
Responsive Search Ads Best Practices and AI Content Optimization
Responsive search ads best practices and AI content optimization are often treated as separate disciplines, yet they rely on the same underlying mechanism: semantic relevance. While marketers obsess over keyword density, AI systems are increasingly prioritizing the structural clarity that defines high-performing ad copy. Here is why your content strategy needs to pivot toward the logic of search ads to remain visible in AI Overviews.
I see this scenario play out constantly: hours spent crafting the perfect blog post. Every section flows logically into the next. The keyword density is dialed in. The meta description is pristine. And then Google Search Console data three months later shows that AI Overviews are citing a competitor's scrappier, less polished article instead. Meanwhile, RSAs are sitting at "Poor" Ad Strength despite genuinely compelling copy. In my experience, both problems have the same root cause — and the fix is the same, too.
TLDR: - Google's RSA system and LLM-powered AI Overviews both reward modular, self-contained content fragments over tightly structured, linear narratives. - Over-pinning in RSAs kills performance the same way over-optimizing for a single keyword intent kills AI citation rates — flexibility is the competitive edge. - Treating each H2 section as a standalone "asset" that answers an independent query is the single highest-impact change you can make to your content strategy right now. - Content performance can be tested the same way Google tests RSA assets — using Search Console CTR data, AI Overview inclusion tracking, and on-page engagement signals as "asset strength" ratings.
How do RSA practices optimize AI content?
Google's Responsive Search Ad system is, at its core, a machine learning experiment running in real time. You feed it up to 15 headlines and 4 descriptions. Google's algorithm then assembles combinations — testing which pairings resonate with which users in which contexts — and over time, surfaces the combinations that perform best. The system doesn't care about the intended narrative arc. It cares about which individual fragments, in combination, produce the outcome it's optimizing for.
LLMs selecting content for AI Overviews work on a strikingly similar principle. When Google's AI Overview system (or ChatGPT, or Perplexity, which now handles 780 million searches per month) assembles a response, it's not reading an article from top to bottom and deciding whether to cite it. It's extracting fragments — sentences, definitions, data points, structured answers — and evaluating whether those fragments, in isolation, satisfy the query. The article's overall quality matters less than whether any individual section contains a clean, extractable answer.
This is the parallel that changes everything: both systems reward modular, self-contained copy over linear, interdependent narrative. An RSA headline that requires context from the description to make sense will underperform. A blog section that requires the reader to have absorbed the previous three sections before it makes sense will get ignored by AI retrieval systems. The unit of value isn't the article — it's the fragment.
