
The Content Moat Strategy: How to Make Your Blog Irreplaceable in the Age of AI Search
The era of 'good enough' content is officially over. As AI Overviews begin to synthesize answers directly from the SERPs, the traditional traffic-for-clicks model is collapsing. If your strategy relies on being the most accessible source of information, you are already obsolete. To survive the next wave of search evolution, you need to stop chasing volume and start building a content moat—a defensive perimeter of proprietary data, unique perspectives, and brand-specific insights that AI cannot replicate.
The blogs that survive this shift won't be the ones with the most content. They'll be the ones with the deepest content moat strategy — a defensive layer of proprietary insight, brand authority, and structural signals that AI systems can't replicate, scrape, or hallucinate away. After 18 months of building and testing these systems, I've seen exactly what that looks like.
TLDR
- Zero-click searches now exceed 60% of all Google queries — if your content doesn't have a moat, you're building on sand. - A content moat is built from four things AI can't fake: proprietary data, first-hand experience, brand authority, and GEO-optimized structure. - Automation scales your moat — it doesn't replace it. The right workflow cuts production time by 97% while keeping the human signal intact. - Measure moat depth with citation rate, branded search volume, and return visitor rate — not just organic traffic.What Is a Content Moat Strategy?
A content moat is the combination of assets, signals, and structural advantages that make your content irreplaceable — even when AI can generate a passable version of it in 30 seconds. Think of it like a castle: the content is the castle, but the moat is what keeps competitors (and AI summaries) from simply copying the floor plan and building next door.
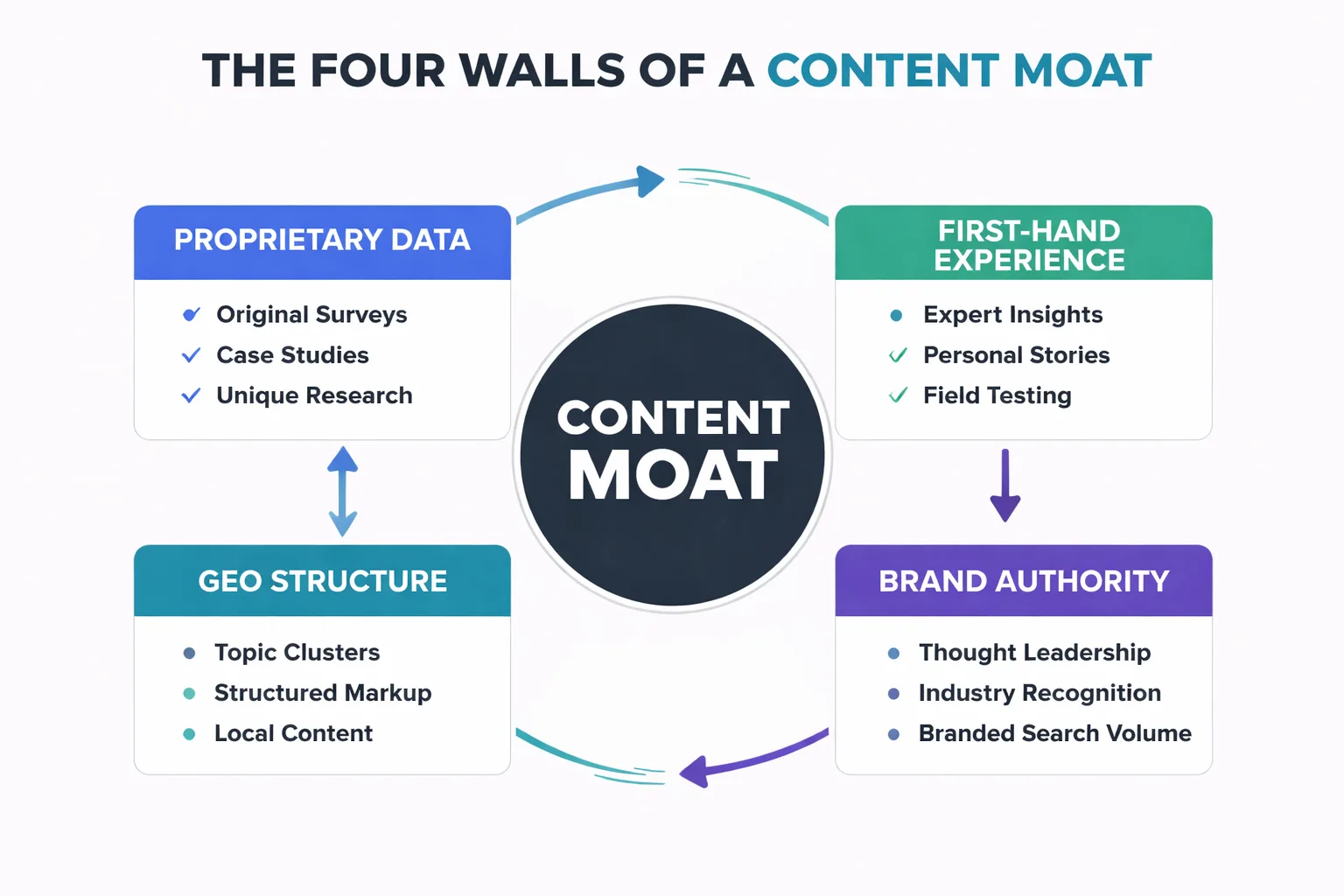
In practical terms, a content moat has four walls. First, proprietary data — original research, surveys, or case studies that no one else has. Second, first-hand experience — the kind of specific, opinionated insight that comes from actually doing the thing, not summarizing what others have written about it. Third, brand authority — the accumulated trust signals that make readers (and AI engines) prefer your source over a generic one. Fourth, GEO-optimized structure — the technical formatting that makes your content extractable and citable by AI Overviews, Perplexity, and ChatGPT.
