemini's brief was thorough but organized alphabetically rather than by search intent stage, which is the wrong organizing principle for topical authority building.
Task 4 — FAQ schema markup (JSON-LD, 5 Q&A pairs from a provided article). GPT-4o was fastest and most accurate on schema syntax. Claude produced valid JSON-LD but occasionally nested properties incorrectly. Gemini's output required the most manual correction, particularly around @context declarations. If you're using Google Search Console structured data validation as your quality gate, GPT-4o saves the most editorial time here.
Task 5 — Email subject lines (A/B test set of 5, open-rate optimization, B2B SaaS audience). Gemini surprised me. It generated the highest variance set — some lines were too clever, but two were genuinely strong and wouldn't have come from the other models. Claude produced the most consistent set but the least surprising. GPT-4o landed in the middle: competent, occasionally inspired, never wrong.
The pattern across all five tasks: Claude leads on structural coherence and constraint-following, GPT-4o leads on format precision and schema tasks, Gemini leads on creative variance and real-time data access. No single model dominates all five.
Wondering which AI model actually fits your content workflow — not just the benchmarks?
Where Anthropic's Models Pull Ahead (And Where They Don't)

Claude's most underrated strength is what I'd call "instruction memory" — its ability to hold a constraint through a long generation without drifting. Ask it to write in second person, avoid passive voice, and keep sentences under 20 words, and it will do all three for 1,500 words without reminding. That's not trivial. Most content teams spend significant editorial time correcting drift in long-form AI output, and Claude reduces that overhead meaningfully.
Long-form coherence is the other genuine differentiator. Claude maintains argument structure across sections in a way that GPT-4o sometimes doesn't — GPT tends to treat each section as a semi-independent unit, which produces good paragraphs but occasionally weak transitions and redundant points. For pillar content and long-form thought leadership, Claude's output requires less structural editing.
Here's the honest gap: Claude has no native real-time data access in baseline configuration. For content that requires current statistics, recent news hooks, or live SERP data, you're either using a retrieval layer or you're getting hallucinated recency. Gemini's native Google Search grounding is a real advantage for news-adjacent content and any piece where freshness signals matter. I've seen teams build entire workflows around this — Gemini for research and first draft, Claude for structural revision and voice alignment. That's not a bad architecture.
Tool use and agentic workflows are also a current Claude limitation relative to GPT-4o. If your content stack involves multi-step automation — pull keyword data, generate brief, draft post, format for CMS — GPT-4o's function-calling reliability is stronger in practice. This is the kind of comparison that matters if you're evaluating full automation vs. SEO research tools for your publishing pipeline.