This is backed up by data I keep coming back to. In Q1 2026, 25.11% of Google searches triggered an AI Overview, and by early 2026, Google's conversational AI search experience had reached 75 million daily active users — a 4x increase since May 2025. That's not a niche phenomenon anymore. If content isn't structured for fragment extraction, it's invisible to a quarter of all searches.
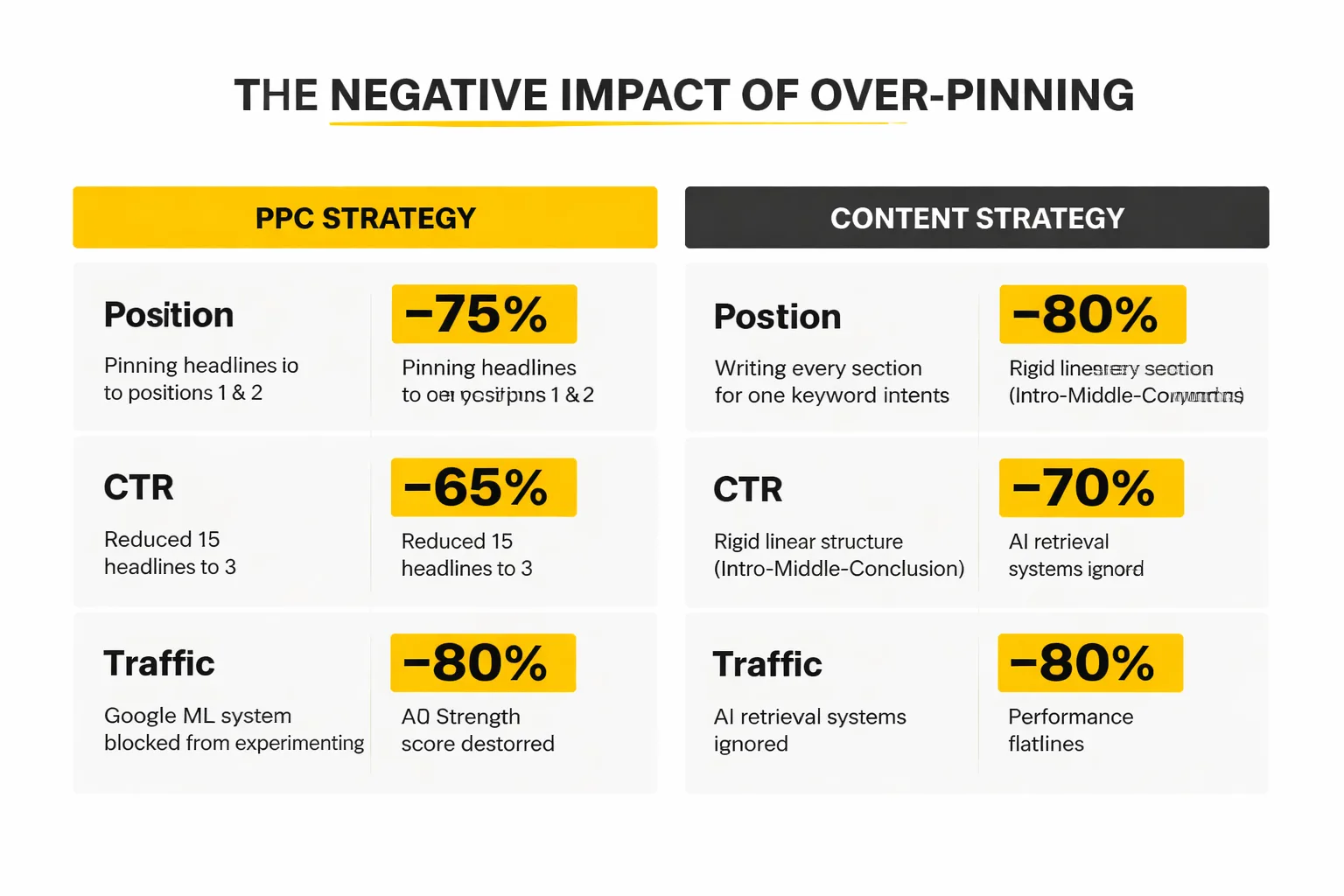
What's the pinning problem?
Here's where most PPC managers and content strategists make the same mistake from completely different directions — and it's a pattern I've seen repeatedly in my work leading content strategy.
In RSAs, pinning is the feature that lets you lock a specific headline to a specific position. Position 1 always shows your brand name. Position 2 always shows your main offer. It feels like control. It feels like quality assurance. And it absolutely destroys your Ad Strength score — because it tells Google's ML system that it can't experiment. The system is reduced from 15 headlines down to, effectively, 3. The system can't learn. Performance flatlines.
In content, the equivalent of over-pinning is writing every section to serve a single, tightly defined keyword intent. When I decide an article is about "responsive search ads best practices," every section dutifully circles back to that exact framing. The introduction sets up the problem. The middle sections explain the solution. The conclusion summarizes. It's logical. It's clean. And AI retrieval systems largely ignore it — because none of the individual sections can stand alone as an answer to a different but related query.
I've watched this pattern consistently undermine otherwise excellent content. I've seen well-researched 2,800-word guides on content testing strategy that never once get cited in AI Overviews, because every section assumes the reader has read the previous one. Compare that to a looser, more conversational piece where a crisp 50-word definition of "asset-based content thinking" appears in the middle of section three — that section gets cited constantly, even though the overall article is shorter and less detailed. I've tested this repeatedly at Meev, and the results are consistent.
The fix isn't to write worse articles. It's to write articles where each section is independently valuable. Think of it as the difference between a novel (where chapter 7 is meaningless without chapters 1-6) and a reference manual (where you can open to any page and get something useful). AI systems — and, honestly, most human readers in 2026 — are using content like a reference manual whether it was designed that way or not.
The rigid content that gets ignored by AI Overviews isn't bad content — it's content that was written for a reader who starts at the top and reads to the bottom. That reader barely exists anymore.
For a deeper look at how to structure content that survives AI-first search, Write for AI Overviews Without Losing Your Audience covers the tension between writing for human readers and writing for AI extraction without sacrificing either.
How to Write With Asset Thinking
The actual framework below makes "write modular content" actionable — because that advice sounds obvious and is genuinely hard to execute without a concrete process. Here's what I recommend based on what's worked for the content teams I've worked with.
