
Google-Extended Blocking: What Site Owners Get Wrong in 2026
Google-Extended blocking is one of the most consequential decisions a site owner can make in 2026 — and in my experience, most people are making it blindly.
I've watched months of building content that ranks get undone in an instant. Organic traffic holds steady. Then someone on the team reads a headline about AI scraping, adds three lines to robots.txt, and quietly locks the entire site out of the AI retrieval pipelines that are reshaping how people find information. No alarm goes off. Google Search Console doesn't flag it. Rankings don't move. But something important just broke — and the impact won't be felt for months.
TLDR - Blocking Google-Extended removes your content from the training and retrieval pipelines powering AI Overviews and Gemini responses — even when organic rankings stay intact. - Over 68% of clicks still come from organic search, but AI-driven answer engines are rapidly claiming the zero-click real estate above those results. - A selective blocking framework — protecting paywalled or proprietary pages while keeping editorial content open — is smarter than a blanket block. - Audit your robots.txt this week, cross-reference with Google Search Console structured data reports, and monitor AI citation changes over a 30-day window.
What Google-Extended Blocking Actually Does
Google-Extended is a specific user-agent token that controls access to your content for Google's AI products — Gemini, AI Overviews (formerly SGE), and Vertex AI. When you add User-agent: Google-Extended followed by Disallow: / to your robots.txt file, you're telling Google's AI systems to stop reading your site. Not Googlebot. Not the crawler that handles organic search indexing. Just the AI layer.
That distinction matters enormously, and it's where most site owners get confused.
A pattern I see constantly: teams conflate Googlebot (which handles traditional search indexing) with Google-Extended (which feeds AI products). They're separate user-agents with separate functions. Blocking Google-Extended does nothing to organic rankings in the short term — pages still get crawled, indexed, and ranked by Googlebot as normal. What gets lost is eligibility to appear in AI Overviews, Gemini responses, and any future AI-powered search experience Google builds on top of its content retrieval infrastructure.
Site owners are enabling this block for understandable reasons. There's genuine anxiety about AI companies training models on proprietary content without compensation. Publishers have watched their traffic erode as zero-click search and AI summaries absorb answers that used to drive clicks. Some legal teams are flagging copyright exposure. The concern is legitimate. But the reaction — a blanket block applied site-wide — is a blunt instrument being used on a problem that requires a scalpel.

The GEO Visibility Problem No One Is Talking About
The number that stands out from what I've found in the data: BrightEdge reports that over 68% of clicks still come from organic search in 2026. That sounds reassuring — until you realize that the zero-click layer sitting above those organic results is growing fast, and it's powered by exactly the retrieval systems a blanket block disables.
Generative Engine Optimization — GEO — is the practice of structuring content so AI systems cite it, quote it, and surface it in generated responses. The research is clear on what drives AI citation: authoritative sourcing, structured data, direct answer formatting, and crawl access. Block the crawler, and none of the other GEO signals matter. A site can have the most perfectly structured, E-E-A-T-optimized content on the web, and if Google-Extended can't read it, Gemini won't cite it. Full stop.
The arXiv research on Generative Engine Optimization confirms what I've seen in practice: AI systems pull from content they can access and verify. When a site is blocked, it's not just missing one citation opportunity — the model is effectively trained to treat that domain as a non-source. That's a compounding problem. Every week a block stays in place, a brand's absence from AI-generated answers becomes more entrenched.
And the scale of this is only going to grow. Google AI Overviews now trigger on 13% of searches. That number will climb. The content marketers building GEO reach right now — while their competitors are busy blocking — are going to own significant answer-engine real estate in 18 months. I've seen this pattern play out with featured snippets, with People Also Ask, with rich results. The early movers win disproportionately, and the window to establish that presence is shorter than most people think.
Blocking Google-Extended doesn't protect your content — it erases your brand from the fastest-growing discovery channel in search.
For teams serious about building lasting visibility, this connects directly to the broader challenge of building a content moat before AI flattens search — and right now, GEO reach is one of the most defensible moats available.
How to Audit Your Current Blocking Status
Before anything can be fixed, the first step is knowing exactly what has been blocked. Here's the audit process I run through for every site I review.
Step 1: Pull your robots.txt file directly.
Navigate to yourdomain.com/robots.txt in a browser. Search the page for the string Google-Extended. If you see it paired with a Disallow directive — especially Disallow: / — a blanket block is in place. Note whether the block applies to specific directories or the entire site.
Step 2: Check Google Search Console for structured data coverage. Open GSC, go to the Enhancements section, and review your Google Search Console structured data reports. Look for any drop in rich result eligibility that coincides with when the block was added. This won't directly show AI indexing status, but it gives a baseline for how well content is structured for machine readability — which correlates with GEO performance.
