
By Judy Zhou, Head of Content Strategy
Key Takeaways
- Topical authority is built from three signals — entity coverage, internal linking density, and co-citation — not article count alone. • Google's 2026 core updates evaluate topical depth and content cluster authority as distinct ranking factors, meaning sites with shallow broad coverage recover slower post-update than deep-cluster sites. • A 90-day roadmap for small teams: launch pillar + 2 cluster articles simultaneously, add 4-6 cluster articles per month, and track query impression growth in Search Console as your earliest authority signal. • AI citation frequency in ChatGPT, Perplexity, and Claude is a faster-moving leading indicator than Google rankings — sites earning AI citations in month two typically see ranking movement by month four.
Marcus had published over 200 blog posts in three years. His team celebrated every new article, shared it on LinkedIn, and waited. Rankings trickled in, then plateaued. A competitor with half the post count was outranking him on nearly every term that mattered. When Marcus finally sat down with an SEO consultant, the diagnosis was immediate: his content covered dozens of topics shallowly rather than owning any single subject deeply. That afternoon, the concept of topical authority changed how he thought about every piece of content his team would ever produce again.
Topical authority — the signal Google uses to determine whether your site genuinely owns a subject area — is now the variable separating sites that compound traffic from sites that plateau. Google's 2026 core updates evaluate topical depth, content freshness patterns, user engagement signals, and content cluster authority as distinct ranking factors, according to recovery analysis from Topical Map AI. Sites that demonstrate deep expertise in specific subject areas recover faster post-update than those relying on general domain authority. The pattern I keep seeing in content audits: teams that treat publishing as a volume game get lapped by smaller teams that treat it as a coverage game. Topical authority SEO is no longer a nice-to-have — it's the mechanism by which Google decides who gets cited by AI Overviews. If you're not building it systematically, your competitors are building it against you.
What Topical Authority Actually Means to Google's Systems in 2026
Forget the textbook definition. In practice, topical authority is Google's confidence score for your site on a given subject — and it's built from three interlocking signals, not one.
The first is entity coverage: how completely your content maps to the entities (people, concepts, processes, products) that Google's Knowledge Graph associates with your topic. If you're writing about content marketing but you've never published on content calendars, content distribution, or content ROI, Google sees gaps — even if your individual articles are excellent. Search engines can now evaluate context, meaning, and relationships between content pieces via AI systems, which means entity coverage gaps are visible in ways they weren't three years ago.
The second is internal linking density. This is where I see teams leave the most authority on the table. In my work auditing content operations for brands at scale, the most common failure isn't thin content — it's well-written content that's orphaned from the rest of the site's topical cluster. When I audited a B2B SaaS client in early 2025, several high-authority pillar pages had zero links pointing to adjacent cluster content that directly answered the reader's next logical question. We added 11 cross-cluster contextual links in one pass and saw crawl frequency improvements within six weeks. Google doesn't need you to enforce topic separation through link starvation — it needs your links to make sense to a human reader.
The third signal is co-citation: whether other authoritative sites in your niche mention your content alongside recognized sources on the same topic. This is the hardest to manufacture and the most durable once earned. When Mailchimp's topical authority explainer references the same conceptual framework your pillar page uses, that's a co-citation signal. It tells Google your content belongs in the same conversation as established sources. Build for co-citation by publishing content that practitioners actually want to reference — original frameworks, original data, and positions that are specific enough to be disagreeable.
The Topical Map — How to Audit Your Coverage Gaps in 90 Minutes
The audit isn't complicated. It's uncomfortable, because it shows you exactly where you've been wasting publishing budget.
Step 1: Export your Google Search Console data. Pull the last 12 months of queries, filter to your target topic cluster, and sort by impressions descending. You're not looking at rankings yet — you're looking at the full universe of queries Google thinks you're relevant for. Export this to a spreadsheet.
Step 2: Run a competitor content audit. Take your top two competitors and use a tool like Ahrefs or Semrush to export their top pages by organic traffic within your topic cluster. You're building a master list of subtopics — every article title becomes a potential gap. Paste them into a second tab.
Step 3: Map the overlap. Create a third tab with three columns: subtopic, you have it (Y/N), competitor has it (Y/N). Any row where the competitor has coverage and you don't is a gap. Any row where neither has coverage is an opportunity. The gaps are urgent. The opportunities are your moat.
