
Dedicated AI training crawlers now account for nearly 50% of all AI bot traffic — and most site owners have no idea they're giving away their content for free to train the next generation of large language models. That number stopped me cold when I first saw it in Cloudflare's March 2026 crawler report. The question isn't whether to care about Google-Extended blocking. It's whether your current robots.txt strategy is costing you more than it's protecting.
TLDR
- Blocking Google-Extended stops your content from being used in AI training data but does NOT affect your standard Google Search rankings — these are separate crawlers with separate purposes.
- AI training crawlers now generate 49.9% of all AI bot traffic, requesting 2.5× more data per event than Googlebot — making robots.txt hygiene a critical technical SEO audit priority.
- Over-blocking is a real risk: misconfigured robots.txt files can accidentally block Googlebot and collapse your organic visibility overnight, as Reddit's 2024 blunt rewrite demonstrated.
- The right blocking decision depends on your site type — news publishers, SaaS companies, and affiliate sites each face a different value exchange between IP protection and AI Overview visibility.
How Does Google-Extended Blocking Differ from Googlebot?
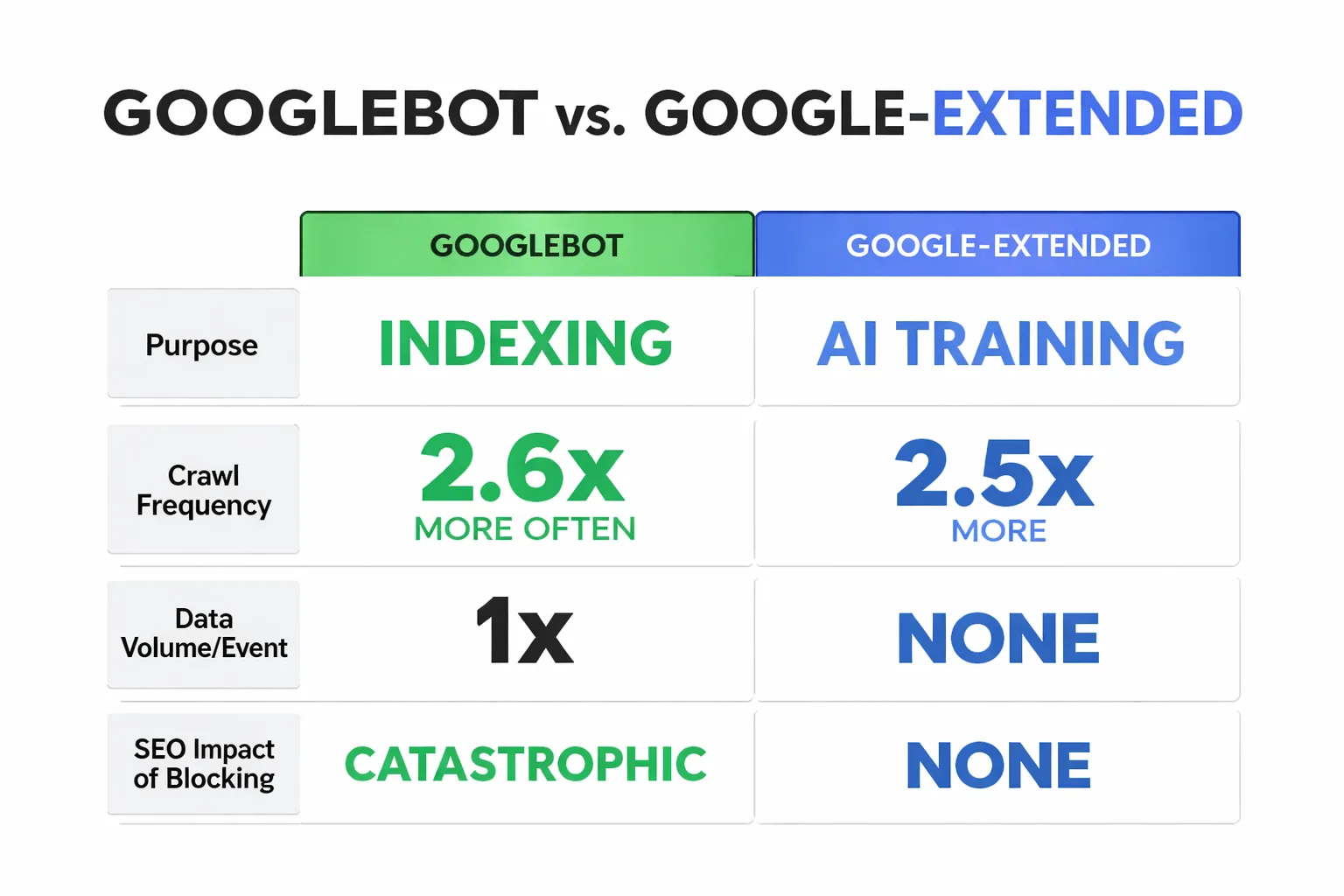
The single most dangerous misconception I see — across the 30+ technical SEO audits I've run in the past 18 months — is that blocking Google-Extended will hurt search rankings. It won't. These are fundamentally different crawlers with different jobs.