Step 3: Identify your highest-exposure content types. Not all content carries equal GEO risk. Make a quick inventory: Which pages contain original research, proprietary data, or paywalled content? Which pages are pure editorial — how-to guides, explainers, opinion pieces? In my work with content teams, editorial content is often being blocked unnecessarily, and that's where GEO visibility is being lost.
Step 4: Test with Google's robots.txt Tester. In Google Search Console, use the robots.txt Tester tool (under Legacy Tools) to verify how the Google-Extended user-agent is being handled across specific URLs. This catches edge cases where directory-level blocks are behaving unexpectedly.
The whole audit takes about 45 minutes for a site of average complexity. I recommend completing it before changing anything — a clear picture of the current state is essential before making decisions.
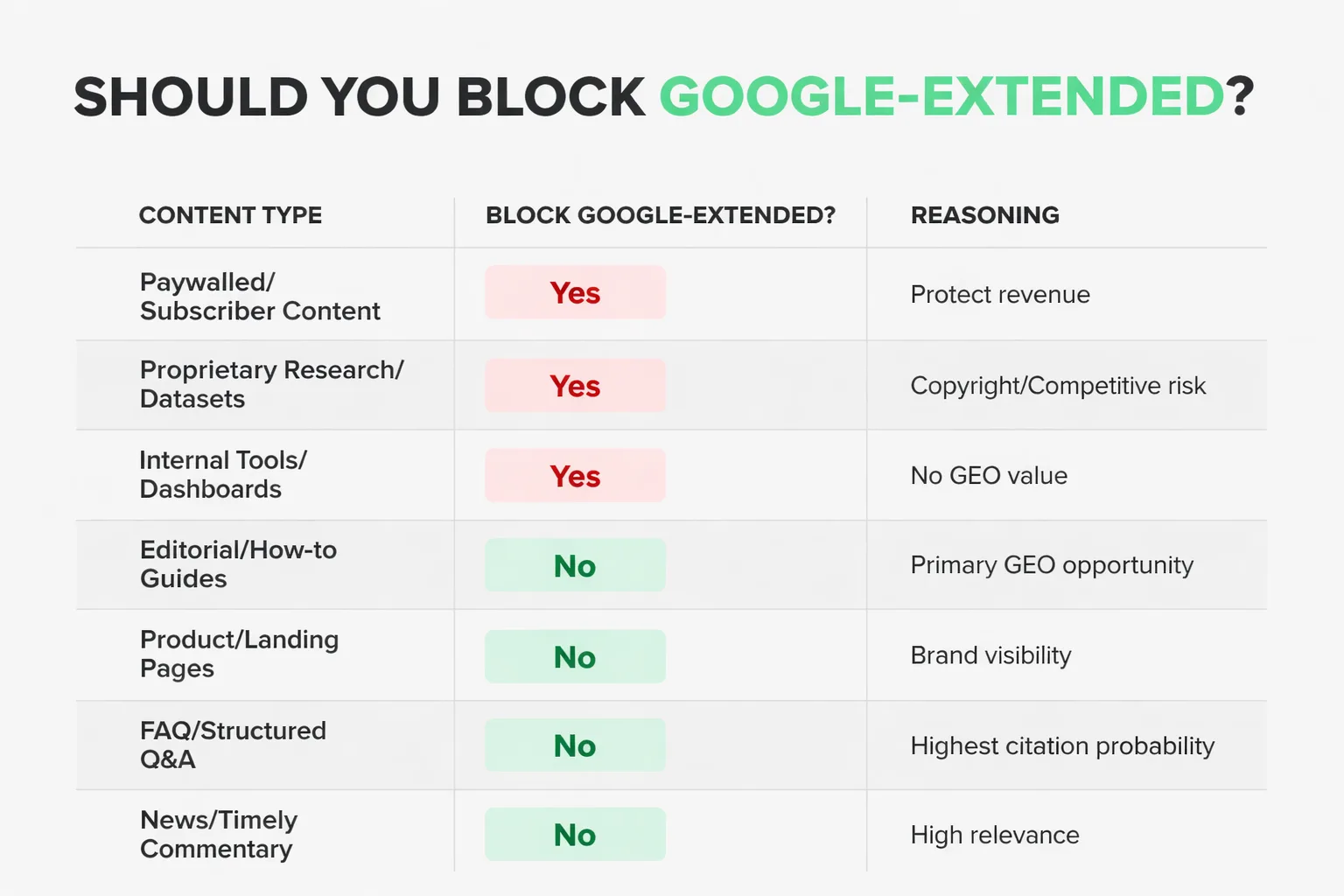
The Selective Blocking Framework: Protect Data, Keep GEO Reach
Most people think this is a binary choice: block everything or block nothing. It isn't. The smarter approach — one I recommend to every content team I work with — is a selective blocking framework that protects genuinely sensitive content while keeping editorial content fully accessible to Google-Extended.
