
When two of your own pages compete for the same search query, you aren't just confusing Google—you're actively sabotaging your own authority. SEO keyword cannibalization often hides in plain sight, masquerading as a simple ranking plateau. If traffic is oscillating or top-performing URLs are suddenly losing ground, it's time to stop the internal conflict.
That's cannibalization. And it's more common than you think — especially for teams that have been scaling content output with AI tools.
TLDR / Key Takeaways: - Two URLs competing for the same query splits PageRank and confuses Google's ranking signals, often causing both pages to rank lower than one consolidated page would. - You can identify cannibalization in under 20 minutes using Google Search Console's Performance report filtered by query, then cross-referencing which URLs appear for the same terms. - The right fix depends on traffic and authority data: consolidate and redirect for high-traffic duplicates, canonicalize for syndicated content, and delete for zero-traffic orphans. - AI-assisted content programs are especially prone to cannibalization — a keyword mapping spreadsheet and pre-publish intent check can prevent 90% of future conflicts.
What SEO Keyword Cannibalization Actually Looks Like
SEO keyword cannibalization happens when two or more pages on your site target the same primary keyword or search intent, causing Google to split ranking signals — authority, clicks, and crawl attention — between them instead of concentrating everything on one strong URL. The result isn't that both pages rank well. It's that neither does.
Here's the distinction that trips people up: topic overlap is normal and healthy. A site about content marketing might have articles on "content strategy," "content planning," and "editorial calendars" — those overlap thematically but serve different intents. Cannibalization is different. It's when you have a post titled "How to Write Meta Descriptions" and another titled "Meta Description Best Practices" and both are optimized for the query how to write meta descriptions. Google has to pick one. It often picks wrong, or worse, rotates between them unpredictably.
In my work auditing content sites, I've found cases where a single query had four competing URLs — a blog post, a category page, a product landing page, and a FAQ entry — all ranking between positions 8 and 22, none of them breaking into the top 5. I've seen consolidating those into one authoritative page push rankings to position 3 within six weeks. That's not a hypothetical. It's a pattern I've watched repeat across dozens of sites. According to Search Engine Land's cannibalization guide, this kind of authority dilution is one of the most underdiagnosed ranking suppressors in technical SEO.
The clearest signal that you're dealing with cannibalization — not just topic overlap — is URL instability in GSC. If the "top position" URL for a query keeps switching between two or three of your pages from week to week, that's Google indicating it can't decide which one to trust. That instability is costing you clicks.
How to Audit Your Site in 20 Minutes
Forget expensive tools for the initial pass. Here's the exact process I use, and it takes less time than a coffee break.
Step 1: Pull the GSC Performance report. Open Google Search Console, go to Performance > Search Results, and set the date range to the last 90 days. Click "Pages" first — export that data. Then switch to "Queries" and export that too. You now have two spreadsheets.
Step 2: Cross-reference queries with URLs. In GSC, click on any query that matters to your business. Below the graph, you'll see a "Pages" tab. If more than one URL appears for that query with meaningful impressions, you have a cannibalization candidate. Flag it.
Step 3: Run the site:query check. For any suspicious query, go to Google and search site:yourdomain.com "target keyword". If three or more of your own pages appear in the results, that's a strong confirmation signal.
Step 4: Use Screaming Frog for scale. If you're managing a site with 500+ pages, I recommend running the manual check for your top 20 queries, then running Screaming Frog's "Duplicate Content" report to catch clusters that would otherwise be missed. Filter by page title similarity and meta description overlap — those are the fastest proxies for intent duplication.
What confirmed cannibalization looks like in the data: two URLs sharing impressions for the same query, with neither consistently holding the top position, and combined CTR lower than what a single dominant URL would generate. If one URL sits at 1.2% CTR and another at 0.9% CTR for the same query, a consolidated page typically hits 3-4% CTR — that's the traffic being left on the table.
This is also where Google Search Console structured data issues often surface alongside cannibalization — two pages competing for the same rich result slot compounds the problem significantly.
5 Keyword Cannibalization Fixes Ranked by Impact and Effort
Not every cannibalization problem needs the same solution. Here's the decision framework I use, ranked from highest impact to lowest effort:
| Fix | Best For | Effort | Impact |
| Consolidate + 301 Redirect | Two pages, similar content, one has more links | Medium | Very High |
| Canonical Tag | Syndicated content, near-duplicate pages | Low | High |
| Restructure Internal Links | One page is stronger but getting less link equity | Low | Medium-High |
| Rewrite Intent | Pages cover same keyword but can serve different intents | High | Medium |
| Delete the Weaker Page | Zero traffic, zero backlinks, no unique value | Low | Medium |
Fix 1: Consolidate and 301 Redirect. This is the highest-impact move when both pages have meaningful content. Merge the best sections of both into one authoritative page, then 301 redirect the weaker URL to the surviving one. The redirected page's link equity flows to the winner. In my experience, ranking improvements typically appear within 4-8 weeks using this approach. ClickRaven's analysis of cannibalization causes confirms that consolidation consistently outperforms other fixes for pages with established backlink profiles.
