
By Judy Zhou, Head of Content Strategy
Key Takeaways
- Only 14% of top cited sources overlap across ChatGPT, Perplexity, and Google AI Overviews, so tailor GEO strategies to each platform's unique citation preferences.
- Use bullet-pointed, structured pages over narrative prose, as Claude cites them 30% more frequently.
- Publish intentionally on Reddit to capture Perplexity citations, which draw 46.7% of top sources from the platform.
- Earn AI mentions with structured data, third-party editorial backlinks, and detailed comparisons on authoritative domains, not just Google traffic.
Marcus, a content director at a mid-sized SaaS company, ran the same query through ChatGPT every Monday morning: a question his ideal customers asked constantly. For six months, three competitors appeared in the response. His brand never did — despite outranking all three on Google. One afternoon he finally dug into why. The competitors had structured data, third-party editorial mentions, and detailed comparison coverage on authoritative domains. His site had traffic. There's a difference, he realized, between being found and being trusted enough for an AI to stake its answer on you.
That story captures the central problem with how most teams approach AI mentions 2026: they're still playing an SEO game on a GEO board. The rules changed. The scoring changed. The sources AI engines trust changed. And most content teams haven't caught up.
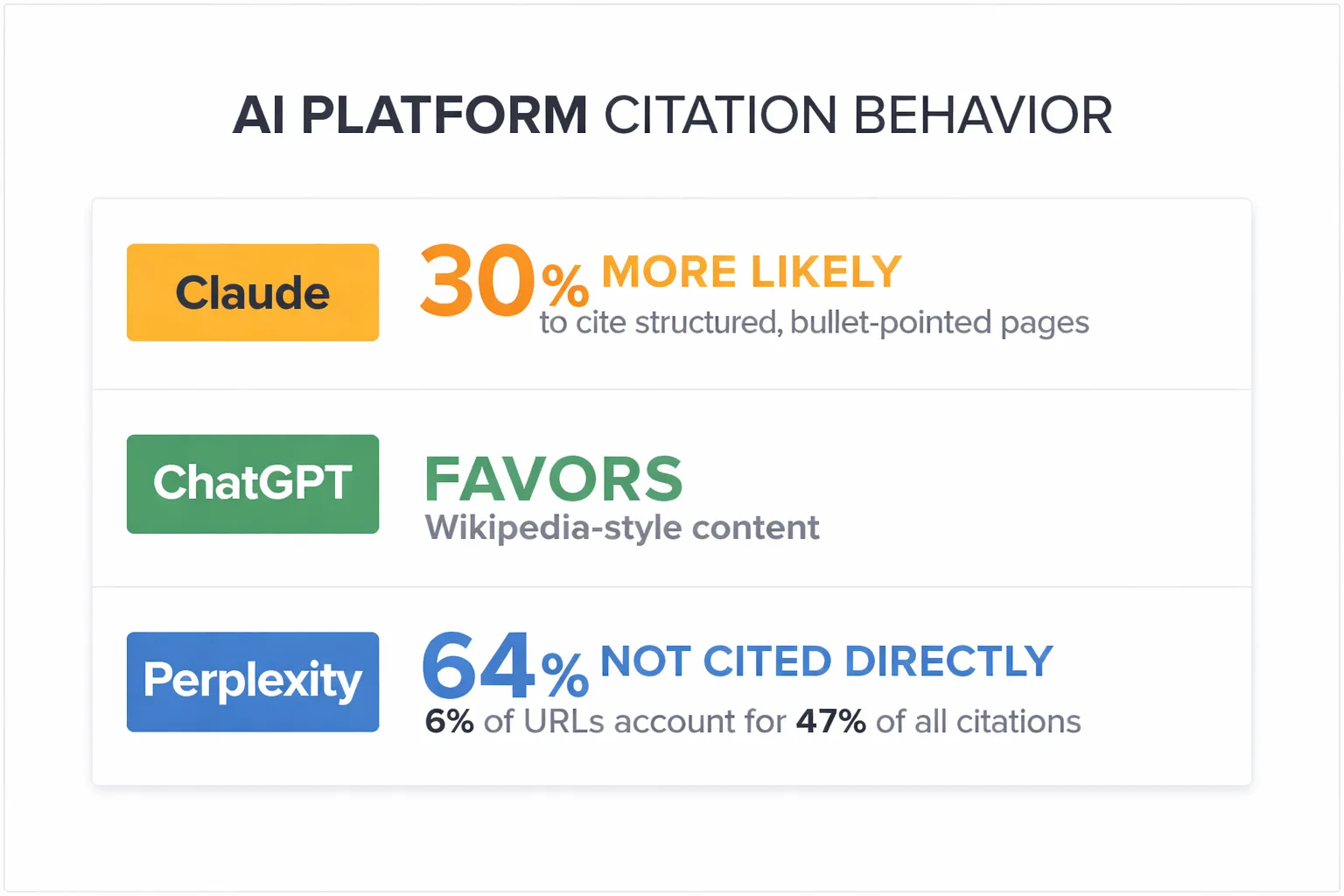
Generative Engine Optimization 2026 is not a rebrand of SEO. It requires a fundamentally different content architecture, a different distribution theory, and a different way of thinking about what "authority" means to a language model. According to Discovered Labs' cross-platform citation analysis, there is only 14% overlap in the top cited sources across ChatGPT, Perplexity, and Google AI Overviews — meaning a strategy built for one platform statistically misses the other two 86% of the time. Claude is 30% more likely to cite bullet-pointed, structured pages than narrative prose. Perplexity pulls 46.7% of its top citations from Reddit — a platform most brand content teams have never published on intentionally.
These aren't edge cases. They're the operating reality of LLM optimization 2026.
As someone who leads content strategy across hundreds of brands at Meev, I've watched teams spend significant budget on link-building programs and editorial outreach that moved Google rankings but did nothing for AI citation rates. The disconnect is real, and it's fixable — but only if you stop borrowing the SEO playbook wholesale.
Here are the five strategies that actually move the needle.
The Mention-Citation Gap Is Your Biggest Problem
Before the strategies, one diagnosis. Most teams conflate being mentioned with being cited. They're different outcomes with different causes.
