
By Judy Zhou, Head of Content Strategy
Key Takeaways
- Unfiltered autoblogging at scale triggers Google's scaled content abuse classifier — a site-wide penalty that compounds before you see it in traffic data.
- Ahrefs' analysis of 730,000 AI responses found only 13.7% overlap between Google traditional search sources and AI Overviews sources, meaning ranking well does not equal AI visibility.
- A case study across 8 brands documented a 325% lift in AI citations from syndicating quality-gated content to third-party publishers — but only quality-gated content benefits.
- Reddit accounts for just 0.34% of AI answer citations across 2M+ analyzed cases, versus Wikipedia's 17.02% — making Reddit-first GEO strategies a low-ROI bet for autobloggers.
Marcus pulled up his content dashboard on a Tuesday morning in March and stared at a number he couldn't explain. His autoblogging network had published 4,200 posts over the previous six months. Organic impressions were down 71%. But one site. A niche health blog where he'd started manually reviewing every AI draft before publishing. Was trending in the opposite direction. Three of its articles had been cited inside ChatGPT responses. Two had appeared in Perplexity source cards. He hadn't changed the tools. He'd changed the threshold.
Autoblogging in 2026 works. It just doesn't work the way most people are running it. As someone who oversees AI-driven content research and publishing across hundreds of brands, the pattern I keep seeing is identical to Marcus's: the volume-first instinct is still alive, still producing the same cliff-edge results, and the teams that escape it are doing one specific thing differently. They've installed a quality gate. Everything else is noise.
Autoblogging produces measurable search and AI citation results when content passes a quality threshold before publishing. But unfiltered AI content at scale triggers Google's scaled content abuse detection and produces near-zero LLM citation rates. The distinction isn't the tool. It's the editorial checkpoint between generation and publication.
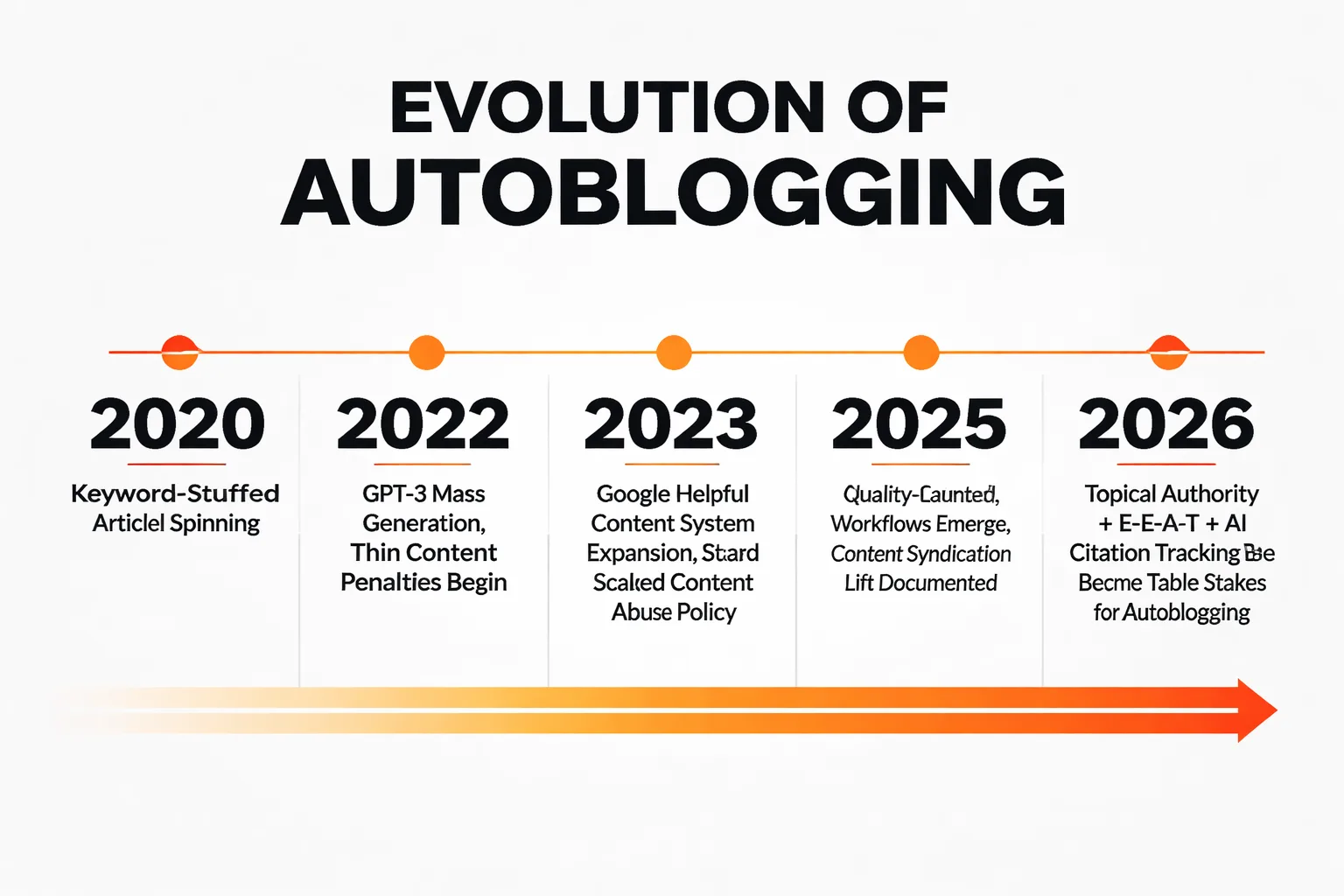
The Scaled Content Trap
Google's Helpful Content System isn't a single algorithm update you can dodge. It's a persistent, site-wide classifier that evaluates whether your content exists primarily to serve users or primarily to rank. The language Google uses in its scaled content abuse documentation is precise: generating content at scale that provides little value, whether through automation or human effort, is a policy violation. Notice that framing. It's not about AI specifically. It's about value per page.
What that means in practice: a site publishing 700 AI-generated posts a month, each pulling from the same handful of sources, each structured identically, each answering questions the user didn't actually ask. That site is accumulating a quality debt that compounds. Google's classifier doesn't fire on individual pages. It fires on site-wide patterns. By the time you see the traffic cliff in your dashboard, the classifier has already made its call.
