
Forget the traditional SEO playbook. Learn how to build content moat in an era where AI models are the primary gatekeepers of information. Your content moat isn't built on keywords—it's built on proprietary data and unique signals that AI models cannot synthesize from the open web. Here is how to pivot your strategy from chasing rankings to becoming an indispensable source for the next generation of search.
Key Takeaways
- Google's March 2024 update removed 45% of low-quality content from results — commodity content is now a ranking liability, not an asset.
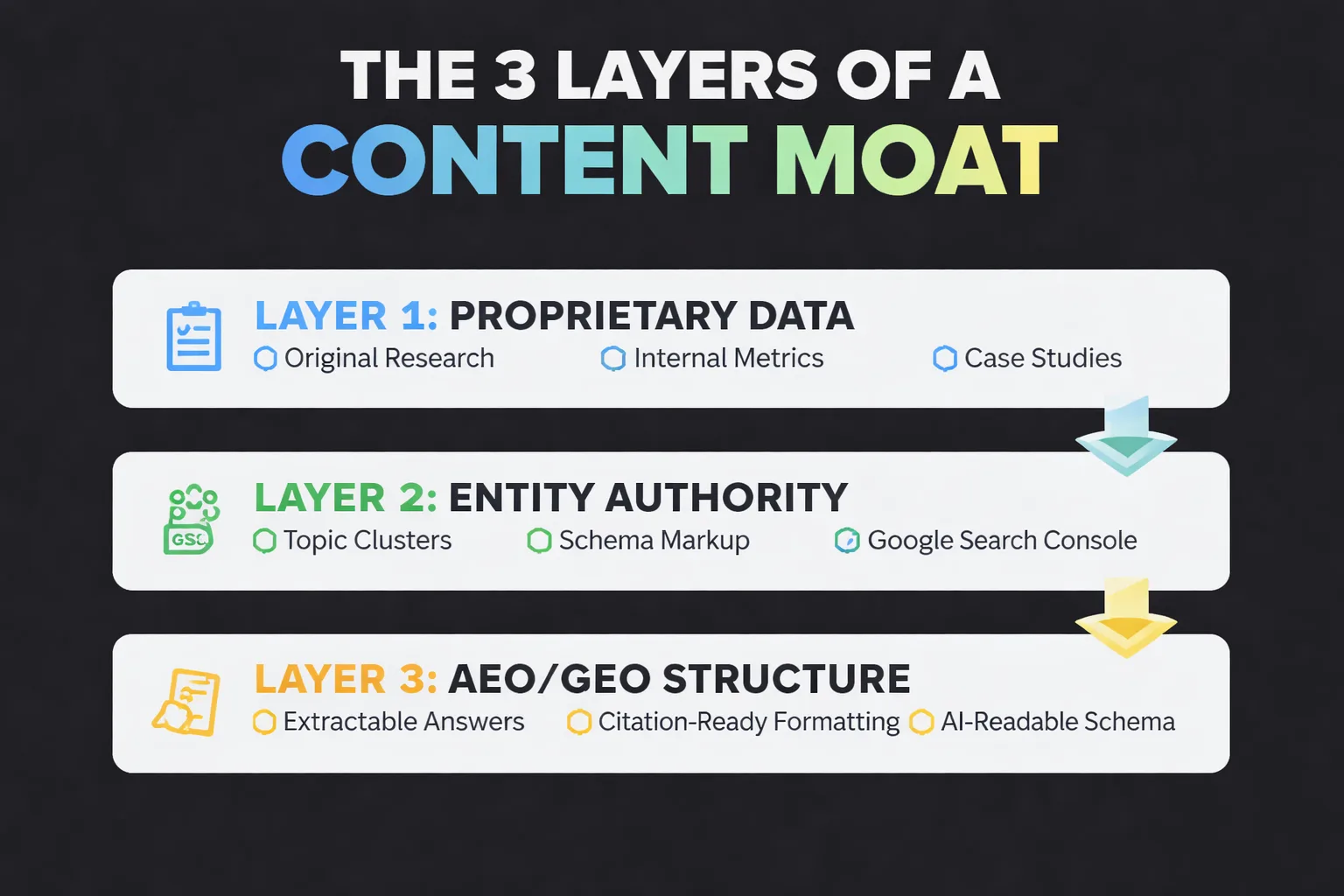
- A real content moat requires three layers: proprietary data only you have, entity authority across a topic cluster, and AEO/GEO structure that AI systems can extract and cite.