Here's the decision matrix I apply:
| Content Type | Block Google-Extended? | Reasoning |
| Paywalled articles / subscriber content | Yes | Protect revenue model; AI access undermines subscription value |
| Proprietary research / original datasets | Yes | Copyright exposure; competitive differentiation at risk |
| Internal tools / member dashboards | Yes | Not public content; no GEO value anyway |
| Editorial blog posts / how-to guides | No | Primary GEO opportunity; blocking costs citations |
| Product pages / landing pages | No | Brand visibility in AI responses drives awareness |
| FAQ pages / structured Q&A content | No | Highest AI citation probability; never block these |
| News / timely commentary | No | Freshness signals matter for AI retrieval; keep open |
The implementation is straightforward once these decisions are made. Instead of a blanket Disallow: /, use directory-level rules:
User-agent: Google-Extended
Disallow: /members/
Disallow: /research/proprietary/
Disallow: /subscriber-content/
Allow: /
This tells Google-Extended to stay out of protected directories while allowing full access to everything else. It's a five-minute change with significant GEO upside.
One point worth addressing directly: if the concern is AI training on content without compensation, that's a legitimate policy debate — but blocking Google-Extended is not an effective solution to it. Google's AI opt-out changes are evolving, and the distinction between training data and retrieval for live responses is genuinely murky. What is clear is that the retrieval function — the part that determines whether Gemini cites content in a live response — is what this block most directly affects, and that's the part with the clearest business impact on visibility.
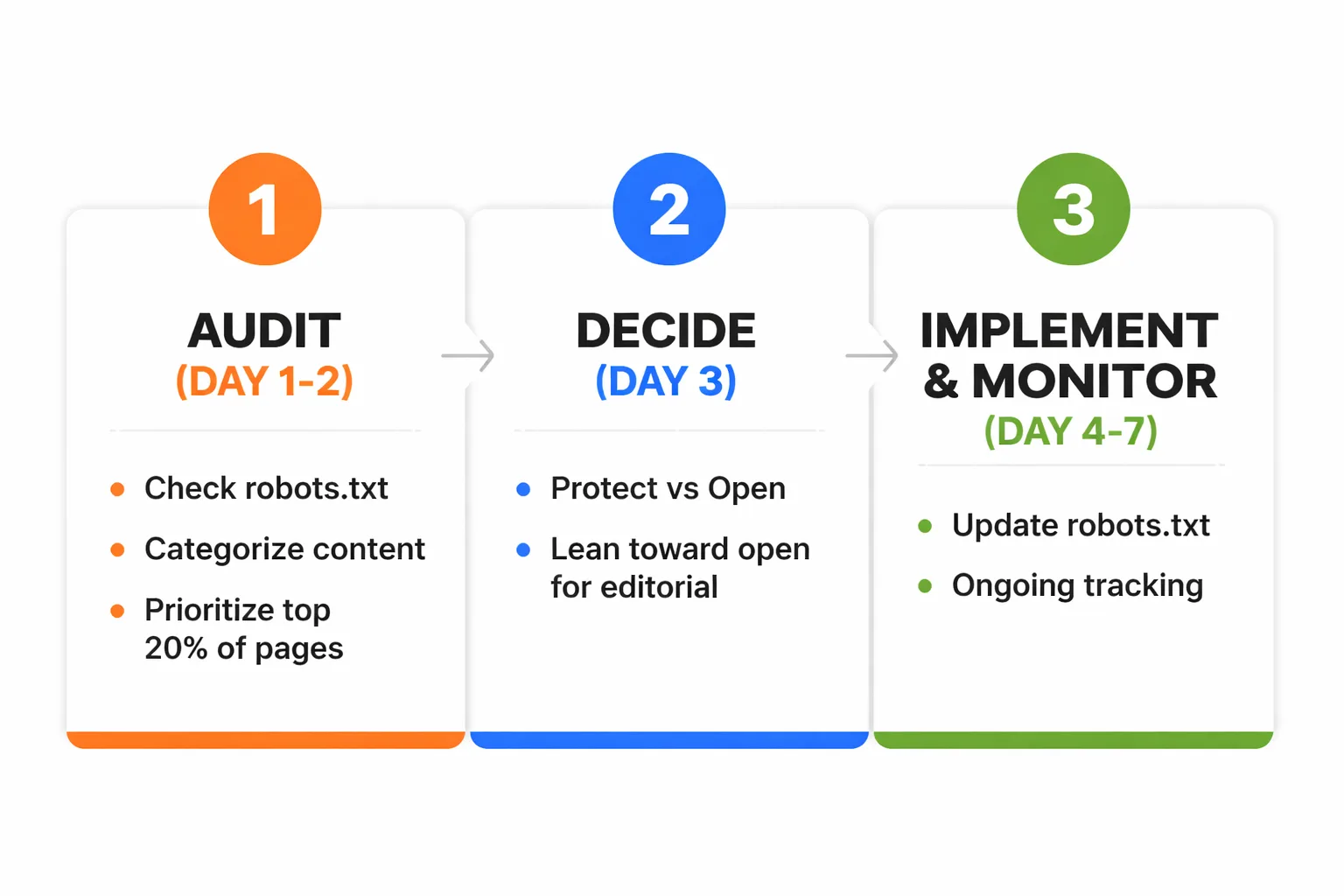
What to Do This Week
Here's the concrete action plan I recommend. Three steps, this week.
