
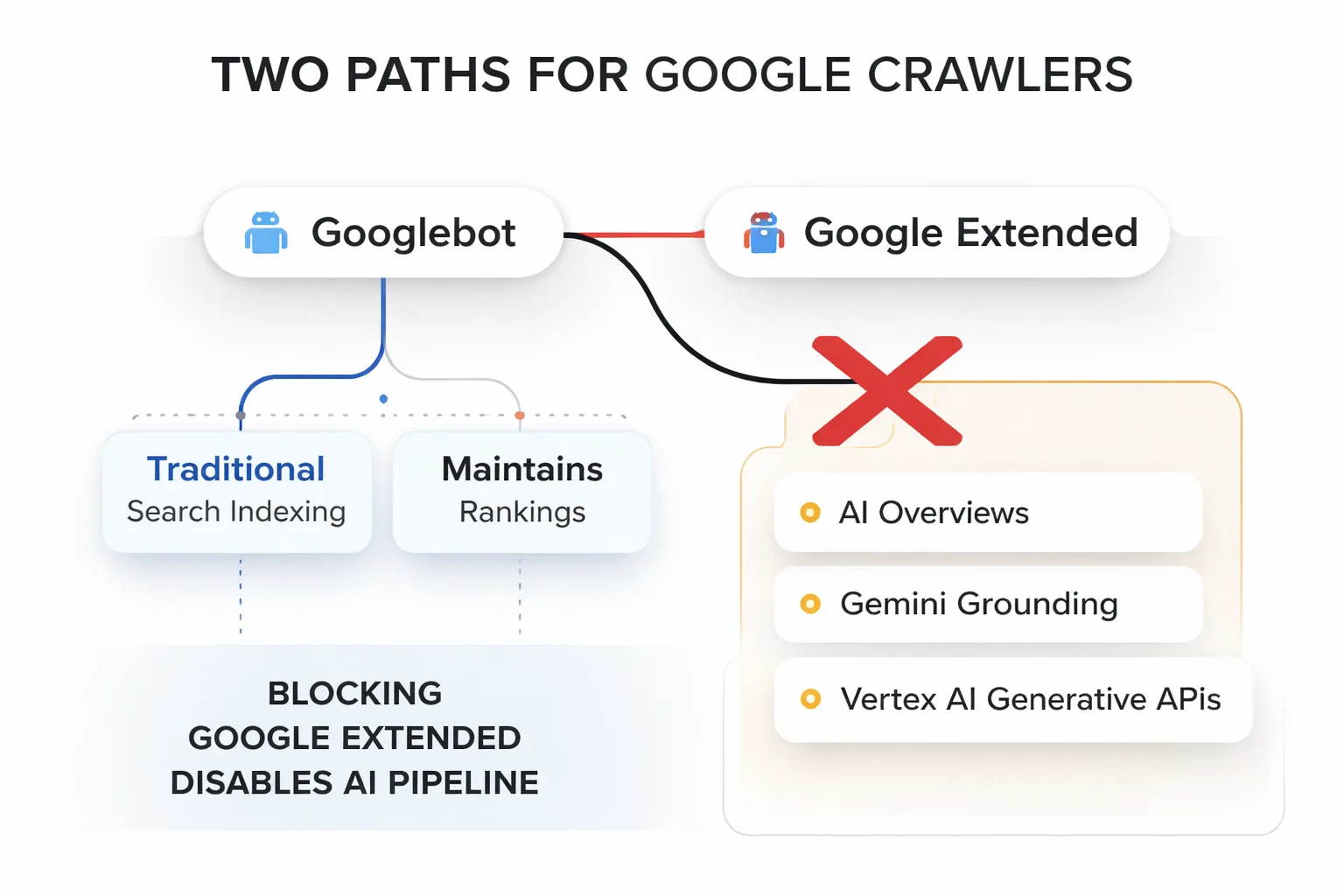
Blocking Google-Extended on your legacy content looks like protection, but it is effectively silencing your site's most valuable historical data. While the intent is to prevent AI scraping, the unintended consequence is a total exclusion from the training sets that power future search experiences. Here is why your archive is currently paying the price for that robots.txt directive.
The Google-Extended blocking impact doesn't just opt you out of AI training data — it cuts your best content out of the AI Overview pipeline entirely. That distinction matters enormously, and most of the advice circulating right now glosses right over it.