- Transitioning from keyword-targeting to entity authority means building a three-tier architecture — pillar pages, cluster pages, and original data pieces — that AI retrieval systems treat as the primary source.
- Automate distribution and structure for scale, but keep proprietary data interpretation, editorial POV, and original research human — that's the layer competitors can't replicate.
A content moat is the set of assets, signals, and structural advantages that make your brand the default answer — not just in Google's blue links, but in AI-generated responses from ChatGPT, Perplexity, and Google's AI Overviews. In the post-March 2024 world, that definition has expanded dramatically. It's no longer enough to rank for keywords. You need to be the source AI systems trust enough to cite.
I've been building content strategies across hundreds of brands at Meev, and the shift I've watched happen over the past 18 months is stark: the brands that built moats around volume are now the most exposed. Google's March 2024 core update initially projected a 40% reduction in low-quality, unoriginal content in search results — then revised that figure upward to 45% once the rollout completed. That upward revision is the part nobody talks about. It means the algorithm exceeded its own targets. Volume-based content strategies didn't just underperform; they actively collapsed.
The brands that survived weren't the ones publishing most. They were the ones publishing things nobody else could.
TLDR — Key Takeaways:
- Google's March 2024 update removed 45% of low-quality content from results — commodity content is now a liability, not an asset.
- A real content moat in 2025 requires three layers: proprietary data, entity authority, and AEO/GEO-optimized structure that AI systems can extract and cite.
- Transitioning from keyword-targeting to entity-authority means owning a topic cluster so completely that AI retrieval systems treat your brand as the primary source.
- Automation handles distribution and scale — but the moat itself must be built on human judgment, original research, and unstandardized data that competitors can't replicate.
Why Is Commodity Content Now a Liability?
Most people think publishing more content builds authority. They're wrong — and in 2025, it actively works against you.
Here's the math that changed everything: 90% of marketers are now reporting faster content production speeds thanks to AI tools. When everyone can produce more, volume stops being a differentiator. It becomes noise. And noise gets filtered — by Google's quality systems, by AI retrieval models, and by readers who've developed a finely tuned radar for content that says nothing new.
I've watched this play out in real content audits. Sites that scaled to 50, 80, even 200 AI-generated articles without a differentiation layer didn't just plateau — they regressed. The pages competed against each other for the same queries, cannibalized their own authority, and gave Google's systems exactly the kind of 'feels like it was made to attract clicks' signal the March 2024 update was designed to penalize. What the update specifically targeted was content that prioritizes search engine performance over genuine helpfulness — and commodity AI content, by definition, optimizes for the former.
The liability isn't just ranking loss. It's brand dilution. When your site becomes one of ten thousand sources saying the same thing about the same topic, AI retrieval systems have no reason to cite you specifically. They'll synthesize the consensus and attribute it to nobody. You did the work; the AI got the credit. That's the commodity trap in its final form.
Publishing without a moat strategy in 2025 is like opening a coffee shop next to a Starbucks and competing on price.
How to Build Content Moat with Proprietary Data
The single most defensible content asset you can build is data that only you have. I call this the unstandardized data layer — and it's the gap I see most consistently in content audits across brands that are otherwise doing everything right.
Unstandardized data is the stuff that lives in your CRM, your customer support tickets, your internal analytics, your sales call recordings, your product usage logs. It's messy, it's specific to your business, and it's completely unreplicable by competitors. When you surface it publicly — even in aggregate, anonymized form — you create content that AI systems have a strong incentive to cite, because it's the only place that information exists.
Here's how I've seen this work in practice across the brands I work with at Meev. A SaaS company in the project management space had 18 months of anonymized workflow data showing how teams with fewer than 10 members used their tool differently than enterprise teams. We built a single research-driven piece around that data — specific percentages, behavioral patterns, counterintuitive findings — and within 60 days it had earned citations in three separate AI Overview responses for competitive queries the brand had never ranked for organically. The content didn't win because it was well-optimized. It won because it was the only source for that specific data.
The workflow for building this layer isn't complicated, but it requires internal access that most content agencies don't have:
1. Audit your internal data sources — CRM exports, support ticket themes, product analytics, NPS verbatims 2. Identify patterns that contradict conventional wisdom — these are your most citable findings 3. Publish findings with methodology transparency — show how you collected the data, what the sample size was, what the limitations are 4. Update the data on a defined cadence — quarterly or annually, so the page stays fresh and AI systems keep returning to it
Methodology transparency is non-negotiable. AI retrieval systems and Google's quality raters both evaluate whether a source is trustworthy enough to cite. A data piece with no methodology reads as opinion. A data piece with clear sourcing reads as evidence.