Step 4: Score by search intent alignment. Not all gaps are equal. A gap on a high-volume informational query is different from a gap on a transactional query near your product. Score each gap 1-3 by business relevance, then sort. The top 10 items on that sorted list are your next 10 articles — in order.
This process takes 90 minutes the first time and 30 minutes on repeat audits. The output isn't a content calendar — it's a coverage map with a priority stack. There's a meaningful difference. A content calendar tells your team when to publish. A coverage map tells them what actually matters and why.
For teams thinking about how topical authority and user intent interact, this audit is where those two concepts converge. Every gap you find is simultaneously a coverage failure and an intent mismatch — you're not showing up for the questions your audience is actually asking.
Want to see exactly which topical gaps are costing you rankings right now?
Pillar-Cluster Architecture That AI Search Engines Actually Cite
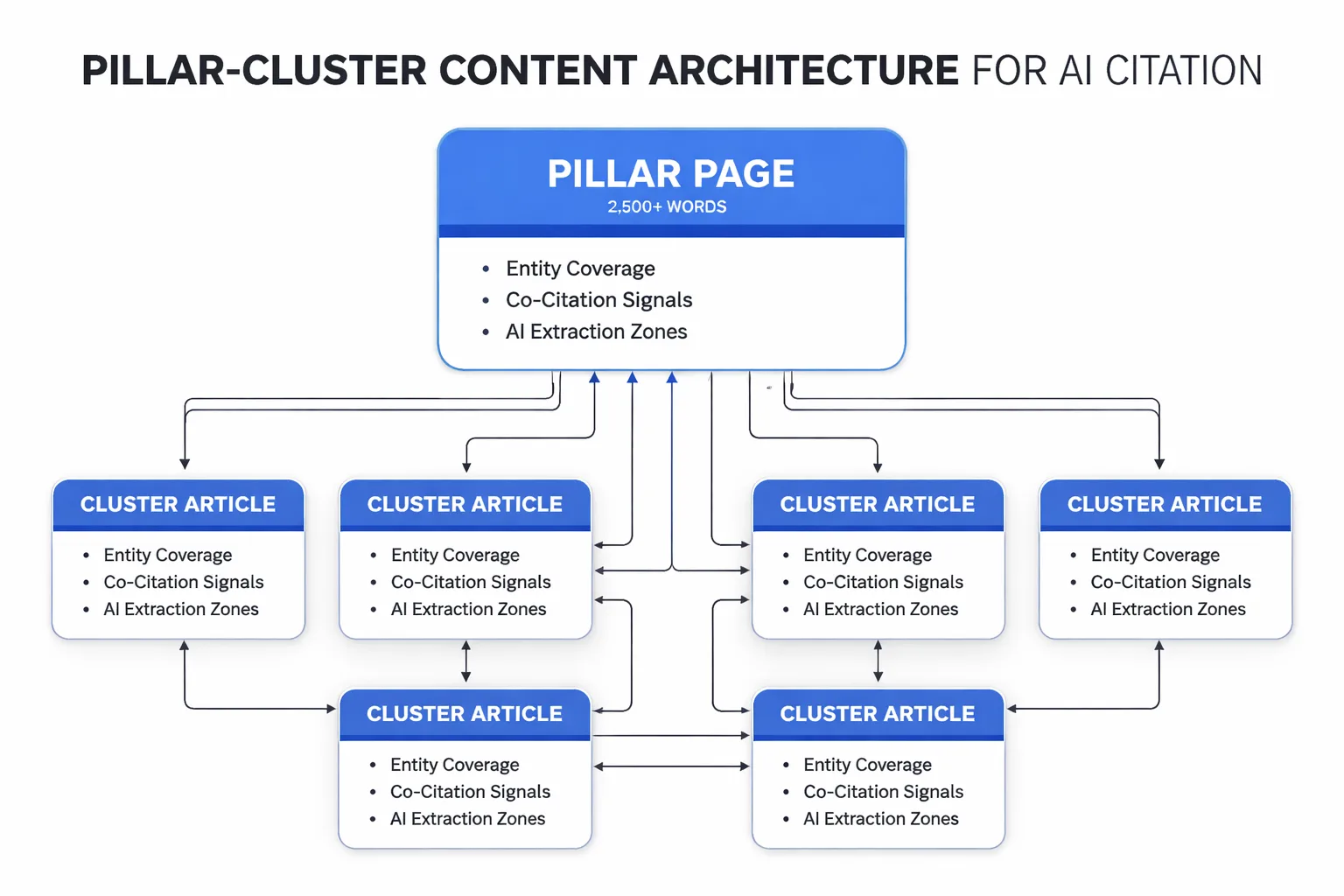
Here's the contrarian take most practitioners won't say out loud: the pillar-cluster model isn't primarily an SEO strategy anymore — it's an AI citation strategy. ChatGPT, Perplexity, and Claude don't pull from the highest-ranking page. They pull from the page that most completely answers the question with the most attributable, self-contained claims. A well-structured cluster gives AI engines multiple entry points into your content ecosystem, which means more surfaces to cite.