Fix 2: Canonical Tag. Use this when you have near-duplicate content that needs to exist in multiple places — like a product description that appears on both a category page and a product detail page. Add rel="canonical" pointing to the primary URL. This tells Google which version to index and rank without deleting the secondary page.
Fix 3: Restructure Internal Links. Sometimes the problem isn't the content — it's that internal linking is sending mixed signals. If there's one strong page and one weaker page competing, audit the internal links. Make sure anchor text pointing to the stronger page uses the target keyword. Remove or change anchors pointing to the weaker page. This is the lowest-effort fix and often underestimated in its impact.
Fix 4: Rewrite Intent. This is the most nuanced fix. If two pages target similar keywords but could legitimately serve different intents — one informational, one transactional — rewrite them to make that distinction unmistakable. Retitle, restructure, and reoptimize each for its specific intent. This takes real editorial work but preserves both pages.
Fix 5: Delete the Weaker Page. If a page has zero backlinks, under 50 monthly impressions, and no unique content that can't be absorbed elsewhere — delete it and redirect to the closest relevant URL. Weak pages with no unique value are dead weight.
The merge-vs-redirect decision comes down to one question: does the weaker page have anything the stronger page doesn't? If yes, merge. If no, redirect and move on.
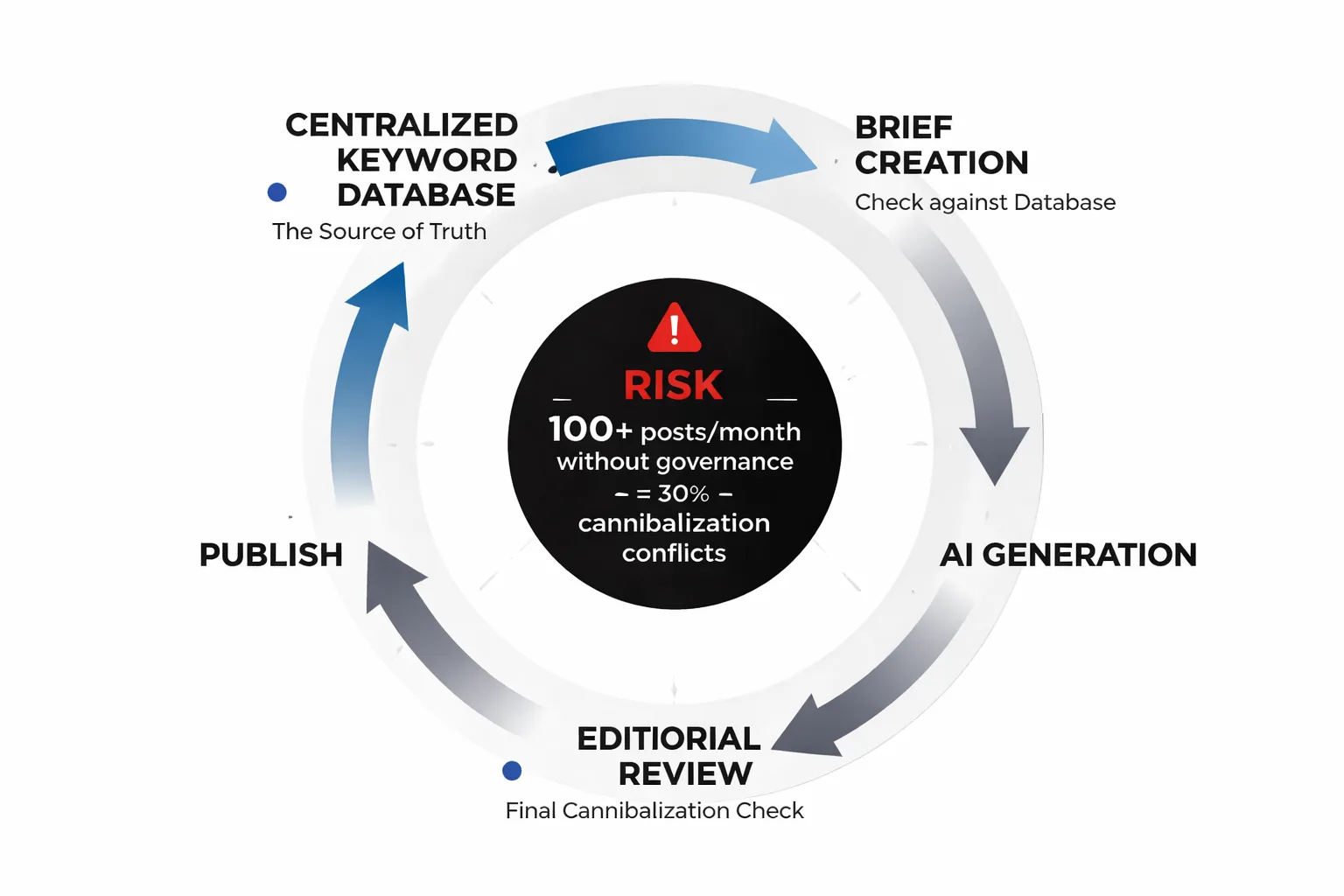
How to Prevent It When Scaling with AI
Here's the uncomfortable truth about AI content creation at scale: in my view, it's the single biggest driver of new cannibalization problems appearing in 2025 and into 2026. When I see teams publishing 20, 50, or 100 AI-assisted posts per month, the probability of intent duplication compounds with every piece added. AI tools don't inherently know what's already been published. They optimize for the brief they're given — and if briefs aren't tightly controlled, a site can end up with four variations of "how to write a blog post introduction" scattered across it within six months.