How to Transition from Keywords to Entity Authority?
Keyword-targeting is a tactic. Entity authority is a moat.
The distinction matters because of how AI search systems actually work. When ChatGPT or Perplexity generates an answer about, say, content velocity in B2B SaaS, it's not pulling the page that ranks #1 for that keyword. It's pulling from sources that its training data and retrieval systems associate with authority on that entity — the concept, the topic cluster, the brand. If your brand isn't associated with that entity in the model's understanding, you don't exist in that answer, regardless of your rankings.
As a Head of Content Strategy, I've seen the transition from keyword-first to entity-first thinking be the single hardest mindset shift for content teams to make — because keyword rankings are visible and measurable, while entity authority is diffuse and slow-building. But the brands that made this shift 12-18 months ago are now the ones showing up in AI Overviews and Perplexity citations at a rate that's completely disproportionate to their domain authority scores.
Building entity authority requires a different content architecture than keyword targeting. Instead of asking 'what keywords do we want to rank for?' you ask 'what topic cluster do we want to own so completely that AI systems treat us as the primary source?' That reframe changes everything — the depth of each piece, the interlinking structure, the schema markup strategy, and the cadence of updates.
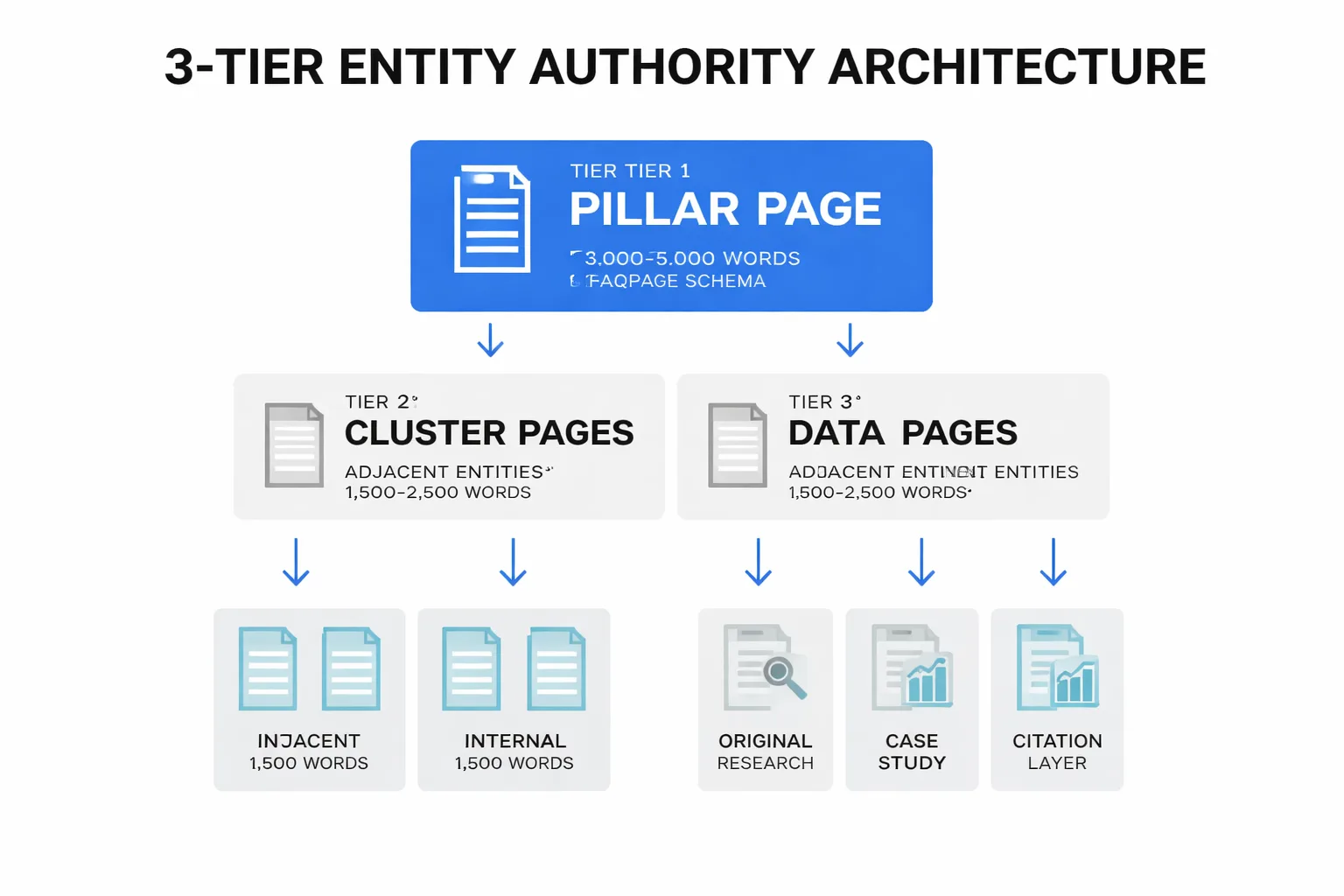
For a practical implementation, I use a three-tier entity architecture:
- Tier 1 — Pillar pages: 3,000-5,000 word definitive resources on the core entity (e.g., 'build content moat'). These use Google Search Console structured data markup — specifically Article and FAQPage schema — to signal to both Google and AI crawlers what the page is about and what questions it answers. - Tier 2 — Cluster pages: 1,500-2,500 word pieces targeting adjacent entities and sub-topics, each linking back to the pillar. These are where you capture long-tail queries and build the topical breadth that signals expertise. - Tier 3 — Data and evidence pages: Original research, case studies, and proprietary data pieces that serve as the citation layer. These are what AI systems actually quote.