The teams I've watched avoid this outcome share one behavior: they treat every AI draft as a first draft, not a final draft. The generation step is fast. The review step is where the value gets added.
Does Autoblogging Actually Work for Google Rankings?
The short answer is yes, conditionally. The condition is information gain. Every piece of content your autoblog publishes needs to add something that isn't already in the search results. A specific data point, a named methodology, a first-person observation, a comparison that hasn't been made before. Without that, you're producing a paraphrase of existing results, and Google's systems are increasingly good at identifying paraphrase at scale.
Here's where I see teams get this wrong: they think information gain means length. It doesn't. A 3,000-word article that restates what ten other articles already said has zero information gain. A 600-word article with one original data point, clearly attributed and specifically formatted, can outperform it on every signal that matters in 2026. The Ahrefs study tracking AI brand visibility correlations across 75,000 brands found that branded web mentions. Not backlinks, not word count. Were the strongest predictor of AI visibility. That finding reoriented how I think about what autoblogging should actually produce: not volume, but citable specificity.
The structural problem with most autoblog pipelines is what I call answer-burial. The pipeline generates a 1,500-word article, the actual answer to the user's question is technically present. But it's sitting in paragraph four, after two sentences of topic framing and a definition nobody asked for. That works adequately for a human reader who scrolls. It doesn't work for AI context-window scanning, which skims for the most direct answer in the first retrievable chunk. If the direct answer isn't in the first 60-80 words, the piece is functionally invisible to AI retrieval regardless of how well it ranks organically. Most content templates are still structured introduction-first, payoff-later. That sequencing is actively costing AI search visibility.
How Does Google's AI Overviews Change the Calculus?
This is the part that genuinely surprised me when I dug into the data. I'd been operating on the assumption that ranking well was a reasonable proxy for AI visibility. It isn't. Ahrefs ran an analysis across 730,000 AI responses and found only 13.7% overlap between what Google's traditional search surfaces cite and what AI Overviews cite. Those are almost entirely different source pools.
That number stopped me cold.
What it means for autoblogging workflows is that you can build a pipeline that wins traditional rankings and still be architecturally invisible to AI retrieval. Not because the content failed, but because it was optimized for the wrong retrieval system. The content that gets pulled into AI Overviews tends to share specific structural characteristics: direct answers near the top, named sources with specific numbers, clear entity signals, and a consistent topical focus across the domain. An autoblog publishing 50 posts a week across 12 loosely related topics is fighting against all of those signals simultaneously.