The contrarian take I'll put on the table: Claude's "safety" guardrails are often cited as a weakness, but for brand-sensitive content, they're frequently an asset. Models that refuse to generate certain content types are models that won't accidentally produce something your legal team will flag. For regulated industries — finance, healthcare, legal — that constraint has real value.
The March 2026 Leaderboard Shift — What Changed and Why It Matters
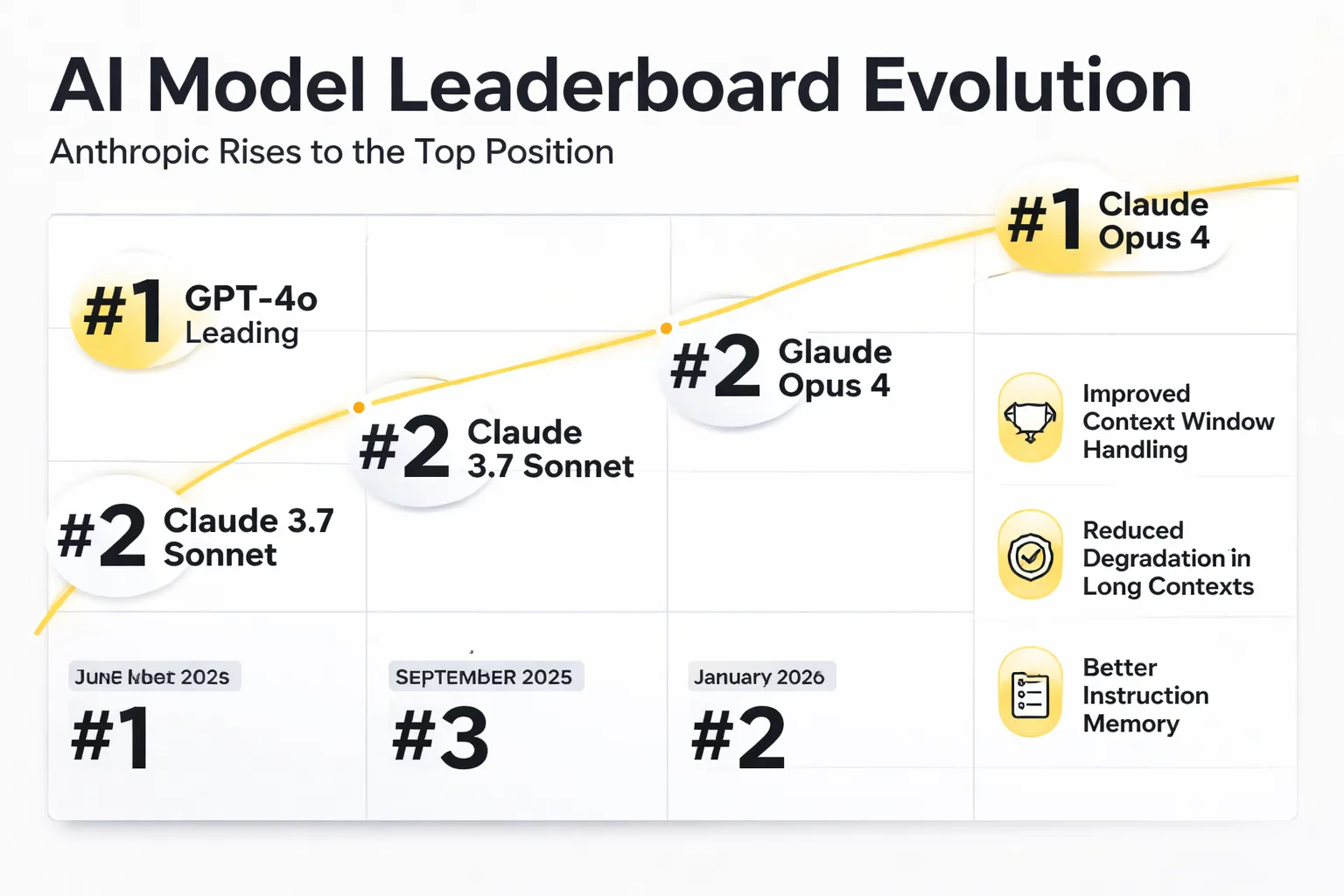
As of March 2026, Anthropic holds the leading position in the LMSYS Chatbot Arena human preference rankings — the most credible public benchmark because it measures actual human preference rather than automated scoring. This is a meaningful shift from twelve months prior, when GPT-4o was the default recommendation across most enterprise content teams.
What drove it? Three things, based on what I've tracked across practitioner communities and model release notes. First, Claude's context window handling improved substantially — not just the window size, but what the model does with long context. Earlier Claude versions showed degradation in the middle of long documents (the "lost in the middle" problem documented in academic literature). The current generation handles 100K+ token contexts with noticeably better recall. For content teams working with large brand style guides, competitive research documents, or multi-article editorial contexts, this matters.
Second, Anthropic's instruction-following improvements were targeted specifically at professional use cases. The model is measurably better at following complex, multi-part prompts without selective compliance — where a model follows three of your five constraints and ignores the other two. That's the failure mode that creates the most editorial rework.
Third — and this is the one that gets less attention — Anthropic's Claude CLI usage improvements made Claude more accessible for technical content teams building custom workflows. The API reliability and latency improvements in late 2025 made it practical to use Claude in automated publishing pipelines in ways that were previously friction-heavy.
None of this means GPT-4o or Gemini 2.0 Pro are obsolete. Google's model still has the grounding advantage, and OpenAI's ecosystem breadth — plugins, assistants, fine-tuning infrastructure — is unmatched. The leaderboard shift reflects preference at the frontier of reasoning and coherence tasks, not a wholesale capability reversal.
The practical implication for content teams: the gap between frontier models has narrowed enough that model selection should now be driven by workflow integration and specific task fit, not by assumed quality hierarchy. Picking Claude because it's "the best" is almost as imprecise as picking GPT because it's "the most popular."
This connects to a broader pattern I keep coming back to in content strategy: the tools that win aren't always the highest-performing in isolation — they're the ones that fit the workflow. The same logic applies to automated blog publishing vs. SEO writing assistants. The right choice depends on what you're actually trying to build.