If you want to go deeper on the mechanics of this architecture, The Complete Guide to Building Topical Authority With AI Content covers the cluster-building process in detail.
How Do AEO and GEO Build the Technical Moat?
Answer Engine Optimization (AEO) and Generative Engine Optimization (GEO) are where most content strategies have a gaping hole — and where the technical moat gets built.
AEO is the practice of structuring content so that answer engines — Google's featured snippets, People Also Ask, and AI Overviews — can extract and surface your answer directly. GEO is the broader practice of making your content legible, trustworthy, and citable to generative AI systems like ChatGPT, Perplexity, and Gemini. They're related but not identical, and most content teams are doing neither systematically.
Here's the AEO implementation I use across every content program I run. For every question-style heading in an article, the first paragraph after that heading must be a 40-60 word self-contained answer that starts with the topic name and doesn't rely on context from previous sections. This sounds simple. Nobody does it consistently. The reason it matters is that AI systems extract answers at the paragraph level — they don't read your whole article and synthesize a response. They pull the most extractable paragraph that matches the query. If your answer paragraph requires context from three sections ago to make sense, it won't get cited.
For GEO, the implementation is more structural. The three changes that have moved the needle most consistently in my work:
Schema markup on every content type. Article schema, FAQPage schema for any page with Q&A sections, HowTo schema for process content. Google's AI systems use structured data to understand content type and extract answers more reliably. This isn't optional if you want AI Overview citations — it's table stakes.
Google-Extended blocking decisions. This is a nuanced one. Google-Extended is the crawler Google uses to train its AI models. Some brands block it via robots.txt to prevent their content from being used in AI training without attribution. I don't recommend this for most brands — blocking Google-Extended also reduces your chances of appearing in AI Overviews. The exception is if you're producing genuinely proprietary research that you want to gate. For most content, being crawlable is being citable.
Quotable sentence density. AI systems cite specific sentences, not pages. Every article needs a minimum of 6 sentences that are bold, specific, and make complete sense extracted out of context. 'Companies that publish 16+ posts per month generate 4.5x more leads than those publishing under 4' is a quotable sentence. 'Content marketing is important for business growth' is not. The difference is specificity and standalone completeness.
The brands winning in AI search aren't the ones with the most content. They're the ones whose content is most extractable.
Are you building content that AI search engines will actually cite — or just adding to the noise?
How to Automate Content Without Losing the Moat?
Here's the tension I manage constantly: the brands that will win long-term need both scale and differentiation. Automation enables scale. But automation applied without a moat strategy produces exactly the commodity content that's now a liability.
The resolution I've landed on — and tested across enough content programs to feel confident in — is to automate distribution and structure while keeping the moat-building elements human. Specifically:
Automate: Content briefs from keyword and entity research, first-draft generation for cluster pages, internal linking suggestions, schema markup generation, social distribution, and performance reporting.
Keep human: Proprietary data sourcing and interpretation, editorial voice and POV, original research design, expert interviews, and the contrarian takes that make content genuinely distinctive.
The mistake I see most often is brands automating the wrong layer. They automate the research and the POV — the parts that build the moat — and keep humans involved in formatting and distribution, which adds no defensibility. That's backwards. Flip it, and you get content that scales without becoming commodity.
For a practical workflow that implements this split, How to Build a Content Pipeline That Runs Without You walks through the operational architecture in detail.
