
By Judy Zhou, Head of Content Strategy
Key Takeaways
- GPTBot's share of total crawl activity jumped from 5% to 30% between May 2024 and 2025, meaning AI bot traffic now competes directly with Googlebot for your server resources and crawl budget.
- Render budget is the most underestimated of the 7 Googlebot behaviors — if your article content lives in client-side JavaScript, Googlebot may index a skeletal version that never qualifies for AI Overviews.
- Google does not differentiate crawl budget allocation between AI-generated and human-written content; crawl resources are allocated based on site health signals and PageRank-derived crawl demand, not content origin.
- Fixing crawl health is necessary but not sufficient for AI citation eligibility — pages also need strong E-E-A-T signals and Common Crawl authority metrics, which correlate with LLM citation patterns across ChatGPT and Perplexity.
"Crawl budget isn't about how often Google visits you — it's about what Google learns about you each time it does," said Gary Illyes, Google Search Advocate, during a 2023 Search Off the Record podcast episode. That distinction has never mattered more. As Googlebot search behavior increasingly feeds the training signals behind AI Overviews, Perplexity source selection, and LLM citation patterns, the seven specific behaviors governing how Googlebot allocates, extends, and withdraws crawl attention have become the hidden architecture of generative engine visibility.
Most SEO teams still treat google crawl budget as a plumbing problem — fix the 404s, submit the sitemap, move on. That framing was incomplete in 2019. In 2026, it's actively harmful. Googlebot's crawl decisions now directly influence which pages become eligible for Google AI Overviews source selection. AI crawler traffic surged 96% year-over-year, with GPTBot's share of total crawl activity jumping from 5% to 30% between May 2024 and 2025, according to Search Engine Journal's analysis of 68 million AI crawler visits across 858,457 sites. Your site now needs to satisfy both traditional search and AI systems with the same crawl budget — and the behaviors that determine how well you do that are specific, measurable, and largely fixable. Google's official crawl budget documentation states that crawl budget is not a concern for most publishers — but that guidance predates the AI Overviews era and the explosion of AI bot traffic competing for server attention.
Why Googlebot Behavior Matters More in the AI Era
The pipeline from Googlebot crawl to AI citation is less mysterious than most practitioners assume. When Googlebot successfully crawls and indexes a page, that page enters Google's index. Pages in the index are the candidate pool for AI Overviews. Pages that AI Overviews surfaces repeatedly become the training signal for what authoritative, citable content looks like — which then influences Perplexity source selection and LLM citation patterns more broadly. Disrupt the first step and you fall out of every subsequent one.
What changed recently isn't Googlebot itself — it's the competition for crawl attention. Search Engine Land noted that your site must satisfy both traditional search and AI systems with the same crawl budget, and that's where things break. GPTBot, ClaudeBot, and PerplexityBot are now competing with Googlebot for server resources. A server that's slow to respond to Googlebot because it's fielding 30% more AI crawler traffic than it was 18 months ago is a server that's quietly bleeding crawl equity — and most teams won't see it in their rankings dashboard until the damage is done.
I've watched this play out in audits where the site's Core Web Vitals looked fine in a browser but log file analysis revealed Googlebot was receiving 503s and timeouts at a rate that would never surface in Search Console's coverage report. The coverage report shows you what got indexed. It doesn't show you what Googlebot tried to crawl and gave up on.
This is also where the ai search indexing question gets genuinely complicated. Google's crawl budget documentation has not been meaningfully updated to reflect the AI Overviews era. The official guidance still says most sites don't need to worry. But "most sites" was written for a world where Googlebot was the primary crawler — not one where AI bots now represent nearly a third of crawl activity on some servers.
The 7 Googlebot Behaviors Ranked by Impact
These aren't theoretical. Each behavior has a direct, documentable effect on whether your pages enter the candidate pool for AI Overviews and generative engine citation.
1. Crawl frequency signals — Googlebot crawls pages it expects to change. Sites with consistent publish cadences, fresh content, and strong engagement signals get higher crawl frequency. For AI search indexing, this matters because AI Overviews draws from recently crawled, recently confirmed-accurate pages. A page last crawled eight months ago is not a competitive citation candidate.
2. Structured data parsing — When Googlebot encounters valid schema markup (Article, FAQPage, HowTo, Speakable), it can parse the page's semantic structure without rendering the full JavaScript. This makes structured data one of the highest-leverage signals for both crawl efficiency and AI citation eligibility. FAQPage schema in particular maps directly onto how AI Overviews constructs answer blocks.