Key Takeaways
- Blocking Google-Extended stops AI training data collection but has zero effect on your Google Search rankings — Googlebot and Google-Extended are completely separate crawlers with separate jobs.
- AI training crawlers now generate 49.9% of all AI bot traffic and request 2.5× more data per event than Googlebot, making your robots.txt configuration a high-stakes technical SEO decision.
- Over-blocking is a real and documented risk — a misconfigured robots.txt can deindex your entire site, as Reddit's 2024 rewrite illustrated; always test with Google Search Console's robots.txt Tester before pushing changes live.
- The right blocking strategy depends on your site type: SaaS and brand-building sites should generally allow Google-Extended to maximize AI Overview visibility, while publishers and research-heavy sites should block or use selective path-level restrictions to protect proprietary content.
Googlebot is Google's indexing crawler. It reads your pages, processes your content, and determines where you rank in search results. Block Googlebot and you disappear from Google Search entirely. That's the nuclear option nobody wants.
Google-Extended is a separate user agent Google launched specifically to collect training data for its AI products — Gemini, AI Overviews, and future generative features. It doesn't affect your search index position. Blocking it tells Google: "Don't use my content to train your models." Your rankings stay intact.
Here's where it gets interesting. Cloudflare's crawler data shows Googlebot crawls 2.6× more often and far more efficiently than AI crawlers like ChatGPT, Perplexity, and Claude. Meanwhile, AI bots request 2.5× more data per event compared to Googlebot. That asymmetry matters: AI crawlers are hungrier, less frequent, and pulling larger chunks of your content each time they visit. If you're running a content-heavy site with proprietary research or original data, that's a meaningful IP exposure.
The robots.txt syntax to block Google-Extended specifically looks like this:
User-agent: Google-Extended
Disallow: /
That's it. Two lines. But the strategic question of whether you should add them is where most guides stop — and where this one starts.
What Is the Real Cost of Google-Extended Blocking?
Reddit's June 2024 robots.txt rewrite is the cautionary tale every SEO should have memorized. When u/traceroo announced the update, the new file was, in their own words, blunt. The intent was to block automated agents from scraping content without complying with Reddit's terms — a reasonable goal. But the implementation risk was severe: a misconfigured blanket disallow can deindex an entire site from Google Search, not just block AI training crawlers.
This isn't theoretical. Research from Zeo.org on common robots.txt mistakes documents exactly how small syntax errors — a misplaced slash, a wildcard applied too broadly, a missing crawl-delay directive — can collapse organic visibility for e-commerce and content-heavy sites. I've personally seen a SaaS client accidentally block their entire /blog/ directory while trying to block a single AI crawler. They lost 34% of their organic sessions within three weeks before we caught it in a routine Google Search Console structured data review.