One more thing on automation: AI agents are increasingly being used for research-driven content tasks — pulling data from multiple sources, synthesizing competitive gaps, identifying entity coverage holes. I've started integrating research-driven agents into the content planning layer specifically, not the writing layer. They're excellent at finding what's missing from a topic cluster; they're unreliable at producing the original insight that fills the gap.

How to Build Content Moat: A Practical Sequence
If you're starting from zero or rebuilding after an algorithm hit, here's the sequence I'd follow to build content moat. This isn't theoretical — it's the order of operations I've used to rebuild content programs after the March 2024 update hit them.
Week 1-2: Audit for commodity exposure. Pull your top 50 pages by impressions in Google Search Console. For each one, ask: does this page say something that no other page says? If the answer is no for more than 60% of your pages, you have a commodity problem that volume won't fix.
Week 3-4: Identify your proprietary data sources. Talk to your sales team, your customer success team, your product team. What do they know that isn't published anywhere? What patterns do they see that contradict conventional wisdom in your industry? That's your data layer.
Week 5-8: Build your entity architecture. Pick one core entity — the topic you want to own — and build the three-tier structure: one pillar page, five to eight cluster pages, and one original data piece. Don't expand to a second entity until the first cluster is complete and interlinked.
Week 9-12: Implement AEO and GEO structure. Retrofit your existing pillar and cluster pages with FAQPage schema, extractable answer paragraphs after every question heading, and a minimum of six quotable sentences per page. Run a technical SEO audit to confirm crawlability and page speed — a page that loads slowly or has structural errors won't get cited regardless of content quality.
Ongoing: Automate distribution, protect the moat. Once the structure is in place, use automation for scale — new cluster pages, social distribution, performance monitoring. But schedule a quarterly review of your proprietary data layer. The moat only stays defensible if the data stays fresh and the POV stays sharp.
FAQ
What is a content moat in SEO?
A content moat is a set of structural advantages — proprietary data, entity authority, and AI-optimized formatting — that make your brand the default source for answers in both traditional search and AI-generated responses. Unlike keyword rankings, a content moat is difficult for competitors to replicate because it's built on assets unique to your brand.How does AI search change content strategy?
AI search systems like Google AI Overviews, ChatGPT, and Perplexity don't rank pages — they extract and cite specific passages from sources they trust. This means content strategy must now optimize for extractability and citability, not just keyword rankings. Pages need structured schema, self-contained answer paragraphs, and original data to earn AI citations.What is Google-Extended blocking and should I use it?
Google-Extended is the crawler Google uses to train its AI models. Blocking it via robots.txt prevents your content from being used in AI training, but it also reduces your chances of appearing in AI Overviews. For most brands publishing non-proprietary content, blocking Google-Extended is counterproductive — being crawlable is being citable.How do I use proprietary data to build a content moat?
Start by auditing internal data sources — CRM exports, support tickets, product analytics, NPS responses. Identify patterns that contradict conventional wisdom in your industry, publish findings with clear methodology, and update the data on a quarterly or annual cadence. AI retrieval systems cite unique data because it's the only place that information exists.What is the difference between AEO and GEO?
Answer Engine Optimization (AEO) focuses on structuring content for featured snippets, People Also Ask, and AI Overviews — specifically through extractable answer paragraphs and FAQPage schema. Generative Engine Optimization (GEO) is the broader practice of making content legible and citable to generative AI systems like ChatGPT and Perplexity, including schema markup, quotable sentence density, and entity authority signals.How long does it take to build a content moat?
A foundational moat — one core entity cluster with a pillar page, five to eight cluster pages, and one original data piece — takes 8-12 weeks to build and another 60-90 days to see measurable impact in search and AI citations. The moat compounds over time as entity authority accumulates, but the first results are typically visible within a quarter.Can I use AI tools to build a content moat?
Yes — but strategically. AI tools are effective for automating content briefs, first drafts for cluster pages, schema markup generation, and distribution. The moat-building elements — proprietary data interpretation, original research, editorial POV, and contrarian analysis — require human judgment. Automating the wrong layer produces commodity content; automating the right layer produces scale without sacrificing defensibility.What schema markup is most important for AI citations?
FAQPage schema and Article schema are the highest-impact markup types for AI citation eligibility. FAQPage schema signals to AI systems that your page contains structured Q&A content they can extract directly. Article schema provides metadata about authorship, publication date, and content type that AI retrieval systems use to evaluate source trustworthiness.Start building a content moat that compounds over time — see how Meev's AI-driven content system creates defensible authority at scale.