Most blogs have none of these. They have content. That's not the same thing.
Why 'SEO-Only' Content Is Now a Liability
Most people think keyword-optimized content is still the foundation of a content strategy. In my experience, that assumption is wrong — and the data is brutal about it.
According to Gartner, traditional search engine volume is predicted to drop 25% by 2026, with AI chatbots and virtual agents absorbing that market share. Meanwhile, The Digital Bloom reports that over 60% of all Google searches already result in zero clicks. Let that sink in: the majority of searches never produce a visit to any website. If your entire strategy is built on ranking for informational keywords, you're optimizing for a shrinking pool of clicks.
In my work leading content strategy at Meev, the content I've seen hit hardest by AI Overviews is the content that was purely SEO-optimized — thin answers to common questions, structured exactly the way Google's featured snippet algorithm wanted, with no proprietary angle. That content was essentially pre-formatted for AI to consume and redistribute. I'd built the perfect meal, and Google's AI ate it without inviting anyone to the table.
The content that survives? It contains something the AI can't synthesize: a real case study with specific numbers, a contrarian take backed by original data, or a structured comparison that only exists because someone actually ran the experiment. That's ai content differentiation in its most practical form — not writing differently from AI, but writing with assets AI doesn't have access to.
"SEO-only content doesn't just fail to build a moat — it actively trains AI systems to replace you."
How Do You Build Proprietary Data for a Content Moat Strategy?
Proprietary data is the single most defensible asset in a content moat strategy, and in my experience, it's more accessible than most marketers think. No research budget is required — just a system.
I recommend starting with operational data — client results, campaign performance, A/B test outcomes, conversion rates. This is data that literally no one else has. One outdoor gear brand I worked with through Meev had a single article — "Best Hiking Boots for Pacific Northwest Rain" — that generated 12,000 organic visits in its first month and drove $8,400 in attributed revenue. That number exists nowhere else on the internet. It's uncopyable. When that article cites those specific figures, no AI can hallucinate a competing version because the data is anchored to a real, verifiable outcome.
Second, I recommend running micro-surveys. A 10-question survey sent to an email list of 500 people produces original data that can anchor three to five articles. Siege Media's 2026 content marketing research found that the percentage of people using AI for brainstorming fell from 72% in 2025 to 61% in 2026 — that's the kind of specific, time-stamped data point that gets cited across the industry. I've found that equivalent data in any niche is achievable with a free Typeform and a week of patience.
Third, I recommend documenting your process publicly. If you have a workflow, a framework, or a methodology — name it, describe it in detail, and publish it. Named frameworks become citation anchors. They're the kind of thing AI systems reference rather than replace.
The GEO Layer Most Blogs Are Missing
Generative Engine Optimization — GEO — is the practice of structuring content so that AI systems can extract, cite, and surface it accurately. It's not the same as traditional SEO, and in my work with content teams, I've found that most blogs are completely ignoring it.
The core principle is this: AI engines don't rank pages, they extract answers. So content needs to be structured as a series of extractable, self-contained answers — not a flowing essay that requires context to understand. Every H2 section should open with a 40-60 word paragraph that directly answers the question implied by the heading. No pronoun references to previous sections. No "as mentioned above." Each answer should stand alone.
