
By Judy Zhou, Head of Content Strategy
Key Takeaways
- 42% of B2B software buyers now use AI search during vendor evaluation, and 63% of product discovery queries in ChatGPT are comparison-style — making GEO a pipeline issue, not just an SEO issue.
- ChatGPT pulls 6x more pages than it cites, and roughly 30 domains capture 67% of citations within any topic, meaning content architecture and brand co-occurrence matter more than domain authority for challenger SaaS brands.
- The mention-citation gap — where your content is cited as a source but your brand isn't recommended in the response — affects roughly 80% of brands and is fixed at the editorial level, not the technical level.
- A 3-person SaaS content team can build minimum viable GEO infrastructure in 90 days: 5 restructured comparison pages, 10 use-case landing pages, an active review amplification program, and a live citation monitoring setup.
AI just became your most influential sales rep — and you didn't hire it.
Generative engine optimization isn't a future concern for B2B SaaS teams. It's an active gap in most content strategies right now. According to HubSpot, 42% of CRM software buyers already use AI search during vendor evaluation, and ChatGPT and Gemini usage is up 37% while traditional search engine usage is down 11%. The brands getting cited in those AI responses are winning deals before a sales rep ever enters the picture. The brands getting skipped are invisible at the most critical moment in the buying journey. SE Ranking's analysis of 129,000 domains found that sites with over 350,000 referring domains averaged 8.4 ChatGPT citations, versus 1.6-1.8 for sites with up to 2,500 referring domains — a 5x gap driven almost entirely by authority signals, not content quality alone. And ChatGPT pulls 6x more pages than it cites, meaning most of the content it reads never surfaces in a response.
This article is a tactical playbook for B2B SaaS content teams who want to close that gap.
How B2B SaaS Buyers Actually Use AI Search Now
The buyer journey has restructured around AI-generated answers, and most SaaS content teams haven't caught up to what that actually looks like in practice.
Here's what's changed. Buyers aren't starting with a Google search for "best project management software" and clicking through to G2. They're opening ChatGPT or Perplexity and typing something like "what's the difference between Asana and Monday.com for a 50-person engineering team" or "which CRM integrates best with HubSpot and has the lowest total cost of ownership under $500/month." These are long, contextual, comparison-heavy queries. They're looking for a synthesized answer, not a list of blue links to evaluate. According to Datos 2025 research cited by practitioners tracking AI search behavior, 63% of product discovery queries in ChatGPT are comparison-style. That number stopped me cold when I first saw it.
The implication for SaaS content teams is significant. Traditional SEO optimizes for informational intent and navigational queries. The queries that actually move B2B buyers through evaluation stages are comparative and specific. Your "what is [product category]" content gets traffic. Your "[your tool] vs [competitor]" content gets cited in the responses that actually influence purchase decisions.
I've watched this play out in campaigns we've run at Meev, where I oversee content strategy across hundreds of brands. The pattern is consistent: companies with strong topical authority for AI search in their category get pulled into AI responses even when their domain authority is lower than competitors. The mechanism isn't mysterious. AI models are doing something closer to editorial synthesis than traditional ranking. They're looking for sources that make specific, attributable claims about specific use cases — not sources that rank for broad category terms.
The other thing worth naming: buyers are using AI search at the shortlisting stage, not just research. They're asking "is [tool] worth it for a team our size" and "what are the main complaints about [tool] from enterprise customers." If you're not present in those responses, you're not on the shortlist.
The Comparison Query Problem for SaaS Brands
The citation distribution in AI search is deeply unequal, and the mechanics of that inequality are worth understanding before you build any GEO strategy.
Kevin Indig's study of ChatGPT citation patterns found that roughly 30 domains capture 67% of citations within any given topic. In product comparison topics specifically, the top 10 domains account for 46% of citations. That's a winner-take-most dynamic that looks nothing like traditional search, where a long tail of pages can each capture some traffic. In AI search, if you're not in the top tier of cited sources, you're effectively invisible for that query type.
For challenger SaaS brands, this is both the problem and the opportunity. The problem: you're not G2, Capterra, or TechRadar. You don't have 350,000 referring domains. The SE Ranking data shows a threshold effect at 32,000 referring domains where citations nearly double from 2.9 to 5.6 — a meaningful inflection point, but still out of reach for most mid-market SaaS companies in the short term.