A mention is when an AI engine references your brand or product in a response. A citation is when the engine attributes a specific claim, fact, or recommendation to your content as a source. Citations are harder to earn and far more valuable — they signal that the model treats your content as a trusted reference, not just a brand name it recognizes.
The gap between the two is where most GEO programs fail. I've seen brands with strong mention rates — AI engines know they exist — but near-zero citation rates because their content isn't structured for extraction. The AI can name you. It just won't stake a claim on you.
Closing that gap is what all five strategies below are designed to do.
Strategy 1: Build for Corpus Presence, Not Just Crawlability
The framing I keep pushing back on internally is that prestige placement drives AI visibility. It doesn't — at least not in the way we assumed.
ChatGPT cites Wikipedia in 7.8% of its citations. Reddit accounts for 11.97% of citations. Legacy media outlets like WSJ and Bloomberg don't crack the top 20. That's not an editorial authority story. It's a corpus presence story. The content that gets cited was present in the pre-training data at scale, in formats that language models could parse and pattern-match against.
The implication is uncomfortable: the link-building playbook borrowed from SEO is largely irrelevant to GEO. What appears to matter is whether your content format and structure were present in the training data — not whether a prestigious editor decided to cite you afterward.
So what does building for corpus presence actually mean in practice?
First, it means publishing at a cadence that keeps your content indexed and refreshed across the sources LLMs actually train on. That includes your own domain, but also community platforms (Reddit, Quora, LinkedIn), third-party review sites, and industry wikis. Second, it means structuring content so it's machine-readable at the sentence level. Dense paragraphs of narrative prose are beautiful for human readers and nearly invisible to retrieval systems. Short declarative sentences, labeled data points, comparison tables, and definition blocks are what LLMs pattern-match against when constructing answers.
I've started treating corpus presence as a distribution channel in its own right. It's a strange sentence to write — but it's the right mental model for 2026.
How Does Platform-Specific Formatting Change Citation Rates?
This is where most GEO guides stop at the surface level. They tell you to "optimize for AI search" without acknowledging that ChatGPT, Perplexity, Claude, and Google AI Overviews each have meaningfully different retrieval logic.
According to Discovered Labs' citation analysis, Claude is 30% more likely to cite structured, bullet-pointed pages than narrative prose. ChatGPT shows consensus-favoring behavior, pulling heavily from Wikipedia-style content. Perplexity's citation distribution is the most extreme: research from Peec AI analyzing over 1 million AI citations found that 64% of URLs aren't cited directly at all, while just 6% of URLs account for 47% of all citations. That's a winner-take-most dynamic, not a long tail.