Tracking Google AI Overviews citations separately from organic rankings isn't optional anymore. It's a different measurement problem requiring different tooling.
Why AI Citation Rates Vary So Dramatically
The citation hallucination problem compounds everything. The GhostCite benchmark tested 13 LLMs across 40 domains and found hallucination rates ranging from 14% to 95% depending on the model. That variance has a direct competitive implication for autobloggers that almost nobody talks about: a competitor can publish a thin paraphrase of your original research, and an LLM can cite their version as the authoritative source while your original goes completely unattributed.
I've started auditing this manually. Searching for core claims in Perplexity and ChatGPT to see what actually gets surfaced as the source. The results are uncomfortable. Content published first, with primary data, sometimes loses the attribution game to aggregators who published later but structured their claims more crisply. The structural fix I keep coming back to is making claims so distinctively formatted. Specific stat, named methodology, dated finding. That paraphrasing without attribution becomes harder to do cleanly. It's not a complete solution, but it's the only lever that's actually in our control. For autoblogging specifically, this means the AI generation step needs explicit prompting to produce claims in that format, not just fluent prose.
One finding from the research that cuts against a lot of agency advice: Reddit accounts for only 0.34% of AI answer citations across more than 2 million analyzed cases, ranking ninth overall. Wikipedia accounts for 17.02%. Tech publications like TechRadar, Wired, and The Verge account for roughly 2%. The implication for autobloggers chasing AI visibility through Reddit seeding is blunt: you're optimizing for a channel that contributes less than one percent of actual citations. The platforms that dominate AI citation are established publications with consistent entity signals and high topical authority. Exactly the profile a quality-gated autoblog can build over time, and exactly the profile an unfiltered content farm cannot.

Is your autoblogging workflow set up to get cited by ChatGPT and Perplexity — or just to rank on Google?
When Does Autoblogging Actually Deliver Results?
The conditions under which AI autoblog workflows produce real results are specific enough to name. I've watched this play out across enough brand content programs to say it with confidence.
First, topical focus matters more than volume. A site publishing 20 posts a month on a tightly defined topic cluster builds topical authority for AI search faster than a site publishing 200 posts across loosely related categories. The Ahrefs brand visibility study finding on branded mentions is relevant here: AI platforms cite sources they've encountered consistently in a specific domain, not sources that appeared once across many domains.
Second, content syndication has a measurable impact on AI citations. A case study across eight brands found a 325% lift in AI citations from content syndication to third-party publishers. That's a significant multiplier, and it makes intuitive sense: AI models train on and retrieve from the broader web, so a piece that appears on multiple authoritative domains creates more retrieval surface than a piece that lives only on your own site. For autoblogging workflows, this suggests that the best-performing posts. The ones that pass the quality gate. Should be actively distributed, not just published and forgotten.
Third, the niche determines the ceiling. Autoblogging works best in categories where the information is relatively stable, the user intent is specific and answerable, and first-person experience signals are achievable through editorial review. It works worst in categories where Google's E-E-A-T requirements are highest. Health, finance, legal. Where the bar for demonstrating genuine expertise is set by human reviewers, not just structural signals. Marcus's health blog worked because he was adding real editorial judgment to each post, not just publishing raw AI output.
Fourth, the ChatGPT citation tracking and Perplexity citation monitoring loops need to be closed. Most autoblogging operations measure success by organic traffic. That metric is increasingly decoupled from AI visibility. The Tow Center ran 1,600 test queries through AI search engines and found that even when publishers were cited, referral traffic was negligible. A mention in a Perplexity response is closer to a footnote in a book nobody opens than a backlink. So the question isn't just "are we ranking?" It's "are we being cited, and by which platforms?" Those are different questions requiring different measurement.
The Contrarian Take on AI Search Visibility Tools
Everyone in the GEO space is selling the idea that structured data implementation produces dramatic citation lifts. I've seen a claimed 3.2x lift in AI citation frequency from schema markup shared across multiple communities as if it's settled science. It isn't. The number almost certainly has a confounding variable baked in: sites with strong domain authority use schema AND get cited by AI platforms, but the schema isn't doing the work. The authority is. When Ahrefs tracked pages before and after schema addition, the citation lift disappeared entirely across 1,885 pages.