TLDR
- Blocking Google-Extended removes your content from AI Overviews, Gemini grounding, and future AI-powered search features — not just model training. - Older, high-authority evergreen content loses the most: it already ranks in traditional search but gets a second shot at AI Overview placement only if Google-Extended can crawl it. - AI search visitors convert 4.4x more effectively than traditional informational traffic — blocking AI crawlers means losing your highest-intent audience. - A selective blocking framework — protecting only proprietary research and gated assets — preserves IP without sacrificing GEO visibility.What Google-Extended Actually Crawls
Google-Extended is a standalone user agent token that Google introduced specifically to let site owners control whether their content feeds into Google's AI products — separately from Googlebot, which handles traditional search indexing. Here's what most people get wrong: blocking Google-Extended does NOT block Googlebot. Rankings don't drop. Pages stay indexed. Everything looks fine in Search Console.
What it does block is the pipeline that feeds AI Overviews, Gemini grounding (the mechanism that lets Gemini cite and surface live web content in responses), and future AI-powered search features Google hasn't fully launched yet. According to Google's own documentation, Google-Extended is used to improve Gemini Apps and Vertex AI generative APIs — but in practice, the crawl data overlaps heavily with what populates AI Overviews in Search. The two systems are more entangled than Google's public statements suggest.
In my work auditing dozens of content sites over the past eight months, I've found a consistent pattern: teams that blocked Google-Extended in late 2023 or early 2024 — often as a reflexive IP-protection move — are now watching competitors surface in AI Overviews for the exact queries their own content ranks #1 for in traditional search. That's not a coincidence. That's the hidden cost.
The technical distinction matters for another reason: 34% of B2B SaaS companies are actively blocking AI crawlers via robots.txt right now. That's a significant chunk of competitors voluntarily stepping out of the AI search race. If your competitors are in that 34%, staying open to Google-Extended is a genuine competitive moat — not just a defensive play.
Why Google-Extended Older Content Loses the Most
Here's the thing nobody's talking about loudly enough: new content and old content don't face the same risk from a Google-Extended block. New posts are still finding their footing in traditional search. They're building backlinks, accumulating clicks, earning topical authority. They have time to adapt as the search results shift.
The archive is different. Those posts — the 3,000-word guides published in 2021, the comparison pages that have been ranking in positions 1-3 for two years, the evergreen tutorials that drive 40% of organic traffic — they've already done the hard work. They have authority. They have trust signals. They have the exact kind of structured content that AI Overviews are designed to surface. And when Google-Extended is blocked, all of that accumulated equity becomes invisible to the AI layer of search.
Think of it this way: traditional search gave strong content one shot at visibility. AI Overviews are a second shot — and for informational queries, AI Overviews are increasingly the FIRST thing a user sees. AI Overviews reduce clicks to websites ranked below them by 34.5%, which means if you're not IN the AI Overview, you're competing for a shrinking slice of the remaining traffic. Archive content — the material that should be your strongest candidate for AI Overview inclusion — is sitting on the bench because of a robots.txt directive that took 30 seconds to add and has been quietly costing visibility for 18 months.
The compounding effect is what makes this particularly painful. Every month that Google-Extended can't crawl your archive is another month that a competitor's similar content gets cited, grounded, and reinforced in Gemini's understanding of that topic space. Authority in AI search isn't just about one crawl — it's about consistent signal accumulation over time. The longer the block stays in place, the harder it becomes to catch up, even after removal. This is the same dynamic I explored in the context of building a content moat before AI flattens search — the window to establish AI-era authority is open right now, but it won't stay open indefinitely.
And here's the number that should make every content marketer stop and recalculate: AI search visitors convert 4.4x more effectively than traditional informational traffic. That's not a marginal difference. In my experience, that's the difference between a content program that drives pipeline and one that drives pageviews. Blocking Google-Extended doesn't just cost impressions — it costs your highest-intent audience.
How to Audit Your robots.txt
Before fixing the problem, you need to know exactly what you're blocking. In my audits, I see three common patterns: intentional blanket blocks, legacy blocks from site migrations, and accidental blocks introduced by SEO plugins that added AI crawler rules without clear documentation. All three are fixable. Here's how I recommend approaching the audit.