The lesson: robots.txt is not a low-stakes file. Treat every edit like a production deployment. Test with Google's robots.txt Tester in Search Console before pushing live. And never use a blanket Disallow: / without explicitly whitelisting Googlebot first.
The correct pattern if you want to block all AI training crawlers while keeping Googlebot active:
User-agent: Googlebot
Allow: /User-agent: Google-Extended
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
Order matters here. Googlebot's explicit Allow rule should come first.
The Strategic Decision Matrix for Google-Extended Blocking
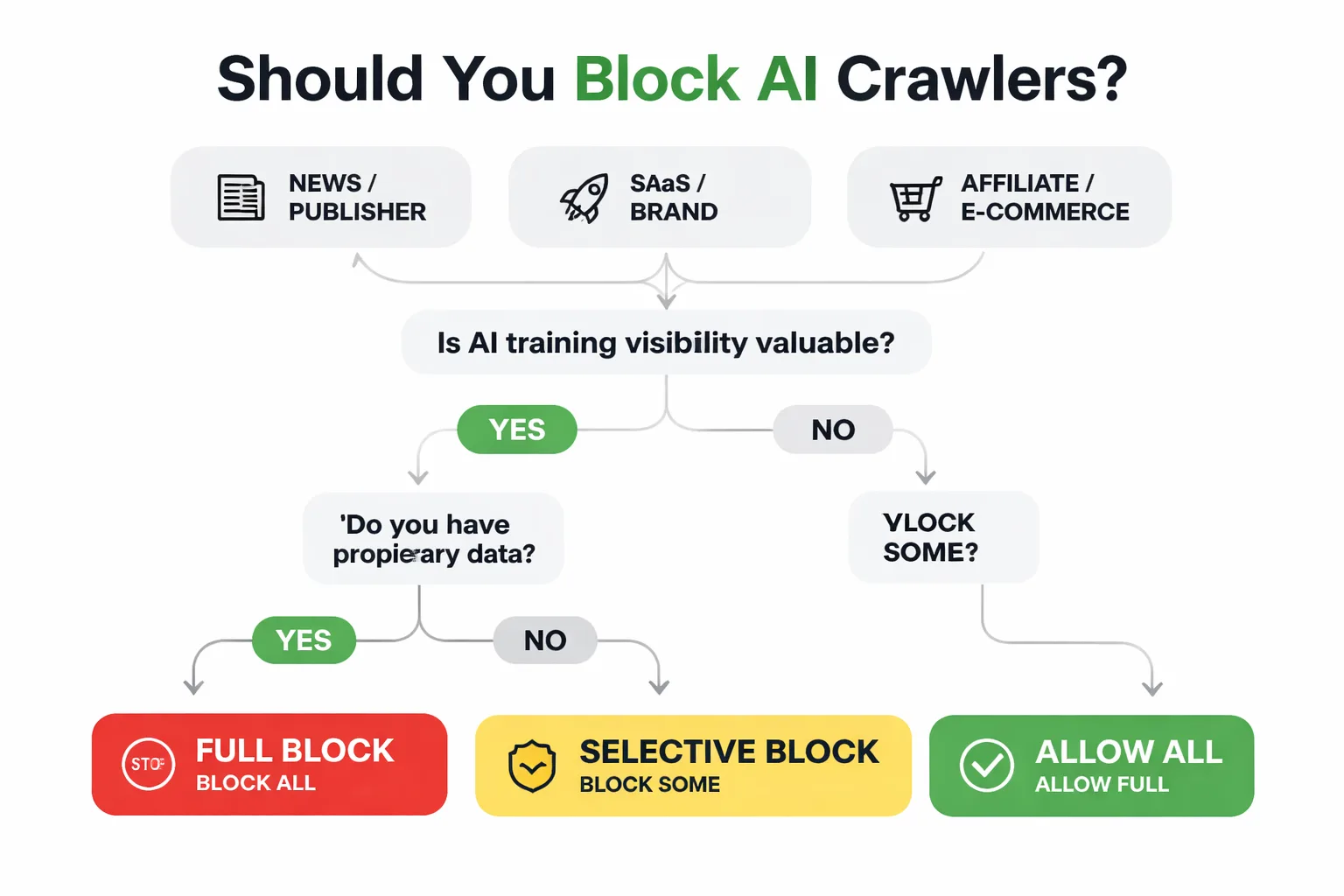
As Head of Content Strategy at Meev, I've worked with content teams across SaaS, publishing, e-commerce, and affiliate verticals — and the right Google-Extended blocking decision is genuinely different for each. Use this framework.