3. Canonical resolution — Googlebot follows canonical signals to determine which version of a URL to index. Sites with canonical confusion — self-referencing canonicals on paginated content, conflicting canonical and hreflang signals, or canonicals pointing to redirected URLs — waste crawl budget on resolution loops. Every crawl cycle spent resolving a canonical chain is a cycle not spent on a new piece of content.
4. Render budget — This is the one most teams underestimate. Googlebot operates a separate render queue for JavaScript-dependent content, and that queue is slower and resource-constrained relative to the HTML crawl. If your key content — the paragraphs, the structured answers, the expert quotes — lives in JavaScript that requires client-side rendering, Googlebot may index a skeletal version of your page. That skeletal version is what AI Overviews evaluates.
5. Mobile-first indexing quirks — Google has indexed mobile-first since 2019, but the quirks are still tripping up publishers. If your mobile page lazy-loads content that's visible on desktop, Googlebot's mobile crawler may never see it. If your mobile page has a different internal link structure than desktop, Googlebot's crawl path through your site is different from what you designed. I've seen sites where entire content clusters were effectively invisible to Googlebot's mobile crawler because of aggressive lazy-loading on mobile templates.
6. Internal link depth — Pages more than three clicks from the homepage receive dramatically less crawl attention. This is where the topical authority question intersects with crawl budget: if your best, most citable content is buried in a cluster that's four or five clicks deep, Googlebot may crawl it infrequently or not at all. The pattern I keep seeing is teams that build excellent content clusters on pillar pages that haven't earned enough authority to pull crawl attention down the hierarchy.
7. Response-time thresholds — Google's crawl stats documentation suggests a 90%+ success rate for crawl requests (response code 200) as a baseline health signal. Response times above 2 seconds cause Googlebot to back off — it's designed to be polite, which means slow servers get fewer crawl attempts, not more patient ones. With AI bot traffic now representing a significant share of server load, sites that haven't scaled server capacity are hitting response-time thresholds they never encountered before.
Want to see which of your pages Googlebot is crawling — and which ones are actually earning AI citations?
How to Audit Your Site Against Each Behavior
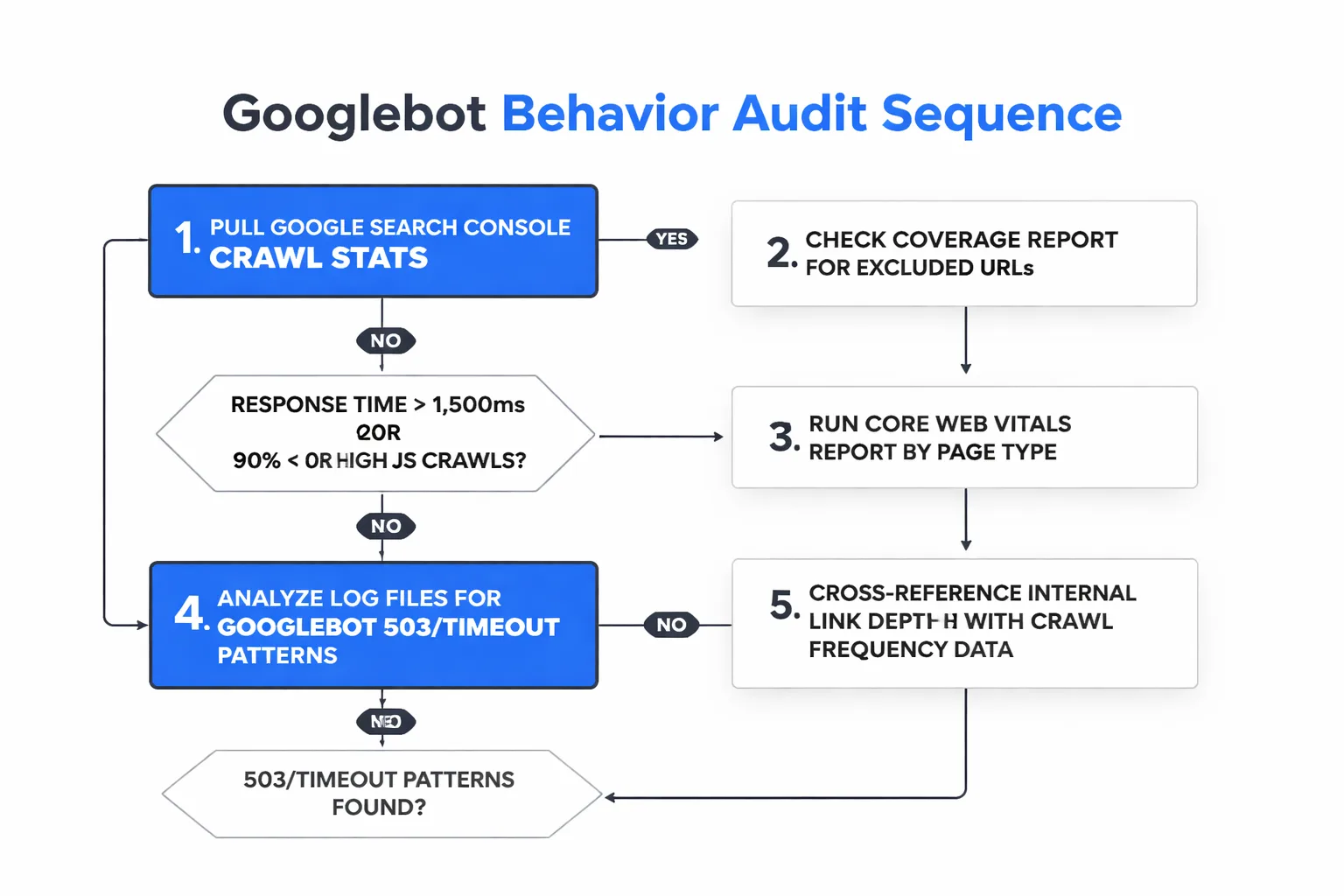
The audit sequence matters. Start with what's measurable in tools you already have before moving to log file analysis, which requires server access most content teams don't have by default.