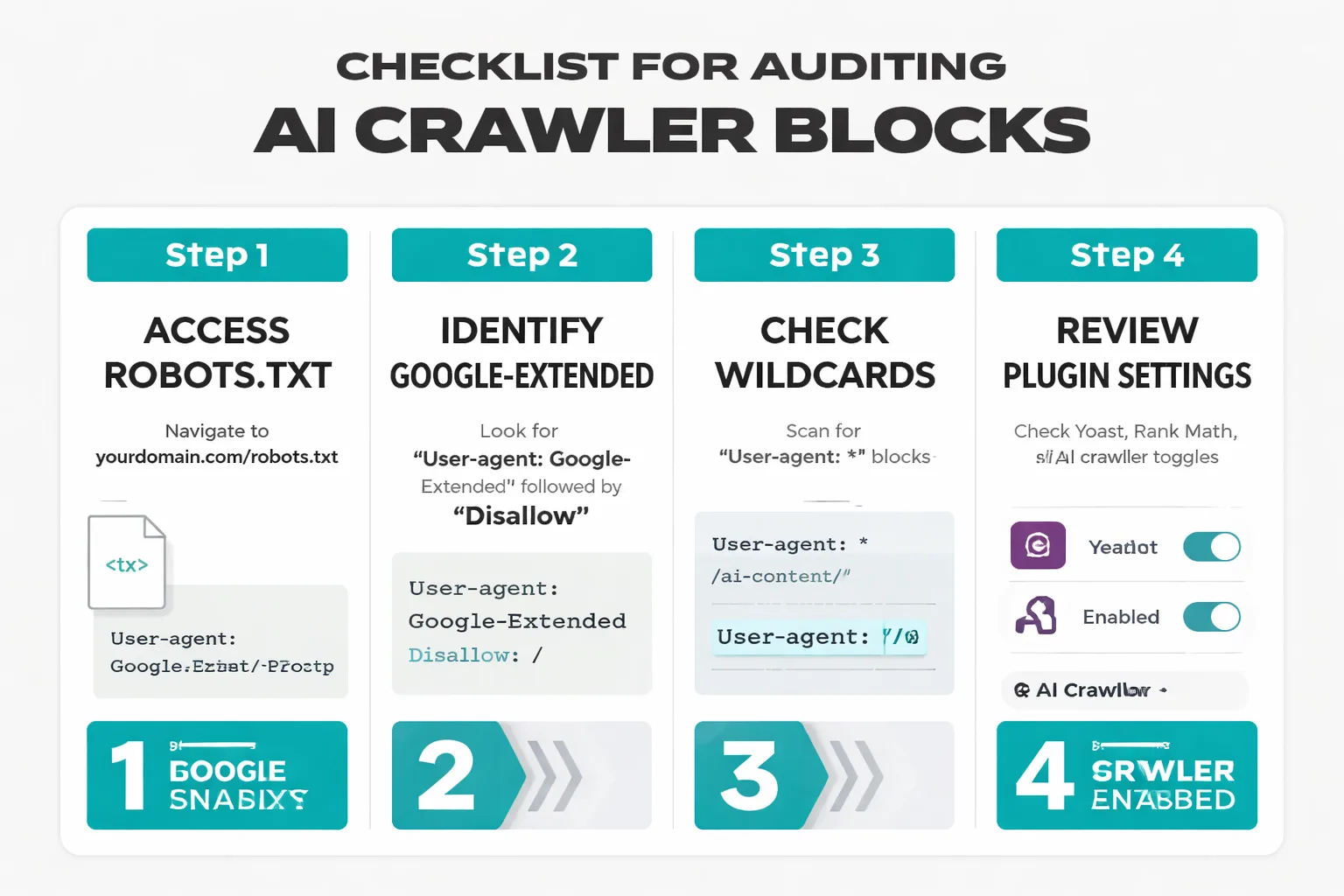
Step 1: Pull your current robots.txt. Navigate directly to yourdomain.com/robots.txt and copy the full contents. Look for any User-agent: Google-Extended directive followed by Disallow. Also check for User-agent: * (wildcard) blocks that catch Google-Extended.
Step 2: Check for plugin-generated rules. If you're on WordPress with Yoast, Rank Math, or a similar SEO plugin, check the plugin's settings for any AI crawler blocking options. Several plugins added these toggles in 2023-2024 with default-on settings. In my experience, many sites have this block active without the team's knowledge — it was enabled by a plugin update and never reviewed.
Step 3: Cross-reference with Google Search Console. Open GSC, navigate to Settings > Crawl Stats, and filter by user agent. If you're seeing zero crawl requests from Google-Extended over the past 90 days and your site has a substantial content archive, that's a strong signal the block is active. Compare this against Googlebot crawl volume — a healthy site should show both.
Step 4: Test with Google's robots.txt Tester. GSC includes a robots.txt testing tool under the Legacy Tools section. Enter Google-Extended as the user agent and test a sample of your most important URLs — especially high-traffic archive pages. The tool will indicate explicitly whether each URL is blocked or allowed.