For Claude visibility specifically, the formatting prescription is clear: break your content into labeled sections, use tight bullet structures for key claims, and front-load your most extractable data in the first 200 words. Claude appears to weight structural clarity heavily when deciding what to surface.
For Perplexity citations, the picture is different. Perplexity leans on real-time and community sources — Reddit at 46.7% of top citations is not a fluke. It means that for categories where community discussion exists, your brand needs a presence in those conversations, not just on your own domain. That's a content distribution shift, not just a formatting one.
For Google AI Overviews, the dynamic is closer to traditional SEO — Google AI Overviews maintain 54% overlap with traditional organic rankings, per the Discovered Labs analysis. That's the highest platform-organic overlap of the three, which means E-E-A-T signals and structured data still carry weight here in a way they don't for ChatGPT.
I made the mistake early on of building a citation strategy almost entirely around Google AI Overviews because that's where our clients had visibility data. We assumed performance would transfer across platforms. It didn't. The 14% overlap figure hit hard when I finally looked at it directly.
The practical takeaway: pick one platform as your primary target based on where your audience actually searches. Build platform-specific formatting for that primary target first. Then expand. Spreading effort evenly across all three without platform-specific formatting is dilution, not strategy.

Strategy 2: Treat Every Article as Two Documents
This is the most operationally uncomfortable shift I've asked editorial teams to make — and the one with the clearest citation impact.
A high-priority article needs to work as two documents simultaneously: the narrative layer for human readers, and an embedded data layer for LLM retrieval. Most content teams build one. The narrative layer is what they're trained to produce. The data layer — comparison tables, labeled definition blocks, numbered findings with specific numbers, FAQ sections with question-shaped headers — is what gets extracted.
We had a client with a strong B2B publishing operation: high domain rating, genuine expert authors, well-written content. They were consistently getting outperformed in Perplexity and ChatGPT responses by a competitor with a fraction of their backlink profile. When we pulled the competitor's content, it was almost aggressively boring. Dense comparison tables. Tightly labeled data points. Almost no narrative prose. Structurally, it was machine-readable in a way our client's content wasn't.
LLMs aren't rewarding storytelling. They're pattern-matching against parseable structure.
The fix isn't to strip out the narrative. It's to embed the data layer inside it. Every article that targets a citation-worthy claim should have: a bolded definition or thesis in the first 200 words, at least one comparison table or numbered list of findings, a FAQ block with question-shaped headers that mirror how users phrase queries to AI engines, and a closing summary with specific, attributable claims. That structure serves both audiences. The human reader gets the narrative. The retrieval system gets the extraction points.
For teams using ChatGPT visibility tracking, the data layer approach shows up clearly in what gets pulled into responses: ChatGPT preferentially extracts from structured, early-in-page content. Getting that structure right is not optional.
Wondering which AI engines are actually citing your content right now — and which competitors are getting cited instead?
Why Does Publisher and Community Outreach Still Matter?
Here's the contrarian take: publisher outreach for AI citations is not about backlinks. Teams that run it as a link-building program will be disappointed. Teams that run it as a corpus-seeding program will see results.
The distinction matters. A backlink from a high-DA publication tells Google's PageRank algorithm something. It tells ChatGPT's pre-training corpus almost nothing — because the model was trained on data that existed before most of those links were built. What corpus seeding means in practice is getting your brand's claims, data points, and positions represented on the sources that LLMs actually train on and retrieve from: Wikipedia, Reddit, Quora, third-party review aggregators, and independent editorial sites that have strong corpus presence.
We spent a quarter building a structured outreach program specifically designed to get journalists and publishers linking to our content. The theory was that more inbound links would translate into more ChatGPT citations. It didn't move the needle. What actually worked was a parallel program: getting our data cited in Reddit threads, contributing substantive answers to Quora questions in our category, and pitching independent bloggers with specific, citable statistics from our research rather than asking for coverage.
The earned media targeting feature in tools like Peec AI — which converts competitor citation source data into a PR pitch list — is the right mental model for this. You're not pitching for coverage. You're pitching for corpus presence on the specific sources that AI engines treat as trusted in your category.