The opportunity: content architecture matters more than domain authority for comparison queries. What I keep seeing in our work is that AI models surface specific pages, not entire domains. A well-structured comparison page with explicit feature claims, named use cases, and structured data can get cited even when the root domain has modest authority — because the retrieval layer is looking for the most directly responsive content, not the most authoritative domain.
The failure mode I'd warn against is treating this as a link-building problem. You can't backlink your way into AI citation dominance for comparison queries. The brands that consistently appear in "[tool A] vs [tool B]" responses have content that explicitly answers those queries with specific, attributable claims. That's an editorial problem, not a technical one.
For Google AI Overviews specifically, the citation patterns are slightly different from ChatGPT or Perplexity — Google's retrieval layer weights freshness and structured content more heavily. But the core principle holds: the page that most directly answers the comparison query wins, not the page from the highest-authority domain.
Want to see which AI engines are citing your competitors — and skipping you?
5 GEO Tactics Specific to SaaS Content Teams

These five tactics are ordered by implementation speed, not importance. Start where your content infrastructure is strongest.
1. Feature comparison pages built for AI retrieval
Most SaaS comparison pages are written for humans who skim. AI models need something different: explicit, structured claims that can be extracted and attributed. A comparison page that says "[Your Tool] offers real-time collaboration while [Competitor] requires manual refresh" is extractable. A page that says "[Your Tool] is great for teams" is not.
The structural requirements are specific. Each feature comparison should have a clear header naming the feature, a one-sentence claim about your tool's behavior, a one-sentence claim about the competitor's behavior, and a named use case where the difference matters. This structure lets AI retrieval systems pull your content as a direct answer to "what's the difference between X and Y for [use case]." Pair this with FAQ schema markup and you're giving both Google AI Overviews and Perplexity a clean extraction path.
2. Use-case landing pages with structured claims
Generic product pages don't get cited. Pages that say "[Tool] for enterprise security teams: SOC 2 Type II certified, role-based access controls, and audit logging for compliance workflows" do. The specificity is the signal. AI models are synthesizing answers to specific buyer queries — they need content that matches the specificity of the question.
For each major use case your product addresses, build a page that names the persona, names the workflow, lists specific capabilities with concrete outcomes, and includes at least one third-party validation signal (a customer quote with a named company, a review excerpt, a certification). These pages pull disproportionately well in Perplexity citations because Perplexity's retrieval layer heavily weights specificity and recency.
3. Third-party review amplification
This is the tactic most SaaS teams underinvest in. G2, Capterra, and Trustpilot reviews don't just influence buyers directly — they get cited by AI models as trust signals. When ChatGPT synthesizes an answer about your tool's strengths and weaknesses, it's often pulling from review aggregators, not your own site.
The strategic implication: actively prompt satisfied customers to leave reviews that include specific use case language. A review that says "We switched from [Competitor] to [Your Tool] because the API documentation made our Salesforce integration 3x faster" is far more useful for AI citation purposes than "Great product, highly recommend." The specificity makes it citable. Running a review amplification campaign with use-case-specific prompts is one of the highest-leverage GEO moves a SaaS content team can make.
4. Integration documentation as citation bait
This one surprises people. Integration documentation — the pages that explain how your tool connects with Salesforce, Slack, HubSpot, or whatever ecosystem your buyers live in — gets cited at a rate that's disproportionate to its traffic. The reason is that buyers frequently ask AI models about integration compatibility, and documentation pages are among the most structured, specific, and authoritative sources available.
If your integration docs are thin, outdated, or buried in a developer portal that's blocked from crawling, you're leaving citations on the table. Treat integration documentation as editorial content: include use case context, specific data flow descriptions, and troubleshooting scenarios. A page that explains not just that your tool integrates with HubSpot but how that integration handles contact deduplication for enterprise teams is a citation magnet.