The architecture that works in 2026 has three layers. The pillar page covers the full topic at a definitional and strategic level — 2,500 words minimum, with explicit internal links to every cluster article. Cluster articles go deep on individual subtopics — 1,200 to 2,000 words, each with a self-contained answer in the first 200 words (because that's what AI engines extract). Supporting content — FAQs, glossary entries, data roundups — fills the entity gaps and creates the co-citation surface area.
The internal linking rules I follow: every cluster article links back to the pillar using a descriptive anchor (not "click here," not the exact keyword phrase repeated identically 18 times — I tested that approach on a content hub in early 2023 and watched rankings slip over three months as anchor diversity collapsed). Every cluster article links to at least two adjacent cluster articles on related subtopics. The pillar links to every cluster article, updated every time a new cluster piece publishes.
For AI citation specifically, structure matters more than most teams realize. AI engines prefer numbered lists, bolded claims with specific numbers, and named sources over flowing prose. That's not a reason to write robotic content — it's a reason to make sure every section of every cluster article has at least one extractable, attributable claim. If you want to understand how this plays out across different AI answer engines, the AEO vs. SEO breakdown on Meev covers how optimization differs between traditional search and answer engine optimization in ways that directly affect cluster design.
One structural decision that trips teams up: whether to use strict topic silos or allow cross-topic links. My position is that silos do the most work when a site is under two years old and Google is still calibrating topical relevance. On established sites, strict siloing kills useful contextual links. I loosened silo constraints on a mid-size B2B site in Q1 2025 — added 30 cross-topic internal links we'd previously blocked — and saw crawl frequency increase within six weeks without any measurable drop in topical relevance signals in Search Console.
The Publishing Cadence That Builds Authority Fastest

Volume without structure is just noise. But structure without velocity doesn't build authority either — Google needs to see consistent topical engagement, not a burst of content followed by silence.
The cadence I've seen work for small teams (2-4 people) is: one pillar page per quarter, four to six cluster articles per month, and two to four supporting pieces (FAQs, glossaries, data posts) per month. That's roughly 6-10 pieces of content per month total — not 30, not 2. The key isn't the number; it's that every piece connects to the cluster and that the cluster grows visibly over time.
The 90-day roadmap for a team starting from scratch on a new topical cluster:
1. Weeks 1-2: Complete the topical map audit. Draft the pillar page. Don't publish yet. 2. Weeks 3-4: Publish the pillar page and two cluster articles simultaneously, fully interlinked. This gives Google a connected cluster to crawl on day one instead of an orphaned pillar. 3. Weeks 5-8: Publish four additional cluster articles, one per week. Update the pillar's internal links each time. Check Search Console weekly for new query impressions in the topic cluster — this is your first signal that authority is building. 4. Weeks 9-12: Publish supporting content to fill entity gaps identified in the original audit. Begin outreach for co-citation — not link building in the traditional sense, but getting your cluster referenced by practitioners writing about the same topic.
On publishing frequency and AI content: the sites I've watched lose visibility weren't using AI to draft content — they were publishing raw AI output with zero editorial layer. An Ahrefs study of 600,000 top-ranking pages found that 86.5% contain some AI-generated content, with a correlation of just 0.011 between AI content percentage and ranking position. Statistically, that's almost nothing. What triggers the penalty isn't the AI; it's the absence of a human making editorial decisions. The workflow I've landed on: AI handles structure and first draft, a human editor rewrites for voice, adds original examples, and makes judgment calls about what to cut. If you're evaluating which AI tools actually support this kind of editorial workflow rather than replacing it, Meev's comparison with Surfer SEO covers the distinction between automated publishing pipelines and SEO writing assistants in useful detail.