One more point on community platforms: Reddit's 46.7% share of Perplexity's top citations is not something you can ignore if Perplexity is where your audience searches. That means contributing substantively to relevant subreddits, not spamming links. The content needs to be genuinely useful — which is a higher bar than most brand content teams are used to clearing in community spaces.
Strategy 3: Quality-Gate Before You Publish
The Google Helpful Content system is the most direct signal that content quality scoring affects AI visibility, not just traditional rankings. Content that fails the helpful content assessment doesn't just rank lower — it's less likely to be present in the training and retrieval data that AI engines draw from.
But quality-gating isn't just about avoiding penalties. It's about ensuring your content clears the bar that LLMs apply when deciding what to cite. That bar is higher than most teams assume. A page that ranks on page one of Google for a keyword can still be machine-illegible — too narrative-heavy, too vague, too light on specific attributable claims.
The quality dimensions that matter for AI citation are different from the ones that matter for traditional SEO. For LLM retrieval, the relevant signals include: specificity (named sources, specific numbers, attributable claims), structural clarity (labeled sections, comparison tables, definition blocks), information gain (does the page say something that isn't already in the first five Google results?), and E-E-A-T signals (named author with credentials, first-person experience signals, primary research).
Information gain is the one most teams underweight. If your content is a synthesis of what's already widely known, an LLM has no incentive to cite it — the model already has that information. What earns citations is proprietary data, original analysis, or a specific framing that the model can't reconstruct from its existing training. That's a high bar. It means every high-priority article should contain at least one thing that isn't already in the training corpus: a survey result, a case study outcome, a named comparison, a specific benchmark.
At Meev, we gate every article against a 12-dimension Quality Matrix before it ships. The 70/100 publish threshold exists precisely because content that doesn't clear it tends not to earn citations — regardless of how well it's distributed. Avoiding scaled content abuse isn't just about staying on Google's good side. It's about not flooding your domain with low-information pages that dilute the citation signal from your genuinely strong content.
How Do You Measure AI Search Visibility Accurately?
This is where I want to be honest about the current state of the tooling.
My working assumption for any AI search visibility tool evaluation right now: treat the score as a sentiment proxy, not a traffic predictor — until someone shows you the methodology connecting the two. The platforms I've looked at most closely don't share a conversion framework for translating citation or mention data into expected referral behavior from AI answer engines. That gap matters enormously for budget justification.
What I'd want before recommending any tool to a content team: show me a correlation between score movement and GA4 LLM-sourced sessions over at least a 90-day window with disclosed sample sizes. Right now, that published comparison doesn't exist. The buyer's guides exist. The vendor comparisons exist. But the traffic correlation data either isn't there or isn't disclosed.
That said, measurement still matters — even imperfect measurement. The platforms doing the most rigorous work on multi-platform citation tracking are the ones worth evaluating. The key dimensions to assess: how many AI engines are tracked (and whether they include ChatGPT, Claude, Gemini, Perplexity, and Grok), whether citation data is URL-level or just domain-level, whether the platform tracks Google AI Overviews separately from other AI engines, and whether there's any closed-loop attribution connecting content actions to citation rate changes.
For teams choosing between platforms, Meev's comparison with Profound breaks down the specific differences in tracking methodology and pricing — useful if you're evaluating enterprise-tier options. For teams comparing content-generation approaches alongside visibility tracking, Meev vs. Sight AI covers the quality-gating difference in detail.
One thing the Ahrefs study of 75,000+ brands across multiple AI search engines reinforces: topical authority — owning a specific subject area deeply rather than covering everything shallowly — is the strongest predictor of consistent citation across platforms. That's a content strategy decision, not a tool decision. No platform can manufacture topical authority for you.
Strategy 4: Own a Specific Answer Set
Topical authority for AI search is not the same as topical authority for Google. For Google, topical authority means covering a subject area broadly with many pages that interlink. For AI citation, it means being the most specific, most structured, most attributable source for a defined set of questions that users actually ask AI engines.
The practical version of this: identify the 10-15 questions your target audience asks AI engines most frequently in your category. Build a page that is the definitive answer to each one — not a broad overview, but a tight, structured, citation-ready response. Each page should have a bolded 40-60 word direct answer at the top, a comparison table or data layer in the middle, and a FAQ block at the bottom. That structure maximizes extraction probability across all four major platforms.