5. Analyst mention outreach
This is the most underutilized tactic in B2B SaaS GEO. Industry analysts, independent reviewers, and category-specific publications are disproportionately cited by AI models because they're treated as high-authority, neutral sources. Getting your brand named explicitly in an analyst report or a category roundup on a publication with strong domain authority is worth more for AI citation purposes than most content you'll produce yourself.
The key is the pitch brief. I've watched campaigns produce zero AI visibility lift because the pitch was optimized for a backlink, not a brand mention. The journalist wrote "according to a recent study" and linked to the brand — and the AI model had no reliable signal to surface that brand in a recommendation. The pitch brief needs to explicitly request that the journalist name your brand in the context of the specific claim. "[Your Tool] reduced onboarding time by 40% for mid-market teams" is citable. A hyperlink is not.
For tracking which publishers are already citing your competitors, tools like Meev vs Profound (2026) offer AI search visibility comparison features that surface citation gaps by publication and query type.
Measuring GEO Performance in a B2B Funnel
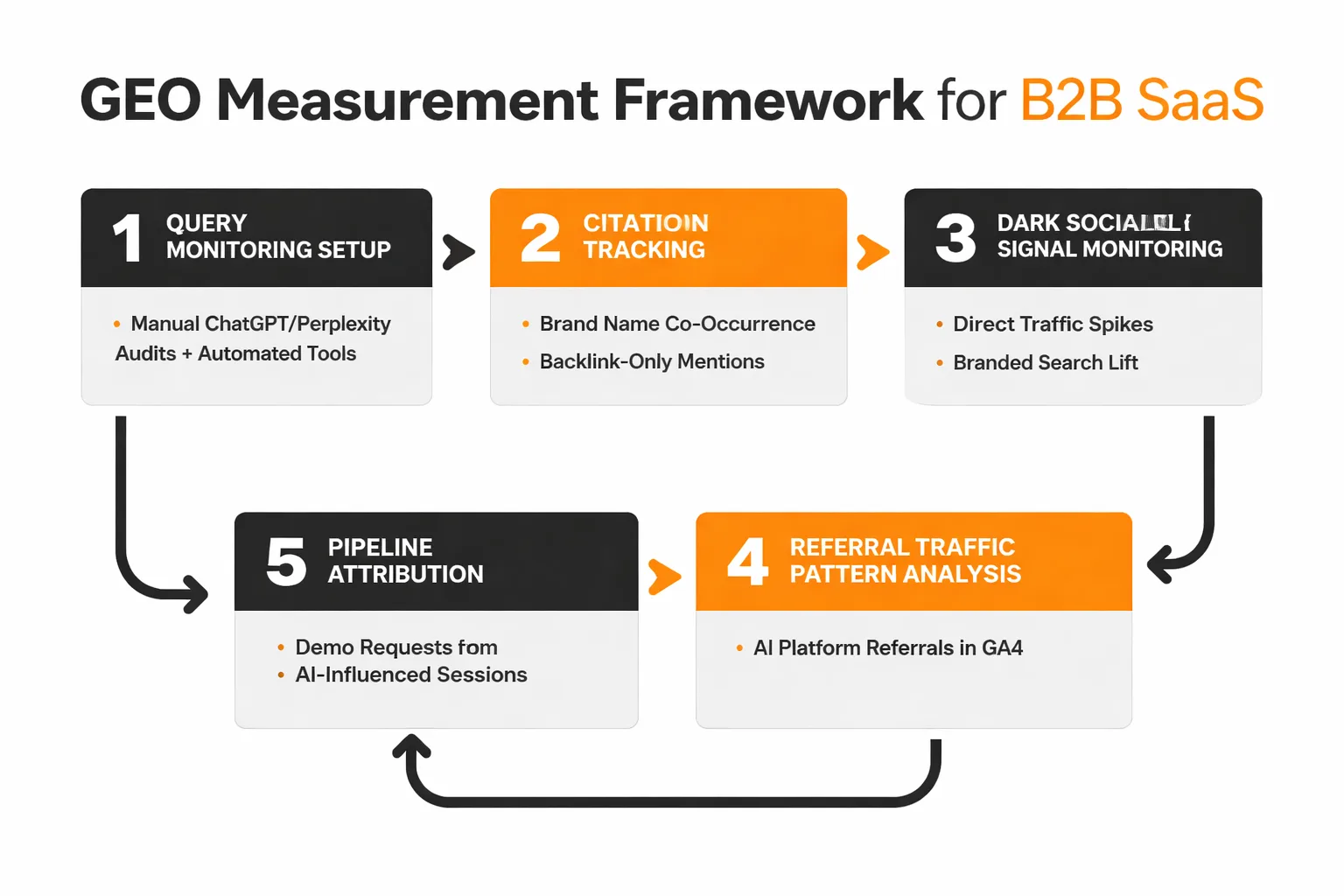
Most GEO measurement frameworks I've seen are broken in the same way. They track whether a brand appears in AI responses (a visibility metric) without connecting that visibility to pipeline activity (a revenue metric). For B2B SaaS, where the sales cycle is long and multi-touch, that gap makes GEO look like a vanity exercise.