Content freshness is also a real factor now. According to Topical Map AI's 2026 recovery analysis, content freshness patterns are among the signals Google evaluates for topical depth — meaning a cluster where articles were all published in a single burst and never updated looks different to the algorithm than a cluster that shows consistent editorial attention over time. I schedule quarterly reviews of every pillar page and annual refreshes of the top-performing cluster articles. It's not glamorous work, but it's the difference between authority that compounds and authority that decays.
How Does Google Measure Topical Depth?
Google doesn't publish a topical authority score. What it does publish — indirectly, through Search Console data — are the signals you can use to infer where you stand.
Indexed page count per topic cluster is the most direct proxy. Filter your Search Console coverage report by URL path if your site uses topic-based folder structures (e.g., /content-marketing/). A growing indexed count within a cluster, with low exclusion rates, means Google is accepting your coverage as legitimate. A flat or declining indexed count despite consistent publishing means something is wrong — either quality signals are weak or internal linking isn't surfacing new content to crawlers.
Crawl frequency changes are the leading indicator I trust most. When Google starts crawling a cluster more frequently, it's a signal that the site has earned more crawl budget in that topic area — which precedes ranking improvements by weeks to months. You can't see crawl frequency directly in Search Console, but you can infer it from the "Crawled - currently not indexed" and "Discovered - currently not indexed" trends in the Coverage report.
AI citation appearances are the newest metric and the hardest to track systematically. The manual approach: run the queries your cluster targets in ChatGPT, Perplexity, and Claude, and note whether your content is cited. Do this monthly. It's not a perfect measurement, but the pattern I keep seeing is that sites earning AI citations in month two are earning Google featured snippet placements in month four. The correlation isn't causal — both are downstream of the same quality signals — but AI citation is a faster-moving indicator.
Branded search growth is the long-term signal. When people start searching for your brand name alongside topic terms ("[brand] content marketing guide," "[brand] topical authority"), that's Google seeing your brand as an entity associated with the topic — which is the end state of topical authority done right. Track this monthly in Search Console by filtering queries containing your brand name.
Why Does Topical Authority and User Intent Overlap?
Most teams treat topical authority and user intent as separate optimization problems. They're not — they're the same problem viewed from different angles.
User intent tells you what a searcher wants from a given query. Topical authority tells you whether Google trusts you to answer it. The overlap is complete: you cannot build genuine topical authority on a subject cluster without systematically covering the full range of intents within that cluster. Informational queries, commercial investigation queries, and transactional queries all need representation. A cluster that only covers informational intent looks incomplete to Google's systems because the entities associated with the topic include commercial and transactional dimensions.
This is where the Meev article on intent signals connects directly to topical authority building — understanding what intent signals look like in practice helps you design cluster coverage that addresses the full intent spectrum, not just the high-volume informational queries that feel safe to target.
The practical implication: when you run your topical map audit, categorize every gap by intent type, not just by subtopic. A cluster with 12 informational articles and zero commercial-intent articles has a structural authority gap that volume alone won't fix.
When Should You Prioritize Depth Over Breadth?
Always, until you've achieved coverage parity with your top competitor on your core topic cluster. Then breadth.
This is the sequencing mistake I see most often: teams identify 40 content gaps and try to fill them all simultaneously with 800-word articles. The result is a site that looks busy but owns nothing. Google's systems — and AI answer engines — reward specificity. A 2,000-word article that completely answers a narrow question will outperform a 900-word article that partially answers a broad one, for the narrow query and often for the broad one too.
The threshold I use: depth-first until your cluster has at least 15 published pieces with full internal linking, a pillar page, and coverage of the top 10 subtopics by search volume. After that, breadth expansion makes sense — you're adding to an established authority base rather than trying to establish authority on a thin foundation.
For teams using AI to accelerate content production, this depth-first approach also solves the quality problem. It's easier to maintain editorial standards on 6-8 deeply researched articles per month than on 25 shallow ones. The AI drafts the structure; the editor adds the depth. That workflow scales. Raw volume doesn't.