Google Search Console crawl stats — Go to Settings → Crawl Stats. You're looking for three signals: average response time (anything above 1,500ms is a yellow flag), crawl request breakdown by response code (you want 200s above 90%), and crawl request breakdown by file type (a high proportion of JavaScript crawls relative to HTML crawls suggests render budget pressure). This is your first diagnostic layer.
Coverage report audit — Filter for "Excluded" URLs. The subcategories matter: "Crawled — currently not indexed" means Googlebot visited but didn't find the page worth indexing. That's a content quality signal, not a crawl signal. "Discovered — currently not indexed" means Googlebot knows the URL exists but hasn't gotten to it yet — that's a crawl budget signal. If you have hundreds of URLs in the second category, you have a crawl budget problem.
Core Web Vitals by page type — Run the Core Web Vitals report segmented by page template (blog posts, category pages, product pages). A template-level LCP problem is a crawl efficiency problem at scale. Googlebot's render budget is affected by page weight and render complexity in ways that parallel real-user experience.
Log file analysis — This is where the real signal lives, and it requires either server log access or a tool like Screaming Frog Log File Analyser. What you're looking for: Googlebot 503 responses (server unavailable), Googlebot timeouts (no response logged), and the ratio of Googlebot crawl attempts to successful 200 responses by page type. I use Screaming Frog crawl audits at regular intervals — specifically watching for pages that are more than 3 clicks from the homepage and pages accumulating inbound internal links without corresponding crawl frequency improvement.
Cross-reference with AI citation tracking — This is the step most technical SEO audits skip entirely. Once you've identified which pages Googlebot crawls frequently and successfully, cross-reference that list against which pages actually get cited in AI Overviews or LLM responses. The gap between "well-crawled pages" and "cited pages" tells you whether your crawl health is translating into generative engine visibility — or whether there's a content quality problem that crawl optimization alone won't fix. Tools built for AI search visibility can surface this gap in ways Search Console can't.
One uncomfortable truth I've had to sit with: a page can be crawled perfectly — fast response, clean canonical, valid structured data — and still generate zero AI citations. Perplexity source selection and ChatGPT citation patterns correlate with Common Crawl authority metrics like PageRank and Harmonic Centrality, according to SEO consultant Cyrus Shepard. Crawl health is necessary but not sufficient. It's the floor, not the ceiling.
Quick Wins vs. Long-Term Fixes
Not all seven behaviors are equally fast to address. Here's the honest breakdown.
Fix in a day:
Sitemap hygiene — Submit an XML sitemap that includes only canonicalized, indexable URLs returning 200 responses. Remove paginated URLs, filtered URLs, and any URL with a noindex directive from the sitemap. A sitemap full of excluded URLs is actively misleading Googlebot about where your crawl budget should go. This is a 2-hour fix with meaningful crawl budget impact.
robots.txt audit — Check that you're not accidentally blocking Googlebot from CSS, JavaScript, or API endpoints it needs to render your pages. A misconfigured robots.txt that blocks /wp-content/ or /assets/ is one of the most common causes of render budget failure I see in audits. Also confirm you're not blocking GPTBot if you want AI citation eligibility — Google's documentation treats Googlebot and AI crawlers differently, but blocking GPTBot removes you from LLM training data pipelines.
Canonical cleanup — Audit for self-referencing canonicals on paginated pages, canonical tags pointing to redirected URLs, and conflicting canonical/hreflang combinations. Tools like Screaming Frog surface these in under an hour on most sites.