This is different from a content calendar built around keyword volume. The questions that get asked to AI engines are often longer, more specific, and more conversational than the queries that drive Google traffic. "What's the best CRM for a 10-person sales team that integrates with HubSpot" is an AI query. "Best CRM" is a Google query. The content that earns citations answers the AI query — with specificity, with named comparisons, with a clear recommendation backed by attributed data.
For teams using content generation tools to scale this approach, the quality-gating requirement doesn't go away. The risk with AI-generated content at scale is not that it's AI-generated — it's that it tends toward the generic, the synthesis-heavy, and the information-poor. Meev vs. Jasper AI and Meev vs. Copy.ai both address this directly: the differentiator isn't generation speed, it's whether the output clears the quality threshold that earns citations rather than just filling pages.
Strategy 5: Close the Loop Between Content and Citation Rate
The final strategy is the one most teams skip because it requires measurement infrastructure they don't have yet.
Every piece of content you publish targeting AI citations should be mapped to a citation-rate delta. Did publishing this article increase the frequency with which your brand appears in AI responses to the target query? Did it move from zero citations to occasional, or from occasional to consistent? Without that loop, you're publishing into a black box and hoping.
The measurement approach doesn't have to be sophisticated to be useful. At minimum: track a defined set of 20-30 prompts that represent your target queries across your primary AI platform. Run those prompts weekly. Record whether your brand is cited, and whether your content is the attributed source. Track the delta over 90 days following each new publication.
That's a manual process at small scale. At larger scale, it's what AI search visibility platforms are built for — but as I noted above, the connection between visibility scores and actual traffic outcomes is still not well-documented publicly. Use the scores as directional signals, not as KPIs you'd report to a CFO.
The closed-loop question — which specific content action drove which citation-rate change — is the hardest problem in GEO measurement right now. It's also the most important one. Teams that solve it, even imperfectly, will outperform teams that are still treating AI visibility as a vanity metric.
Frequently Asked Questions
How long does it take to start earning AI citations after publishing new content?
For platforms with real-time retrieval like Perplexity, citation pickup can happen within days of indexing. For ChatGPT, which relies more heavily on pre-training data, new content may take months to influence citation patterns — and may not appear until a model update incorporates it. Google AI Overviews typically reflects indexing within weeks, given its closer relationship to traditional crawl cycles. Plan for a 60-90 day measurement window before drawing conclusions.
Does domain authority still matter for AI citation rates?
Less than most teams assume. The citation data consistently shows that structural clarity, corpus presence, and content specificity outperform domain authority as citation predictors. A well-structured page on a mid-authority domain will often outperform a narrative-heavy page on a high-authority domain. Domain authority still matters for Google AI Overviews (which maintains 54% overlap with organic rankings), but it's a weak signal for ChatGPT and Perplexity.
Should I be optimizing for all AI platforms simultaneously?
Not at first. The 14% overlap in top cited sources across ChatGPT, Perplexity, and Google AI Overviews means platform-specific optimization is more effective than a unified strategy. Pick the platform where your audience searches most frequently, build for its specific retrieval logic, measure citation rate movement over 90 days, then expand to a second platform. Spreading effort evenly without platform-specific formatting is dilution.
What's the difference between GEO and AEO in 2026?
Generative Engine Optimization (GEO) focuses on earning citations in AI-generated answers across LLMs broadly — ChatGPT, Claude, Gemini, Perplexity. Answer Engine Optimization (AEO) is the narrower practice of optimizing for featured snippets and direct-answer boxes, historically associated with Google. In 2026, the two have largely converged in practice: the structural techniques that earn AEO placement (concise direct answers, question-shaped headers, FAQ blocks) are the same ones that improve GEO citation rates. Most practitioners now use the terms interchangeably, though GEO implies a broader multi-platform scope.
How do I know if my content has an information gain problem?
A quick diagnostic: take your article's main claim and run it as a query in ChatGPT or Perplexity. If the AI's response already covers your content completely without citing you, your content has no information gain. The AI already has what you wrote. To earn a citation, your content needs to contain something the model can't reconstruct from its existing training — proprietary data, original analysis, a named case study, or a specific benchmark with attribution. If your content is a synthesis of publicly available information, it will not earn citations consistently.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Track your AI citations across ChatGPT, Claude, Perplexity, Gemini, and Grok — and publish quality-gated content that earns them. Start your 7-day free trial of Meev, no credit card required.