How to Measure Topical Authority Gains Before Rankings Move
Rankings are a lagging indicator. By the time your target keywords move, the authority signals that caused the movement have been building for weeks. Here's what to watch first.
Indexed page count per cluster: Set a monthly tracking cadence. Consistent growth with low exclusion rates is the earliest signal that Google is accepting your cluster as authoritative coverage.
Query impression growth in Search Console: Filter to your topic cluster and track total impressions month-over-month, not just for target keywords but for the full query set. Impression growth on long-tail variations you didn't explicitly target is the clearest signal that topical authority is building — Google is surfacing you for queries you didn't optimize for because it's confident you cover the topic.
AI citation frequency: Monthly manual checks across ChatGPT, Perplexity, and Claude for your cluster's core queries. Track which articles get cited and which don't — the uncited ones are your next optimization targets.
Branded search volume: Pull monthly from Search Console, filtering for brand-name queries. Growth here means your content is creating memory — people are coming back to you by name, which is the behavioral signal that reinforces entity association.
Crawl frequency proxy: Watch the Coverage report's "Discovered - currently not indexed" count. If it's growing faster than your publishing rate, Google is finding content through internal links — which means your link architecture is working.
For teams wanting to go deeper on ROI measurement tied to these leading indicators, the Meev article on content ROI and analytics connects these signals to business outcomes in ways that make the case internally for sustained topical authority investment.
The honest truth about measurement: none of these indicators give you a single "topical authority score" to report upward. What they give you is a dashboard of directional signals that, together, tell you whether your cluster is gaining or losing ground. That's enough to make decisions. It's not enough to make a clean slide for a quarterly business review — which is why I always pair these leading indicators with a lagging metric (ranking position for the pillar page's primary keyword) so there's a concrete number the room can anchor on while the leading indicators do the real diagnostic work.
Frequently Asked Questions
How long does it take to build topical authority from scratch? For a new site with no existing authority, expect 6-12 months before topical authority signals translate into meaningful ranking improvements on competitive terms. For an established site adding a new topic cluster, the timeline compresses significantly — often 3-6 months — because domain trust is already established. The leading indicators (query impressions, crawl frequency, AI citations) should show movement within 60-90 days of launching a well-structured cluster.
Does topical authority replace the need for backlinks? No — but it changes the calculus. On highly competitive queries, backlinks still matter. What topical authority does is reduce your dependence on link volume by making each link you do earn more powerful. A link to a site that clearly owns a topic is worth more than a link to a site that dabbles in it. Build topical authority first; it makes your link acquisition more efficient, not unnecessary.
Can a small site beat a high-domain-authority competitor through topical authority? Yes, on specific subtopics — and that's exactly the strategy. A DA 30 site that completely owns a narrow topic cluster can outrank a DA 70 generalist site on the queries within that cluster. The key is narrowing your initial cluster scope to something you can genuinely out-cover, then expanding from that base. Trying to compete across a broad topic immediately is how small sites lose.
How many articles do I need before topical authority kicks in? There's no magic number, but the pattern I keep seeing is that clusters with fewer than 10 published pieces rarely show strong authority signals, regardless of individual article quality. The floor appears to be around 10-15 well-interlinked cluster articles plus a pillar page. Below that threshold, Google doesn't have enough coverage evidence to assign strong topical confidence.
Does AI-generated content hurt topical authority building? Only if it's published without editorial oversight. The Ahrefs study of 600,000 top-ranking pages found a correlation of just 0.011 between AI content percentage and ranking position — effectively zero. What matters is whether the content demonstrates genuine expertise, original perspective, and complete coverage of the subtopic. AI can produce that with a strong editorial layer. It reliably fails to produce that without one.
About the Author
Judy Zhou, Head of Content Strategy
Judy Zhou leads content strategy at Meev, where she oversees AI-driven content research and publishing for hundreds of brands. With a background in SEO and editorial operations, she focuses on building content systems that rank on Google, get cited by AI search engines, and drive measurable business results.
Meev builds and publishes your topical clusters automatically — pillar pages, cluster articles, internal links, and all — so you can own your subject area before competitors close the gap.