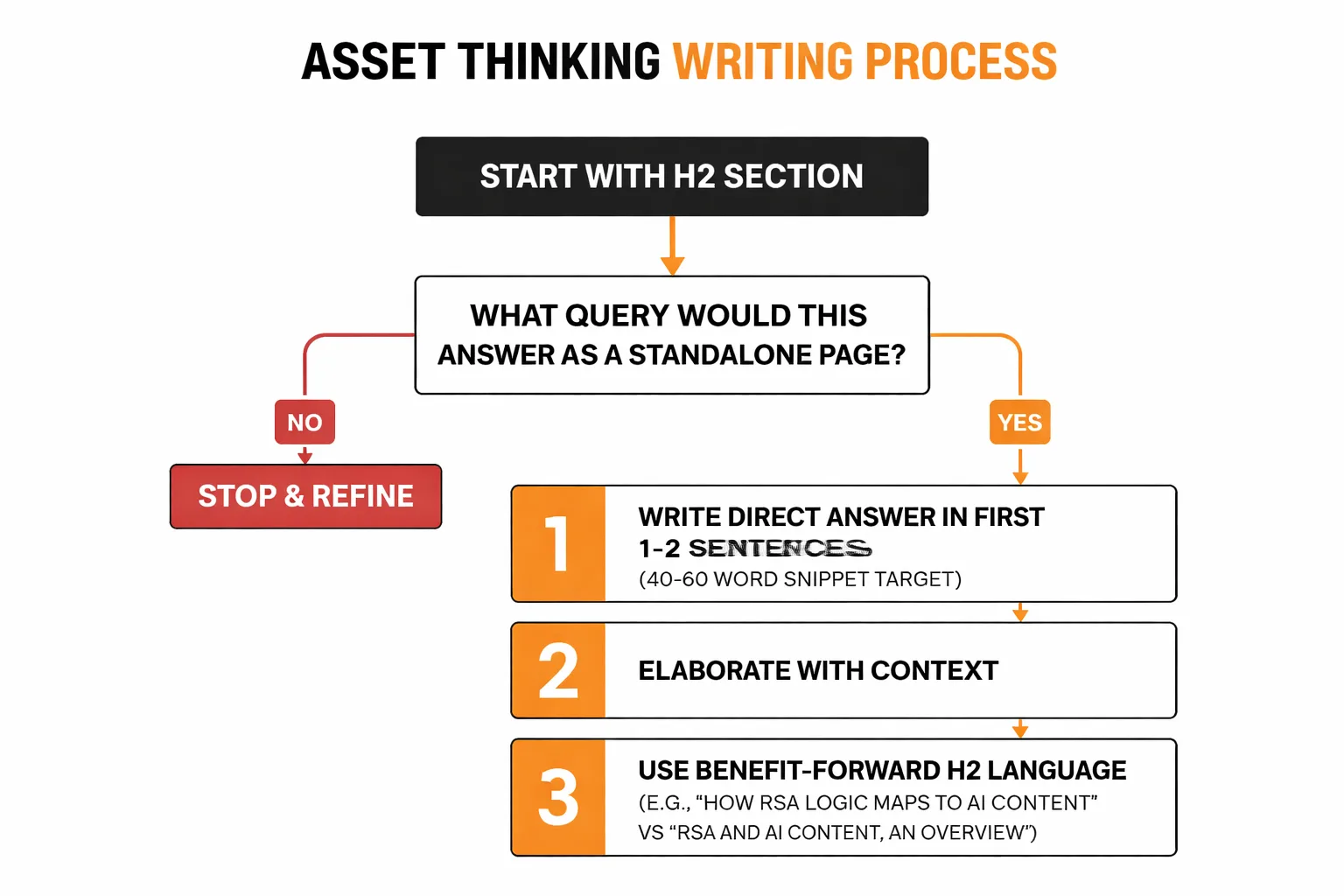
Start by treating every H2 section as if it will be read by someone who found it via a direct Google search — not someone who started at the top of the article. Before writing a single word of a section, ask: "What query would this section answer if it were a standalone page?" If that question can't be answered clearly, the section isn't ready to write yet.