Block Google-Extended if: - You publish original research, proprietary data, or premium editorial content that represents a competitive moat - Your revenue model depends on users coming to your site to consume content (subscriptions, ad revenue, lead generation) - You have no current strategy for appearing in AI Overviews and aren't prioritizing AEO optimization - Your content is in a YMYL (Your Money, Your Life) category where AI misrepresentation is a liability risk
Allow Google-Extended if: - You're a SaaS brand trying to build topical authority and want your content cited in AI-generated answers - Your content is largely educational or definitional — the kind that AI Overviews pull from to answer user questions - You're actively investing in building topical authority with AI content and want AI systems to recognize your brand as a source - Your competitive advantage is brand recognition, not content exclusivity
Use selective blocking if:
- You want to protect specific high-value sections (e.g., /research/, /premium/) while allowing AI crawlers on marketing pages
- You're a news publisher with a mix of paywalled and free content
The selective blocking syntax is straightforward:
User-agent: Google-Extended
Disallow: /research/
Disallow: /premium/
Allow: /blog/
Allow: /
This is the approach I'd recommend for most mid-size content operations. Protect the IP that actually differentiates you. Let the marketing content do its job in AI search.
| Site Type | Recommended Stance | Primary Risk | Primary Opportunity |
| News / Publisher | Block or Selective | Content commoditization | None — AI doesn't drive subscriptions |
| SaaS / Brand | Allow or Selective | Minimal | AI Overview citations, brand authority |
| Affiliate / E-commerce | Selective | Product data scraping | AI-assisted product discovery |
| Agency / Consultant | Allow | Low | Thought leadership in AI answers |
| Research / Data | Block | IP theft | None — protect the moat |
Not sure whether blocking AI crawlers is helping or hurting your content strategy?
What SGE Visibility Trade-Off Does Google-Extended Blocking Create?
Here's the part that most robots.txt guides skip entirely, and it's the part that actually determines whether blocking is the right call for your business.
When you block Google-Extended, you're not just opting out of AI training data. You're reducing your chances of appearing in Google's AI Overviews — the AI-generated summaries that now appear at the top of search results for a growing percentage of queries. The relationship between Google-Extended crawling and AI Overview inclusion isn't perfectly documented by Google, but the directional logic is sound: if Google can't process your content through its AI-oriented crawlers, it has less signal about how your content fits into generative responses.
I want to be precise here, because this is where a lot of speculation gets passed off as fact. Google has not confirmed a direct causal link between blocking Google-Extended and exclusion from AI Overviews. What we do know is that AI Overviews pull from indexed content, and Googlebot handles indexing independently of Google-Extended. So blocking Google-Extended doesn't automatically remove you from AI Overviews. But it does reduce Google's ability to understand your content in the context of generative AI use cases — and that's a real trade-off worth pricing in.
For brands actively investing in Answer Engine Optimization — structuring content to be cited by AI systems rather than just ranked in traditional search — blocking Google-Extended is a strategic contradiction. You can't optimize for AI citation while simultaneously telling Google's AI crawler to stay out. Pick a lane.
**"Blocking Google-Extended while trying to win AI Overviews is like soundproofing your store and wondering why foot traffic dropped."
How to Know If Your Google-Extended Blocking Is Actually Working
This is the monitoring gap I see most often. Teams add the robots.txt directives, feel good about it, and never verify whether AI crawlers are actually respecting the instructions. Spoiler: not all of them do.