I made the mistake of letting that 3.2x figure influence a content infrastructure recommendation before I'd traced it back to source. The lesson I keep relearning: in GEO specifically, the practitioner data ecosystem is noisy enough that you have to pressure-test any multiplier claim against what the variable is actually isolated from.
The same skepticism applies to Claude visibility tracking and cross-platform AI citation tools. The tools that are genuinely useful right now are the ones that show you which specific pages are being cited by which AI engines. Not the ones that promise to "boost" your citation rate through opaque mechanisms. Clearscope's AI cited pages view is a reasonable example of the former: it shows you what's already working so you can replicate the pattern, rather than promising to manufacture citations through schema tricks.
Enterprise AI spending hit $13.8 billion in 2024 according to Menlo Ventures' State of Generative AI report, and the enterprise LLM market is projected to reach $71.1 billion by 2034. That capital is flowing into the platforms that are reshaping how content gets discovered. Autoblogging operations that don't account for AI retrieval in their publishing architecture are building for a distribution model that's already being displaced.
Building a Quality Gate That Actually Holds
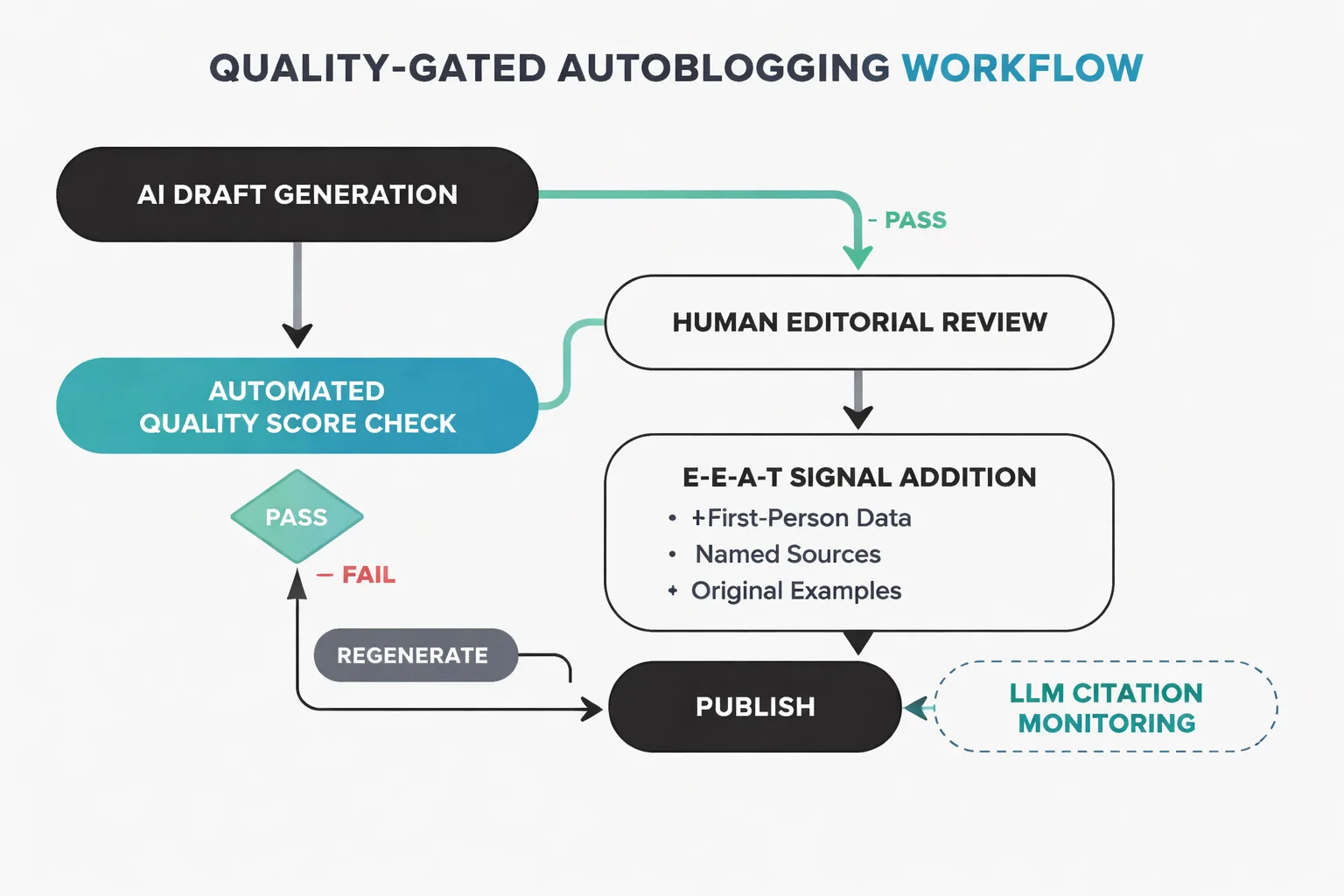
The practical implementation question is how to install an editorial checkpoint that scales without becoming a bottleneck. Here's the framework I've seen work across content programs that are running autoblogging at volume without triggering scaled content penalties.