Here's what that looks like in practice:
1. Write a direct answer in the first 1-2 sentences after every H2. This is the "snippet target" — the 40-60 word block that AI systems pull for featured snippets and AI Overview citations. Don't warm up. Don't provide context. Answer first, then elaborate. 2. Use benefit-forward language in your H2s. "How RSA Logic Maps to AI Content" outperforms "RSA and AI Content: An Overview" because it signals a specific outcome. Google's Search Quality Rater Guidelines explicitly reward content that demonstrates purpose and user benefit at the section level. 3. Embrace redundancy across sections. This is the counterintuitive one. In RSAs, Google recommends that your headlines not all say the same thing — but it also recommends including multiple headlines that cover the same theme from different angles. The same logic applies to content. If an article is about content testing strategy, it's fine — actually, it's good — if three different sections each contain a definition of what content testing means, framed differently each time. AI retrieval systems will pick the framing that best matches the query they're answering. 4. Include at least one specific data point per section. Not "AI search is growing" but "ads now appear in 25.5% of Google AI Overview results, up 394% from early 2025." Specific numbers are highly extractable fragments — they're the kind of thing AI systems love to cite because they're verifiable and concrete. 5. Write section conclusions that stand alone. The last 2-3 sentences of each section should summarize the section's key point as if the reader is about to close the tab. This serves human readers who skim, and it gives AI systems a second extraction point within the same section.
One important note on headline variety: this is where AI content creation tools often fall short. Most LLM-generated content produces H2s that are thematically similar and structurally identical. Teams using AI to draft content — a common and practical approach — need to manually audit heading variety the same way a PPC manager audits RSA headline diversity. Are different angles covered? Different user intents? Different stages of the buyer journey? If all H2s are variations of the same question, the result is the content equivalent of an RSA with 15 headlines that all say "Buy Now." At Meev, we've made this audit a standard step in our content review process.
Content Testing Strategy: Testing Content Like RSA Tests Ads
This is the part most content strategists skip entirely — and in my experience, it's the part that separates teams that improve from teams that just publish more.
Google gives RSA components an "Asset Strength" rating: Best, Good, Low, or Learning. It's not a perfect system, but it gives a signal about which individual assets are contributing to performance and which are dragging it down. I've built an equivalent system for content sections using tools already available to most teams.
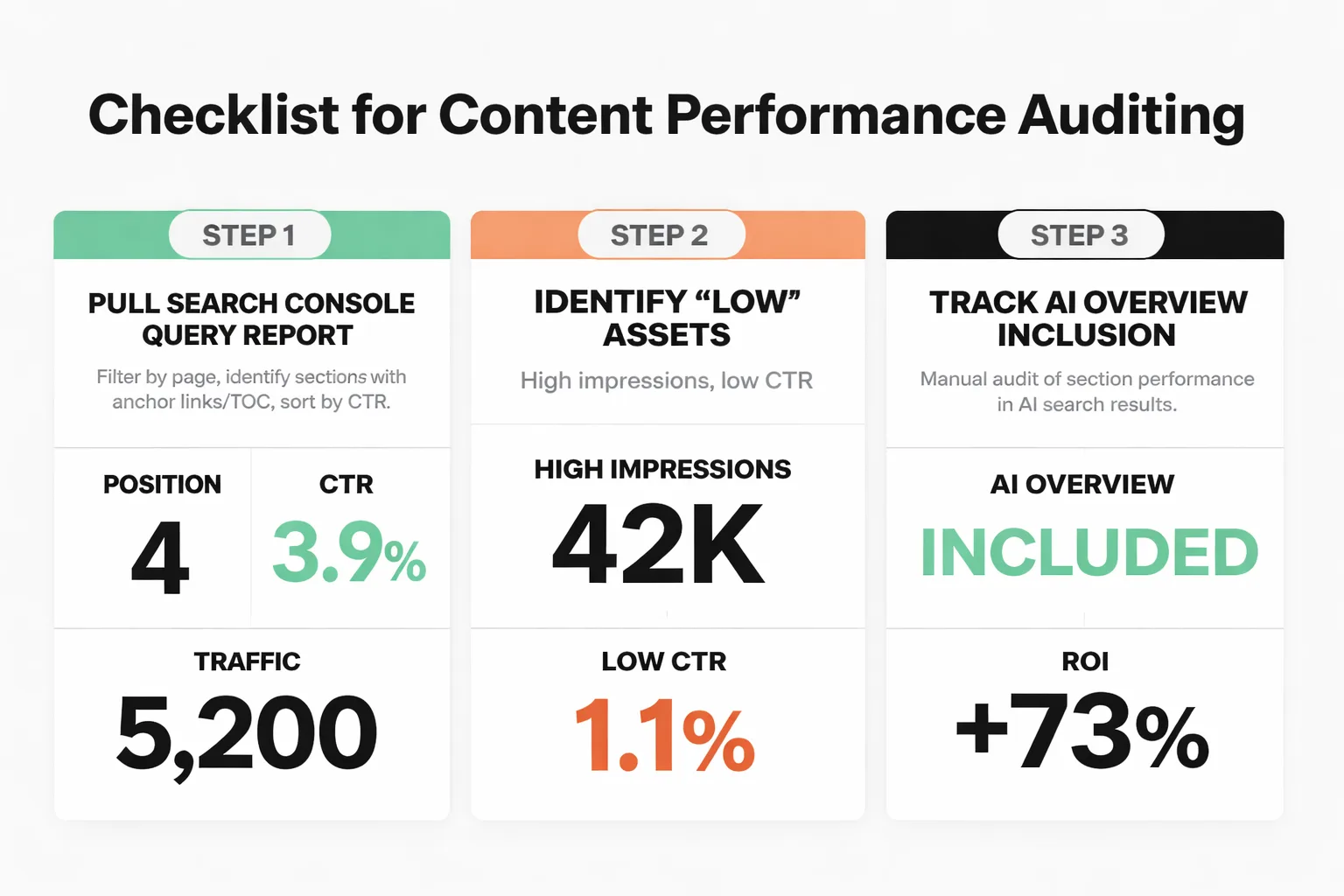
Here's the lightweight testing framework I recommend:
Step 1: Pull your Search Console Query report. Filter by page, then look at which queries are driving impressions and clicks to specific sections of the article. If anchor links or a table of contents are in place, it's often possible to see which sections are getting direct traffic. Sort by CTR — sections with high impressions but low CTR are the "Low" assets. They're being surfaced but not clicked.