Robots.txt is a voluntary protocol. Googlebot, Bingbot, and most legitimate crawlers respect it. But some AI training crawlers — particularly less scrupulous ones — treat robots.txt as a suggestion rather than a rule. Applebot surged 124% in Q1 2026 to become the sixth-largest AI crawler, and its compliance behavior is less documented than Google's.
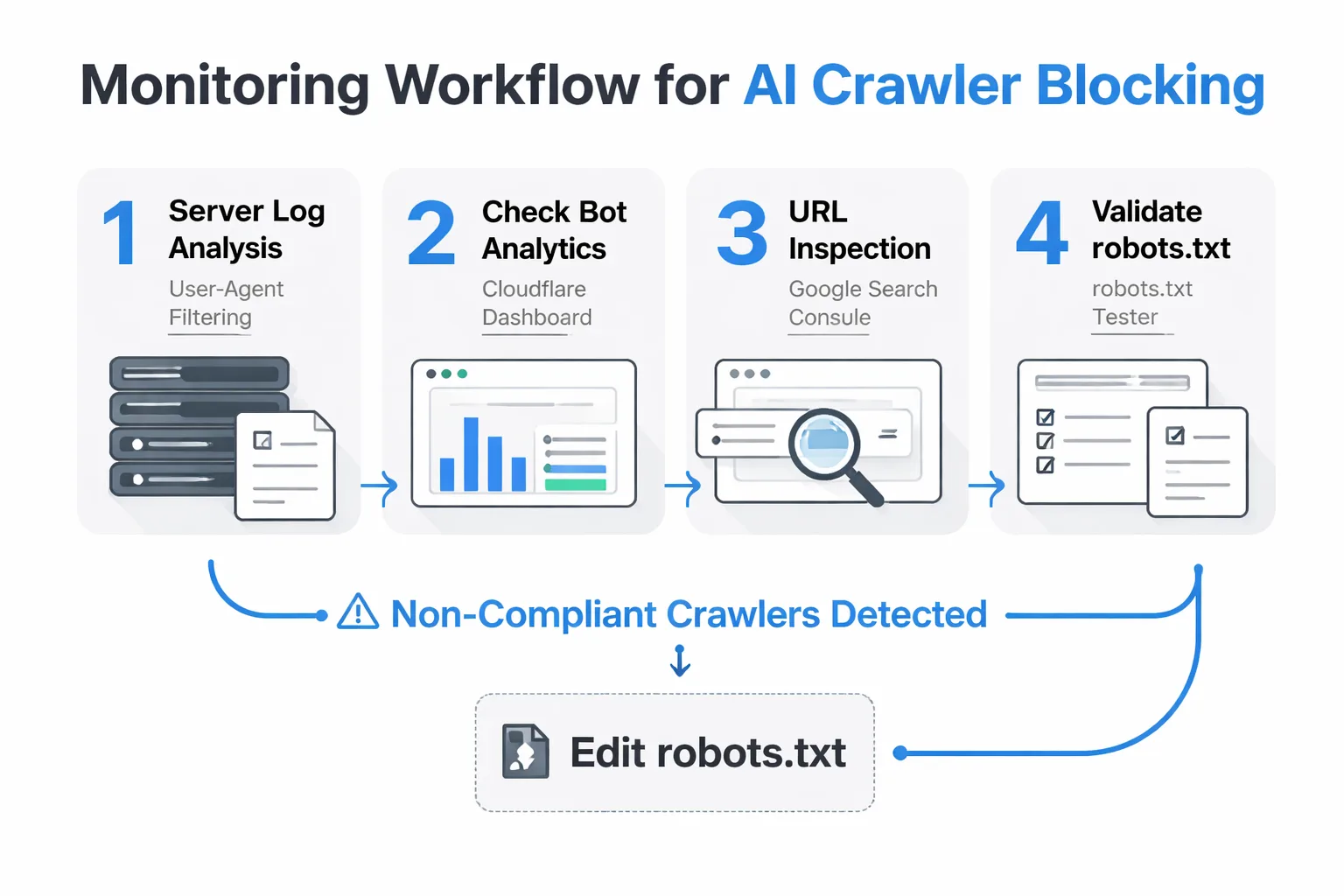
Here's how I monitor blocking effectiveness across the sites I manage:
1. Server log analysis: Pull your raw server logs and filter by user-agent strings. If you're seeing requests from Google-Extended, GPTBot, or CCBot after implementing blocks, those crawlers are ignoring your directives. This is the ground truth — more reliable than any third-party tool.