At Meev, I've seen this pattern on sites that were doing everything else right. Strong domain authority, solid backlinks, good technical SEO. But the AI content program had no keyword governance layer, and within a year there were 30+ cannibalization conflicts eating into top-performing queries. The fix took three months of editorial cleanup that could have been avoided entirely with a simple system upfront.
Here's what I recommend for any team scaling blog output with AI:
1. Build a master keyword map. A single shared spreadsheet (Google Sheets works fine) with every target keyword, the URL assigned to own it, and the publish date. Before any new piece goes into production, check this sheet. If the keyword is already claimed, the new piece needs a different angle or a different primary keyword.
2. Run a pre-publish intent check. Before publishing any AI-generated post, search the target keyword in Google and check whether any existing pages already rank for it. If yes, decide: does the new piece serve a genuinely different intent? If not, don't publish it — expand the existing page instead.
3. Brief AI tools with exclusion context. When prompting AI writing tools, include a line like: "Do not optimize this piece for [X keyword] — that keyword is owned by [URL]. This piece targets [Y keyword] with [Z intent]." It sounds simple, but I've found it prevents the most common drift.
4. Audit quarterly. Even with a good system, drift happens. Set a calendar reminder every 90 days to run the GSC query audit I described above. Catching conflicts early, when they're still easy to fix, saves significant cleanup effort later.
This connects directly to a broader content architecture principle — if you're building topic clusters, each cluster needs a clear pillar page that owns the primary keyword, with supporting pages targeting long-tail variations. The content cluster strategy guide covers how to structure your architecture to prevent cannibalization before it starts.
Note also: as AI content creation for social media and blog output continues to accelerate, Google's quality rater guidelines are increasingly focused on intent clarity and content differentiation. Publishing near-duplicate intent content — even if each piece is technically unique — is a pattern that's getting harder to hide from algorithmic evaluation. Prevention isn't just about rankings. It's about building a content library that actually serves readers differently at each URL.
Measuring Recovery After the Fix
The fix is in place. Now what? A mistake I see constantly is checking rankings every day for two weeks, seeing nothing, and panicking. Recovery from cannibalization fixes doesn't happen overnight. Here's what to actually track, and when to expect it.
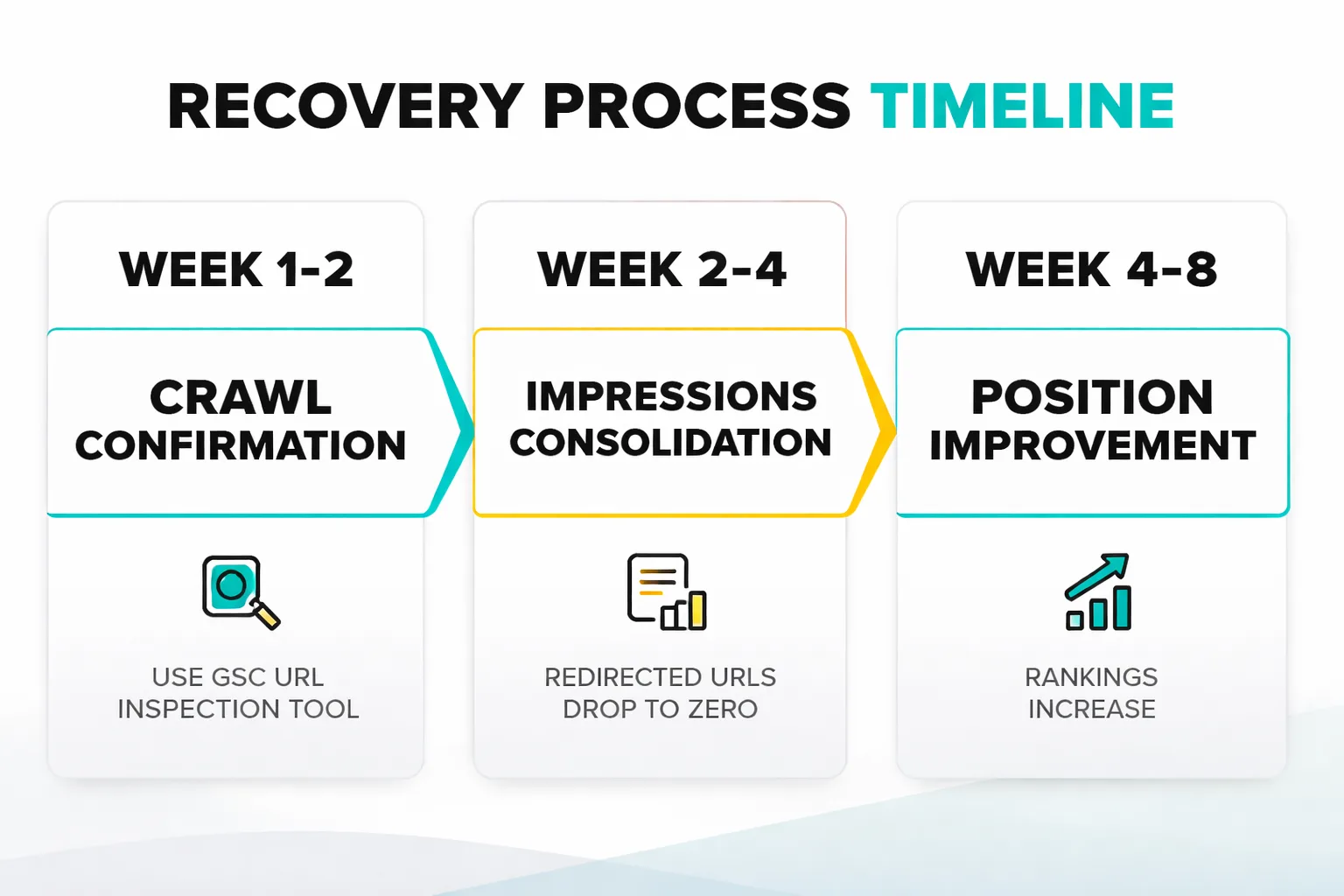