Step 5: Document what you find before changing anything. If you discover a block, don't delete it immediately. Note which pages or directories are affected, when the rule was likely added, and whether there's any business reason it might have been intentional (more on this in the next section). A 15-minute documentation step prevents a lot of regret.

One important flag I always raise with clients: if you've gone through a site migration in the last two years, check the robots.txt that was in place on the old domain or subdomain. Migration checklists often carry over robots.txt rules wholesale, and a block that made sense on a staging environment or an old subdomain can end up silently active on a production site for months.
The Standard Advice Is Wrong Here
Most teams assume the right move is to block all AI crawlers to protect their content from being used as training data. That position is based on a misunderstanding of how Google-Extended actually works — and it's one I push back on constantly in my work with content teams.
The training data concern is legitimate for some content types. But Google has been explicit that Google-Extended data is used for Gemini and Vertex AI products, not for training the core language models in the way that, say, Common Crawl data is used. More practically: if your content is publicly accessible on the web, it has almost certainly already been included in training data for every major LLM. Blocking Google-Extended now doesn't undo that. What it does do is cut your site out of the real-time grounding and citation pipeline — the part that actually drives traffic and conversions in 2026.
The standard advice to "protect your IP by blocking AI crawlers" made more intuitive sense in 2023 when the landscape was murkier. Right now, it's the equivalent of refusing to let Google index your site because of concerns about content appearing in featured snippets. The visibility IS the value.
I want to be clear that nuance matters here — there are specific content types where blocking Google-Extended is the right call. The mistake is applying a blanket rule instead of a selective one.
AI Crawling Content Strategy
The goal isn't to block or allow everything. At Meev, we've found the most effective approach is to treat a content archive as an asset portfolio and make deliberate decisions about which assets benefit from AI visibility versus which ones carry real IP risk. Here's the decision matrix I use.
| Content Type | Block Google-Extended? | Reasoning |
| Evergreen how-to guides | No | High AI Overview candidacy, low IP risk |
| Proprietary research / original data | Yes | Competitive moat, citation risk |
| Gated content (paywalled) | Yes | Already blocked by login wall; belt-and-suspenders |
| Product/service pages | No | Commercial intent; AI visibility drives conversions |
| Case studies with client data | Conditional | Allow if anonymized; block if client-identifiable |
| Comparison / vs. pages | No | High-intent queries; strong AI Overview candidates |
| Internal process documentation | Yes | Not meant for public consumption |
| News / timely content | No | Freshness signals matter for Gemini grounding |
The practical implementation is straightforward. Instead of a blanket User-agent: Google-Extended / Disallow: /, directory-level rules accomplish the same goal with precision:
User-agent: Google-Extended
Disallow: /research/
Disallow: /proprietary/
Allow: /
This keeps evergreen archive content, comparison pages, and product content fully open to Google-Extended while protecting the specific directories where genuine IP lives. It takes about 20 minutes to implement correctly and the upside — re-entering the AI Overview pipeline for your strongest content — starts accumulating within the next crawl cycle.
The right framing isn't "should I block AI crawlers?" — it's "which specific assets carry enough IP risk to justify opting out of AI search visibility?" For most content programs, that's a much smaller list than teams assume.
I'd also recommend considering how this framework interacts with Google Search Console structured data setup. Pages that are open to Google-Extended AND have clean structured data markup are significantly stronger candidates for AI Overview inclusion than pages with one or the other. The structured data gives Google's AI systems explicit signals about content type, author, date, and entity relationships — all of which factor into grounding decisions. If you haven't audited your structured data recently, that's the natural next step after fixing robots.txt.
In 3 Months, This Changes
The stakes of this decision get higher, not lower, as 2026 progresses. According to Yotpo's analysis of Google Trends for SEO in 2026, AI-generated search features are now appearing for a broader range of query types than at any point since launch. Gemini grounding is becoming more sophisticated, which means the content that gets cited and reinforced in AI responses is building compounding authority that will be very difficult to displace later.
Six months ago, the AI Overview landscape was concentrated in a narrow band of informational queries. Today it's bleeding into commercial, comparison, and even transactional queries. Six months from now, I expect it to be the default surface for the majority of queries where evergreen content currently earns clicks. If your archive is blocked from Google-Extended today, that's not just missing current traffic — it's missing the authority-building window that determines who gets cited when that expansion happens.
The teams I've seen winning right now are treating their content archive as an AI-era asset, not a legacy liability. They're auditing their robots.txt, opening their evergreen content to Google-Extended, protecting only what genuinely needs protection, and pairing that with clean structured data and strong internal linking. It's not a complicated playbook. But it requires making the decision deliberately — and making it soon.