2. Cloudflare Bot Analytics: If you're on Cloudflare (and most serious sites should be), their bot analytics dashboard breaks down traffic by bot category. You can see AI crawler traffic in near-real-time and set up firewall rules to hard-block non-compliant crawlers at the network level — which is more enforceable than robots.txt alone.
3. Google Search Console: Use the URL Inspection tool to confirm Googlebot can still access your pages after any robots.txt changes. This is your safety check. If Googlebot is blocked, you'll see it here before it becomes a ranking crisis.
4. robots.txt Tester: Google's own tool in Search Console lets you test specific URLs against your robots.txt rules. Run your most important pages through it every time you edit the file.
For crawlers that ignore robots.txt, the escalation path is: robots.txt → IP blocking via .htaccess or Cloudflare firewall rules → legal (terms of service enforcement, as Reddit pursued). Most legitimate AI companies will comply with robots.txt. For the ones that don't, network-level blocking is your next lever.
How Is the Bot Traffic Shifting for Robots.txt AI Crawlers?
One finding from the Q1 2026 data that I didn't expect: Googlebot fell below 32% of total bot traffic for the first time. That's a structural shift, not a blip. As AI training crawlers proliferate — and Applebot's 124% surge suggests we're in an acceleration phase — the robots.txt decisions you make today will have compounding effects on how AI systems understand and represent your brand over the next 12-24 months.
The content teams I work with who are thinking about this clearly are treating their robots.txt as a living strategic document, not a set-and-forget config file. They're revisiting it quarterly, cross-referencing it against their AEO goals, and making deliberate choices about which crawlers get access to which content sections.
If you're building a content operation that needs to survive the next wave of AI search disruption, the robots.txt question is inseparable from your broader content moat strategy. What makes your content worth protecting? What makes it worth sharing with AI systems? Those are the questions that should drive your blocking decisions — not a generic "block everything" or "allow everything" default.
The sites that will win in AI search aren't the ones that locked down their robots.txt the tightest. They're the ones that made deliberate, strategic choices about where their content creates value — and configured their Google-Extended blocking accordingly.
FAQ
Will blocking Google-Extended hurt my Google Search rankings?
No, blocking Google-Extended will not affect your standard Google Search rankings. Googlebot, the indexing crawler, is separate from Google-Extended, which is used for AI training data collection. These crawlers have distinct purposes, so you can block one without impacting the other.What is Google-Extended and why block it?
Google-Extended is a crawler used by Google to gather content for AI training, distinct from the Googlebot indexing crawler. It accounts for nearly 50% of AI bot traffic and requests 2.5× more data per event. Blocking it prevents your content from being used to train large language models without affecting SEO.How can I block Google-Extended without risking over-blocking?
Use precise robots.txt rules to target "Google-Extended" specifically, avoiding broad blocks that might hit Googlebot. Test configurations carefully, as missteps—like Reddit's 2024 incident—can collapse organic visibility. Prioritize robots.txt hygiene in technical SEO audits.Should I block AI crawlers based on my site type?
It depends on your site: news publishers may want full blocks for IP protection, SaaS/brand sites selective blocks for proprietary data, and affiliate/e-commerce sites might allow for AI Overview visibility. Use a decision matrix evaluating AI training value and data sensitivity. Over-blocking risks SEO, so tailor to your value exchange.Let Meev audit your robots.txt and crawler strategy — so you protect your content without sacrificing a single ranking.