Here's how to build a measurement framework that connects to the funnel.
Query monitoring setup. Start with a manual audit of 20-30 comparison queries your buyers are likely to run in ChatGPT, Perplexity, and Google AI Overviews. Document which competitors appear, which sources get cited, and whether your brand is mentioned. Do this weekly. The manual process is slower but forces your team to actually read the AI responses rather than just counting appearances. For scale, tools that track Perplexity citations and AI Overviews mentions automatically can supplement the manual work — but don't replace it. The qualitative signal (how your brand is described, what claims are attributed to you) matters as much as the frequency signal.
The mention-citation gap. This is the metric most teams aren't tracking, and it's the most important one. Your brand can appear in AI responses as a source (citation) or as a recommendation (mention). These are different things. A citation means the AI pulled your content as a reference. A mention means the AI recommended your brand to the buyer. The Ahrefs Brand Radar data suggests roughly 80% of brands have a significant gap between citations and mentions — they're getting pulled as sources but not surfaced as recommendations.
To track this: in your manual query audits, record separately whether your brand is cited as a source and whether it's recommended in the response text. A high citation rate with a low mention rate means your content is being read but your brand isn't being associated with the claim. That's the co-occurrence problem I described earlier, and it's fixed at the content level, not the technical level.
Dark social and direct traffic signals. AI-driven discovery often doesn't produce referral traffic in the traditional sense. Buyers who see your brand in a ChatGPT response may open a new tab and search your brand name directly, or navigate directly to your site. This shows up as direct traffic or branded search volume, not as a ChatGPT referral. If you see branded search volume increasing in periods when your AI citation frequency is also increasing, that's a strong signal of AI-driven discovery.
Pipeline attribution. For B2B SaaS, the ultimate GEO metric is whether AI-influenced sessions convert to demo requests or trial signups at a different rate than other sessions. This requires UTM discipline and a CRM that can segment by traffic source. It's imperfect, but tracking the conversion rate of sessions that arrive via branded search (as a proxy for AI discovery) versus sessions from organic long-tail gives you a directional read on whether GEO investment is moving pipeline.
For teams evaluating purpose-built AI visibility platforms, the Meev vs Sight AI comparison breaks down citation outreach and quality-gated publishing features that are specifically relevant to this measurement workflow.
A 90-Day GEO Roadmap for a SaaS Content Team of 3

A team of three can execute a meaningful GEO program without adding headcount. Here's how to phase the work.
Days 1-30: Audit and architecture.
Week 1 is entirely diagnostic. Run a citation audit across 25 comparison queries in ChatGPT, Perplexity, and Google AI Overviews. Document every source cited, every competitor mentioned, and every query where your brand is absent. This becomes your gap map.
Week 2: map your existing content against the gap map. Which comparison pages do you have? Are they structured for AI retrieval (explicit claims, named use cases, FAQ schema) or for human skimmers (prose-heavy, no structured data)? Identify the 5 pages with the highest potential for citation if restructured.
Weeks 3-4: restructure those 5 pages. Add explicit feature comparison tables, use-case-specific claims, and FAQ schema. Publish at least 2 new comparison pages targeting queries where competitors are currently cited and you're not. Use the 5-step Perplexity citation framework to structure each page's content architecture.
Days 31-60: Content production and outreach.