Beyond structure, I've identified three technical signals that matter most for GEO. First, use Google Search Console structured data markup — FAQ schema, HowTo schema, and Article schema tell AI crawlers exactly what type of content they're reading and how to extract it. Structured data errors mean invisibility to rich results and AI citations. Second, use bold standalone sentences that make a specific, quotable claim. AI systems are pattern-matching for extractable insights — give them clean targets. Third, publish with a consistent author entity. A named author with a linked bio, consistent byline, and verifiable credentials is dramatically more likely to be cited by AI systems than anonymous or generic content.
For a deeper look at how to structure content for AI Overviews without losing a human audience, I've put together a full breakdown at Write for AI Overviews Without Losing Your Audience — the tactical section on answer-first formatting is directly applicable here.

Can Automation Scale a Moat Without Diluting It?
This is the question I get asked most often — and it's the right one to ask. The standard advice is to choose between quality and scale. I've found that framing backfires in 2026.
The brands winning right now are using automation to handle the repeatable parts of content production — keyword research, structural formatting, internal linking, meta optimization — while keeping the human layer for the things that actually build the moat: original data, first-hand perspective, and editorial judgment. That's not a compromise. That's the correct division of labor.
I've seen this play out directly with an outdoor gear e-commerce brand that implemented Meev's content pipeline. Before automation, they were publishing 2 articles per month, each taking 6-8 hours of their marketing team's time, at a cost of roughly $2,400/month in freelance writing fees. After implementing automated research-first content production, they scaled to 12 articles per month at 4 minutes per article, with organic traffic increasing 340% in six months and 23 articles reaching Google page 1 within 90 days. Their monthly content cost dropped to $49. But here's the part that matters for the moat conversation: the articles that performed best weren't the ones that were purely automated. They were the ones where the automated structure was layered with a specific case study, a real product comparison, or a first-hand recommendation. The automation built the scaffolding. The human signal built the moat.
Automation scales your content surface area. Proprietary insight makes that surface area defensible.
61% of marketers are increasing their SEO budgets in 2026, up from 44% in 2025. The ones spending that budget on pure volume without a moat strategy are going to have a very bad 2027.
What Metrics Actually Measure Moat Depth?
Vanity traffic metrics won't tell you if your moat is working. Here's what I actually track.
Branded search volume is the clearest signal. If people are searching for your brand name alongside a topic — "[your brand] hiking boots review" instead of just "hiking boots review" — you've built something AI can't replace. I track this monthly in Google Search Console.
AI citation rate is newer but increasingly measurable. I recommend running your primary keywords through ChatGPT, Perplexity, and Google's AI Overview. Are you being cited? If not, the GEO layer needs work. If yes, track whether citations are increasing month over month.
Return visitor rate tells you whether readers trust you enough to come back. A high return visitor rate means you've built a brand relationship, not just a traffic source. Google Analytics 4 surfaces this in the Retention report.
Backlink velocity from primary sources — not just any backlinks, but links from industry publications, research roundups, and authoritative sites. These signal that your proprietary data is being recognized as a reference point.
Moat metrics vs. standard SEO metrics:
| Standard SEO Metric | Moat Metric | Why It Matters |
| Organic traffic | Branded search volume | Measures brand pull, not just keyword ranking |
| Keyword rankings | AI citation rate | Measures visibility in AI-mediated search |
| Pageviews | Return visitor rate | Measures trust and audience loyalty |
| Domain authority | Primary source backlinks | Measures reference authority, not just link count |
| Bounce rate | Time-on-page by content type | Measures depth of engagement with moat content |
The One Thing That Protects You From Being Scraped
Here's a question most content marketers haven't thought through: what happens when your content gets ingested by an LLM and redistributed without attribution? It's already happening. Google-Extended blocking lets you opt out of certain AI training crawls via your robots.txt file, but that's a partial solution at best — it doesn't protect content that's already been indexed.
The real protection isn't technical. It's brand embedding. When content is so thoroughly associated with your brand — through named frameworks, consistent author voice, specific data points that trace back to you, and a recognizable editorial perspective — it becomes self-attributing. Even when an AI summarizes the content, the fingerprints point back to you. Readers who encounter the summary and want depth know where to go.