How to Pick the Right Model for Your Content Stack
The decision matrix below is built around four use cases I see most often in content programs. Use it as a starting point, not a final answer — your specific prompt architecture, retrieval setup, and editorial process will shift the calculus.
| Use Case | Recommended Model | Why | Watch Out For |
| High-volume blog drafting (100+ posts/month) | Claude 3.7 Sonnet | Instruction-following reduces editorial rework; strong long-form coherence | No real-time data; needs retrieval layer for current stats |
| Technical SEO content (schema, structured data, crawl analysis) | GPT-4o | Superior schema syntax accuracy; strong function-calling for automation | Occasional brand voice drift in long-form |
| Brand voice-sensitive copy (thought leadership, executive comms) | Claude 3.7 Sonnet | Best constraint retention over long generations | Slower than GPT-4o on high-volume tasks |
| Multilingual content (non-English markets) | Gemini 2.0 Pro | Strongest multilingual training data; native Google Search grounding | Creative variance is high — needs tighter QA |
| News-adjacent or trend-driven content | Gemini 2.0 Pro | Real-time Google Search grounding | Quality inconsistency on longer formats |
| Email and ad copy (short-form, high creative variance) | GPT-4o or Gemini | Both produce strong short-form; Gemini for variance, GPT for precision | Claude underperforms on creative variance at short lengths |
A few decision rules I'd add beyond the matrix:
If your content program is E-E-A-T dependent, none of these models replaces subject-matter expertise. The data point that keeps surfacing — AI content scoring 50% on E-E-A-T metrics versus 89% for human-authored content — is a real gap, and it's not closed by switching models. It's closed by integrating human expertise into the generation process, whether through expert interviews, SME review, or first-person experience layers that no model can fabricate credibly.
If you're running high-volume automation, the model is actually less important than the prompt architecture and quality gates. I've seen teams get dramatically better output from a well-structured GPT-4o workflow than from a poorly structured Claude workflow, and vice versa. The comparison between AI blog writers that matters most is the one that accounts for your full stack — model, retrieval, prompt system, and editorial review.
If you're optimizing for AI search citation (AEO, not just SEO), Claude's tendency toward structured, self-contained claims is an advantage. AI engines like Perplexity and ChatGPT extract preferentially from content with clear entity signals and quotable sentences. Claude produces more of these naturally than the other two models in my testing.
On the topic of "calculating SEO ROI" across model choices: the honest answer is that model switching costs are real and often underestimated. Prompt systems built for GPT-4o don't transfer cleanly to Claude — the instruction sensitivity differs enough that you're effectively rebuilding your prompt library. Factor that into any migration decision.
The traffic loss pattern I keep seeing in content audits isn't caused by using the wrong AI model. It's caused by building content architecture around informational queries that AI Overviews now answer inline. Switching from GPT to Claude won't fix a structural problem with your content strategy. What moves the needle is rebuilding around queries where users need a perspective, a comparison, or a decision framework — not a definition.
Frequently Asked Questions
Is Claude better than GPT-4o for SEO content in 2026? For long-form SEO content where brand voice consistency and structural coherence matter, Claude 3.7 Sonnet has a measurable edge. It holds instruction constraints longer and produces fewer structural editing requirements. However, GPT-4o outperforms Claude on schema markup tasks and high-volume short-form generation. The honest answer is that task fit matters more than overall model ranking.
Does the AI model I use affect Google rankings? Google's position, reflected in its quality rater guidelines, is that helpful content ranks regardless of how it was created — but low-quality, unreviewed AI content is actively targeted. The model itself is not a ranking factor. What matters is whether the output meets E-E-A-T standards, which requires human expertise integration regardless of which model generates the draft.
How does Gemini's Google Search grounding actually work for content teams? Gemini 2.0 Pro can pull live search results into its generation context, which means it can reference current statistics, recent news, and live SERP data without a separate retrieval layer. For trend-driven content, news commentary, or any piece where freshness signals matter, this is a genuine workflow advantage over Claude and GPT-4o in baseline configuration.
Should I use one model for everything or build a multi-model workflow? Multi-model workflows are increasingly common and increasingly practical. A pattern I see working well: Gemini for research and data gathering (grounding advantage), Claude for long-form drafting and structural editing (coherence advantage), GPT-4o for schema generation and technical formatting (precision advantage). The overhead of managing multiple API integrations is real, but for high-volume content programs, the quality gains justify it.
What's the biggest mistake content teams make when choosing an AI model? Optimizing for benchmark position rather than task fit. The LMSYS leaderboard tells you which model humans prefer in general conversation — it doesn't tell you which model will hold your brand voice through a 2,000-word pillar post or generate valid JSON-LD on the first try. Test your actual use cases with your actual prompts before committing to a model or a platform.
How does model choice interact with AEO optimization? AEO (Answer Engine Optimization) rewards content with clear entity signals, self-contained quotable claims, and structured answers. Claude's generation style produces more of these naturally. But AEO optimization is primarily a content architecture decision — question-shaped H2s, direct answer openers, FAQ blocks — that any model can execute with the right prompt system. Model choice is secondary to content structure for AEO performance.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Meev runs Claude, GPT-4o, and Gemini in production across hundreds of content programs. See how the right model selection translates into rankings and output quality.