Fix in a sprint (1-2 weeks):
Structured data implementation — Adding FAQPage, Article, and Speakable schema to existing content is a template-level change on most CMS platforms. One engineering sprint covers the template; the content team handles the FAQ markup per article. The generative engine optimization payoff here is direct: FAQPage schema is the most extractable format for AI Overviews answer blocks.
Internal link depth audit — Identify pages more than 3 clicks from the homepage using Screaming Frog, then prioritize the ones with the highest content quality scores for internal link injection. This is an editorial task, not an engineering one, but it requires a systematic audit first.
Fix in an engineering cycle (4-8 weeks):
Render budget — Moving key content from client-side JavaScript to server-side rendering or static HTML is an architectural change. It's the highest-impact fix on this list and the slowest to ship. If you're on a JavaScript-heavy framework, prioritize SSR for article body content specifically — that's what AI Overviews evaluates.
Server response time — Improving p95 response times for Googlebot requires infrastructure work: CDN configuration, server capacity scaling, database query optimization. The target is under 200ms for HTML responses. With AI crawler traffic now representing a significant share of server load, teams that haven't revisited their server capacity since 2023 are likely running hotter than they realize.
The contrarian take I'll make here: most teams should fix their render budget before they touch their internal linking structure. Internal linking is an amplifier — it accelerates signal that already exists. If Googlebot is getting a skeletal JavaScript-rendered version of your content, adding more internal links to that page amplifies a weak signal. Fix what Googlebot actually sees first, then amplify it.
For teams comparing AI search visibility tools to help prioritize these fixes, the key differentiator to look for is whether the platform can connect crawl health data to actual citation rates — not just monitor one or the other in isolation.
FAQ
Does Google differentiate crawl budget allocation between AI-generated and human-written content? No — and this is a common misconception worth correcting directly. Google's official crawl budget documentation makes no distinction between AI-generated and human-written content in how it allocates crawl resources. Crawl budget is allocated based on site health signals (response time, crawl errors, page quality) and PageRank-derived crawl demand — not content origin. The sites that get penalized under Google's scaled content abuse guidelines aren't penalized at the crawl level; they're penalized at the indexing and ranking level after Googlebot has already visited.
How do I know if AI bot traffic is affecting my Googlebot crawl performance? Pull your server logs and filter by user-agent. Compare Googlebot response times and success rates (200 vs. 503/timeout) in periods before and after May 2024, when AI crawler traffic began its significant surge. If Googlebot's average response time increased or its 503 rate rose without a corresponding change in your content or infrastructure, AI bot competition for server resources is a likely contributor. The fix is server capacity scaling, not robots.txt blocking of AI crawlers (which removes you from LLM training pipelines).
Is there a confirmed 'information gain' threshold score that triggers Googlebot prioritization? No confirmed threshold exists. The information gain concept derives from a Google patent application, not implemented documentation. Semrush's analysis describes it as a metric Google "may use" — and Animalz frames it as theory that became popular among SEO practitioners without official confirmation. What is confirmed: pages with unique, differentiated content earn higher crawl frequency over time as engagement signals accumulate. Treat information gain as a content quality principle, not an optimization target with a specific score.
Can fixing crawl budget issues directly improve my AI Overviews inclusion rate? Indirectly, yes — but crawl health is necessary, not sufficient. AI Overviews draws from Google's index, so pages that aren't crawled and indexed can't be included. But inclusion also depends on content quality, E-E-A-T signals, and topical authority. Teams I've seen improve their crawl health without improving content quality see better indexing coverage but not necessarily better AI citation rates. The two levers need to move together.
What's the fastest way to check if Googlebot is rendering my pages correctly? Use Google Search Console's URL Inspection tool and select "Test Live URL" → "View Tested Page" → "Screenshot." This shows you exactly what Googlebot's renderer sees. If the screenshot shows missing content, broken layout, or a loading spinner where your article body should be, you have a render budget problem. Cross-reference with the "More Info" tab to see which resources Googlebot couldn't load — that's usually where the robots.txt block or CORS issue is hiding.
How often should I run a crawl budget audit? Quarterly at minimum for sites publishing more than 50 articles per month. Monthly if you're running an active content scaling program. The signal to watch between audits isn't rankings — it's the ratio of "Discovered — currently not indexed" to total submitted URLs in Search Console. If that ratio is growing, your crawl budget is not keeping pace with your publishing rate, and you need to either slow publication or fix the underlying crawl health issues before adding more content.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Meev tracks AI citations across ChatGPT, Claude, Gemini, Perplexity, and Grok — and maps each article to the citation-rate delta it drove. Stop guessing which crawl fixes are working.