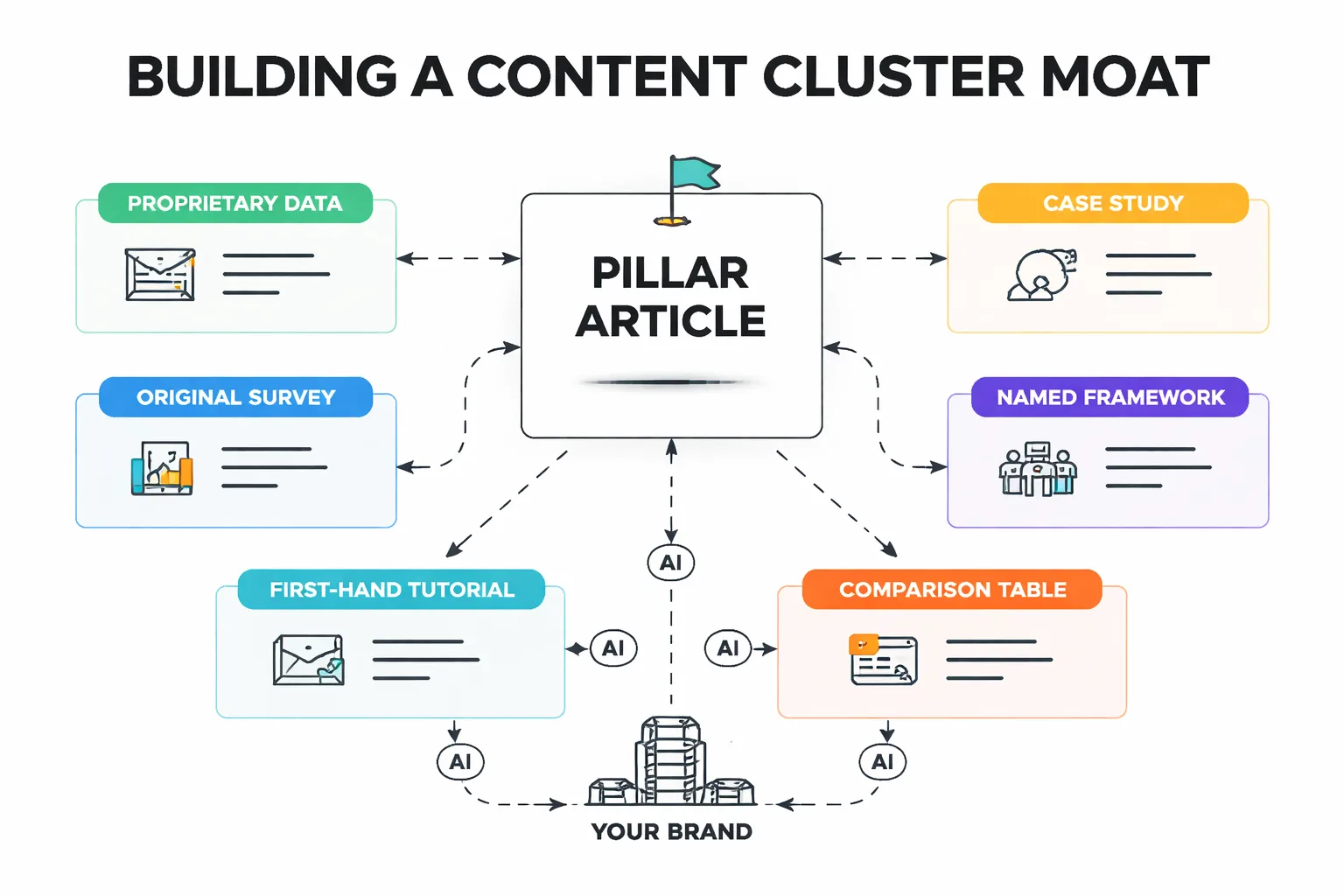
This is why I believe building a content cluster strategy around core topics matters so much right now. A cluster of 15 interlinked articles on a topic, all carrying your proprietary data and named frameworks, creates a web of attribution that's much harder to dissolve than a single standalone article. The moat isn't one deep trench — it's an interconnected system.
Rapid-Fire Round
How long does it take to build a content moat? In my experience, measurable moat signals — branded search growth, AI citations, return visitor lift — typically appear around the 90-day mark when publishing consistently with proprietary data. A defensible moat takes 6-12 months of deliberate layering.
Does a content moat work for small blogs with no audience yet? Absolutely — and I've found it's actually easier to build from scratch than to retrofit an existing content library. Start with one proprietary data point (even a small survey or documented case study), build the first cluster around it, and let the GEO structure do the citation work early.
Should I block AI crawlers with Google-Extended blocking? Only if there's a specific reason to protect unpublished or paywalled content. For most content marketers, being cited by AI systems is a distribution advantage, not a threat. The goal is to be cited accurately and with attribution — which is a GEO problem, not a robots.txt problem.
What's the fastest single thing I can do today to start building a moat? My recommended starting point is to pick your single best-performing article and add one proprietary data point to it — a specific result from your real experience, a mini-survey finding, or a named framework for the process you're describing. Then add FAQ schema markup. That combination of original data plus structured markup is the fastest path to AI citation and moat depth simultaneously.