Step 2: Track AI Overview inclusion. This is manual right now, but I've found it's worth doing for highest-traffic pages. Run the 10-15 queries most relevant to each major section and note whether your content is cited. Do this monthly. If a section that used to get cited stops appearing, something changed — either the content or the competition for that query.
Step 3: Use on-page engagement as a proxy for asset quality. Scroll depth, time-on-section (if heatmap tooling like Hotjar or Microsoft Clarity is available), and bounce rate from specific anchor links all indicate whether a section is delivering on its promise. A section with high entry traffic but immediate bounces is the content equivalent of an RSA headline with high impressions and zero conversions.
Step 4: Rewrite the "Low" assets. When I identify a section as underperforming — low CTR, not cited in AI Overviews, high bounce — I treat it like a low-performing RSA asset. Rewrite it with a different angle. Change the framing. Add a specific data point. Make the opening sentence more direct. Then wait 4-6 weeks and measure again.
Step 5: Pause or consolidate redundant sections. Just as you'd remove a low-performing RSA headline that's similar to a better-performing one, content sections covering the same ground without adding distinct value should be consolidated. SEO keyword cannibalization at the section level is a real problem — two sections answering the same query split extraction potential without doubling citation rates.
I want to be direct about the limitations here: ChatGPT search delivers a 0.84-1.3% CTR, approximately 96% lower than Google's estimated 29.2% CTR. Sidebar citations in AI search responses achieve a 6-10% CTR. These numbers mean that optimizing purely for AI citation at the expense of traditional search performance is a bad trade right now. The goal is to build content that performs in both environments — and the RSA asset framework does exactly that, because the same qualities that make a content section extractable by AI (direct answers, specific data, and standalone sections) also make it more likely to earn a featured snippet in traditional search.
The broader point worth returning to is this: Google built RSAs because it understood, years before most marketers did, that no single human could predict which combination of copy would perform best across millions of different user contexts. The solution was to create a system where humans provide high-quality raw material — varied assets that lead with benefits and specifics — and let the machine find the best combinations. That's exactly what AI content optimization requires in 2026. The audience isn't a single reader anymore. At Meev, we've reoriented our entire content approach around this reality — we're writing assets for a retrieval system that will decide, in real time, which fragment best serves each individual query.
The marketers who understand this — who stop thinking in articles and start thinking in assets — are going to have a significant advantage as over 60% of Google searches now result in zero clicks and AI-mediated answers become the default interface for information. The ones who keep writing linear, keyword-pinned content are going to wonder why their traffic keeps declining despite publishing more.
Write modular. Write specific. Test like a PPC manager. That's the whole playbook.