Step 1: Audit (Day 1-2) Run the four-step audit described above. Document the current robots.txt state, flag every instance of Google-Extended blocking, and categorize content into "protect" and "open" buckets using the framework above. For large sites, prioritize the top 20% of pages by organic traffic — those are the ones with the highest GEO citation potential.
Step 2: Decide (Day 3) For each content category, make a firm decision: block or allow. Don't hedge. If a page type genuinely contains proprietary data or paywalled content, block it. If it's editorial content that would be shared freely in a press release, open it. The middle-ground pages — case studies with client data, for example — can go either way, but I recommend leaning toward open unless there's a specific legal or competitive reason to block.
Step 3: Implement and Monitor (Day 4-7 and ongoing) Update robots.txt with the selective rules. Here's a clean sample snippet:
<h1>Selective Google-Extended access</h1>
User-agent: Google-Extended
Disallow: /members/
Disallow: /proprietary-data/
Disallow: /paywalled/
Allow: /blog/
Allow: /resources/
Allow: /
After implementation, set a 30-day monitoring window. Watch Google Search Console structured data reports for any changes in rich result eligibility. More importantly, start manually checking whether content appears in AI Overviews for target queries — search primary keywords in Google and look for citations in the AI-generated response at the top. This is currently the most direct signal that Google-Extended is reading and retrieving the content.
The feedback loop here is slower than traditional SEO. A traffic spike won't appear in week one. What gets built is AI citation presence — and that compounds over time the same way domain authority does. At Meev, we've seen that the sites establishing consistent GEO visibility now will be extraordinarily difficult to displace in 18 months.
With only 10% of US consumers currently using AI search, the market is still early. That number is going to look very different in two years. The content marketers who treat GEO as a future problem are going to find themselves rebuilding from scratch where the early movers have already locked in citation authority.
Don't be the team that blocked its way out of the next era of search.
Rapid-Fire Round
Does blocking Google-Extended affect my Google rankings? No — not directly. Googlebot and Google-Extended are separate user-agents. Organic rankings are unaffected. What gets lost is eligibility for AI Overview citations and Gemini responses.
How quickly does Google-Extended re-crawl after I remove a block? In my testing, Google-Extended re-crawls within 1-2 weeks for high-authority domains. Smaller sites take 3-4 weeks to see meaningful re-indexing in AI retrieval pipelines.
Is there a way to see if Gemini is citing my content? Not through a dedicated dashboard yet. The best method is manual: search target queries in Google and look for your domain cited in AI Overviews. Some third-party rank trackers are beginning to add AI citation monitoring — I'd track those tools closely.
Should I block other AI crawlers like GPTBot or ClaudeBot? That's a separate decision from Google-Extended. Those crawlers feed different AI products with different retrieval architectures. For GEO purposes — specifically Google AI Overviews and Gemini — Google-Extended is the one that matters most right now.
FAQ
What is Google-Extended and how does it differ from Googlebot?
Google-Extended is a separate user-agent from Googlebot that controls access to your content for Google's AI products, including Gemini, AI Overviews, and Vertex AI. Googlebot handles traditional search indexing and ranking — blocking Google-Extended has no effect on organic search positions, only on eligibility to appear in AI-generated responses.How do I check if my site is blocking Google-Extended?
Navigate toyourdomain.com/robots.txt in your browser and search for the string "Google-Extended." If you find it paired with a Disallow directive, your site is blocking Google's AI crawlers. You can also use the robots.txt Tester tool in Google Search Console to verify how specific URLs are being handled.