Week 1-2: Crawl confirmation. After implementing a redirect or canonical, verify Google has processed it. Use the URL Inspection tool in GSC to check that the redirected URL now shows the correct canonical. If Googlebot hasn't recrawled the affected pages yet, submit them for indexing manually.
Week 2-4: Impressions consolidation. In GSC, filter by the target query and watch the "Pages" breakdown. Impressions should start consolidating onto the surviving URL. The redirected URL's impressions will drop toward zero. This is a good sign — it means Google is recognizing the redirect.
Week 4-8: Position improvement. This is when ranking movement typically becomes visible. The surviving URL, now receiving consolidated link equity and clearer ranking signals, should start climbing. In my experience, pages that were stuck between positions 8-15 due to cannibalization often move into the top 5 within 6-8 weeks of a clean consolidation.
Week 8-12: Traffic recovery. Organic clicks should follow position improvements. If two pages that were each getting 200 monthly clicks are consolidated into one, I'd expect 280-320 clicks initially, growing toward 400+ as the position stabilizes.
What to do if nothing moves after 12 weeks: revisit the fix. Check that the 301 redirect is implemented correctly (not a 302, not a meta refresh). Verify the canonical is self-referencing on the surviving page. Check whether the surviving page has any technical issues — page speed, mobile usability, or crawl blocks — suppressing recovery. Sometimes the cannibalization fix was right but a separate technical issue is holding the page back.
One metric worth tracking that most guides skip: crawl frequency on the surviving URL. After a consolidation, Googlebot should visit the surviving page more frequently as it accumulates more signals. If crawl frequency drops or stays flat, that's a signal that Google isn't treating the surviving page as the authoritative version yet — and pushing more internal links to it may be necessary.
The realistic timeline is 4-12 weeks. Anyone promising faster results is either working with a very high-authority domain or overselling. Track the right signals, and trust the process.
FAQ
What is keyword cannibalization in SEO?
Keyword cannibalization happens when two or more pages on the same website compete for the same search query, splitting ranking signals like backlinks, clicks, and crawl attention between them. Instead of one strong page ranking well, both pages rank poorly — and Google often alternates between them unpredictably.How do I know if my site has keyword cannibalization?
Open Google Search Console, go to Performance > Queries, click on a target keyword, then switch to the Pages tab. If more than one of your URLs appears with meaningful impressions for the same query, you likely have a cannibalization issue. You can also confirm with asite:yourdomain.com "target keyword" search in Google.