Month 2 is about volume and external signals. Assign one person to integration documentation: audit every integration page, identify which ones are thin or unstructured, and rewrite the top 10 with use-case context and specific data flow descriptions.
Assign a second person to the review amplification campaign. Identify 20-30 customers with strong use cases and prompt them with specific review language tied to your target comparison queries. "We switched from [Competitor] because [specific claim]" is the template.
The third person runs analyst outreach. Identify 10-15 publications or independent analysts who regularly cover your category and are cited in your target AI responses. Pitch them with explicit brand-mention briefs, not link-building pitches. The goal is co-occurrence: your brand name appearing alongside the specific claim in the resulting content.
For teams evaluating whether to build this workflow in-house or use a platform, the Meev vs Jasper AI comparison covers the difference between auto-blogging volume tools and quality-gated citation-focused publishing — which matters a lot for this phase of the roadmap.
Days 61-90: Measure, iterate, and scale.
Run the citation audit again at day 60. Compare citation frequency and mention rate against your day-1 baseline. You should see movement in Perplexity and Google AI Overviews within 60 days if the content restructuring was executed correctly — these platforms update their retrieval indexes more frequently than ChatGPT's training cycles.
Identify the 3 pages that moved most and the 3 that didn't move at all. The movers tell you what's working structurally. The non-movers tell you where the gap is competitive rather than architectural (i.e., a dominant player has locked up citations for that query and you need more external mention volume to break through).
By day 90, you should have a repeatable content production workflow, an active review amplification program, and a live citation monitoring setup. That's the minimum viable GEO infrastructure for a SaaS content team. Everything after day 90 is iteration and scale.
One honest note on timeline expectations: the Ahrefs study of 75,000+ brands and millions of AI citations confirms that topical authority for AI search builds over months, not weeks. The 90-day roadmap gets you infrastructure and early signals. Meaningful citation share in competitive categories typically takes 6-12 months of consistent execution.
FAQ
How is generative engine optimization different from traditional SEO for B2B SaaS?
Traditional SEO optimizes pages to rank for keyword queries in blue-link results. Generative engine optimization optimizes content to be extracted and cited by AI models when they synthesize answers. For B2B SaaS, the practical difference is significant: SEO targets informational and navigational queries, while GEO targets comparison and evaluation queries that happen deeper in the buying journey. You need both, but the content structure, specificity requirements, and measurement frameworks are different.
Which AI engines should a SaaS content team prioritize first?
Start with Perplexity and Google AI Overviews. Perplexity updates its retrieval index frequently, so content improvements show up in citation patterns faster than in ChatGPT, which relies more heavily on training data. Google AI Overviews pulls from Google's existing index, so pages already ranking in traditional search have a structural advantage. ChatGPT is the highest-traffic AI search engine but the hardest to influence directly — treat it as a lagging indicator of your overall GEO health.
What's the minimum content investment to start seeing AI citations?
Based on the patterns I keep seeing, you need at least 5 well-structured comparison pages, 10 use-case landing pages with explicit claims, and active presence on at least 2-3 review platforms before AI models have enough signal to consistently surface your brand. That's roughly 60-80 hours of content work. Below that threshold, citations are sporadic and hard to attribute to any specific tactic.
How do I know if my brand is being cited versus just mentioned?
A citation means the AI pulled your content as a source and listed your domain in the response's source list. A mention means your brand name appears in the response text as a recommendation. Run your target comparison queries manually and check both the response text and the source list. Track these separately — a high citation rate with a low mention rate is the co-occurrence problem, where your content is being read but your brand isn't being associated with the specific claim.
Does domain authority still matter for AI search visibility?
Yes, but differently than in traditional search. The SE Ranking data shows a clear correlation between referring domain count and ChatGPT citation frequency — sites with 350,000+ referring domains average 8.4 citations versus 1.6-1.8 for smaller sites. But the threshold effect at 32,000 referring domains suggests that mid-market SaaS brands can compete meaningfully once they cross that threshold, especially for specific comparison queries where content architecture matters more than overall authority.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Meev tracks your brand's citation frequency across ChatGPT, Perplexity, and Google AI Overviews so you can close the mention-citation gap before your next sales cycle.