Start with an automated quality score before any human sees the draft. The minimum viable scoring criteria are: direct answer present in first 80 words (yes/no), named source with specific number present (yes/no), topical relevance to site cluster (score 1-5), and structural uniqueness versus existing published posts (similarity score below 0.85). Posts that fail the automated screen go back to regeneration with a revised prompt. Posts that pass move to human review.
Human review at scale doesn't mean reading every word. It means verifying four things: the primary claim is accurate, the source is real, the first-person or experience signal is plausible for the brand, and the answer isn't buried. A trained reviewer can clear a post in four to six minutes with that checklist. At 20 posts a day, that's two hours of editorial time. Manageable for most content operations.
The final layer is distribution. The posts that score highest on quality metrics and pass human review should be actively syndicated, not just published. That 325% lift in AI citations from syndication is real, and it compounds: a post that appears on three authoritative domains creates three retrieval surfaces instead of one.
For teams comparing tooling options, the Meev vs Profound comparison breaks down how different AI visibility platforms handle citation tracking and quality scoring differently. Worth reviewing before committing to a measurement infrastructure.
Autoblogging works in 2026. The teams that prove it are the ones treating the quality gate as the product, not the content volume.
Frequently Asked Questions
Is autoblogging against Google's guidelines in 2026?
Unfiltered AI content published at scale with no editorial oversight is explicitly covered by Google's scaled content abuse policy. Autoblogging that includes genuine quality review, information gain, and E-E-A-T signals is not prohibited. Google's own documentation distinguishes between automation that adds value and automation that produces low-value content at volume. The line is editorial intent and output quality, not the use of AI tools.
How many posts per month is safe to publish with an autoblogging workflow?
There's no universal safe number. The relevant variable is quality per post, not volume per month. A site publishing 10 low-quality posts a week is at higher risk than a site publishing 30 quality-gated posts a week. Google's classifier evaluates site-wide patterns, so the ratio of high-quality to low-quality content across your entire domain matters more than the raw publishing cadence.
Which AI search engines are most likely to cite autoblogged content?
Perplexity and Google AI Overviews are the most citation-active platforms for publisher content right now. ChatGPT's citation behavior is less consistent and more dependent on whether the content appears in its training data or retrieval index. The Ahrefs analysis of 730,000 AI responses showed only 13.7% overlap between Google traditional search and AI Overviews sources, so tracking each platform separately is necessary. Not optional.
Does content syndication actually help autoblogged content get cited by AI?
Yes, with caveats. A case study across eight brands documented a 325% lift in AI citations from syndicating content to third-party publishers. The mechanism is straightforward: AI retrieval systems encounter the content across multiple authoritative domains, increasing retrieval surface. The caveat is that only quality-gated content benefits. Syndicating thin AI content to third-party sites creates duplicate content problems without the citation upside.
What's the biggest mistake autobloggers make with E-E-A-T signals?
Treating E-E-A-T as a checklist of structural signals. Author bios, schema markup, internal links. Rather than as a genuine demonstration of expertise. Google's quality raters are evaluating whether the content reflects real knowledge of the topic. Schema on a thin article doesn't create E-E-A-T. A named author with verifiable credentials, a specific data point that only someone with domain knowledge would include, and a direct answer that reflects genuine understanding. Those create E-E-A-T. The structural signals support the substance; they don't replace it.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
See how Meev's quality-gated publishing workflow tracks AI citations across ChatGPT, Perplexity, and Google AI Overviews — so you know which posts are actually earning visibility.